Arbres
- Il s'agit de représenter des arbres d'expressions
(arithmétiques ou booléennes)
comme les nombreux exemples vus dans les cours précédents :
- Pour les représenter en C++, nous utilisons une classe
d'arbres binaires dont les étiquettes sont
des chaînes.
- interface
ArbExp.h - implémentation
ArbExp.cpp
Schéma de principe :
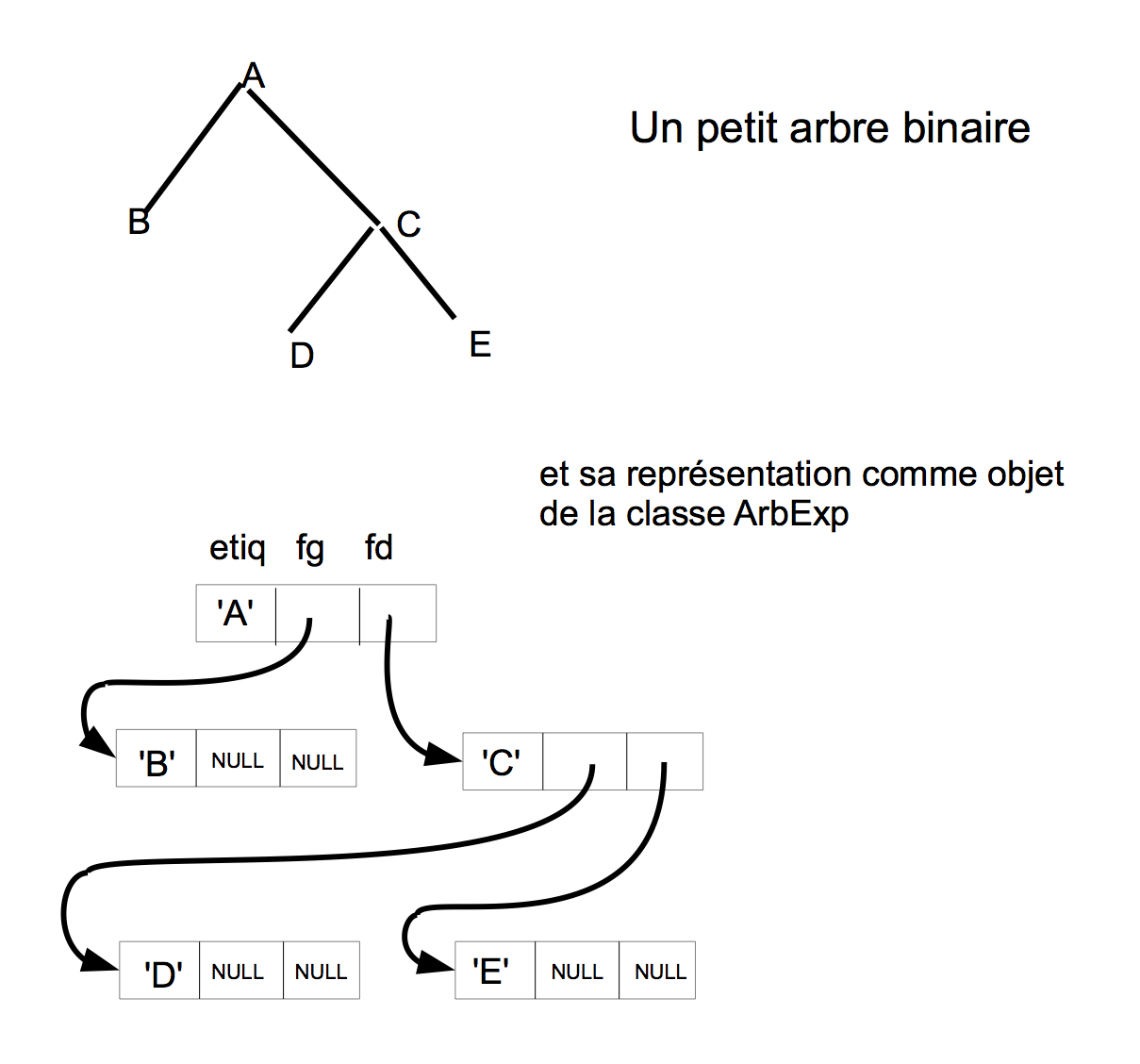
- interface
-
Attention ! en programmation un arbre est un objet logé dans le tas,
connu par un pointeur !
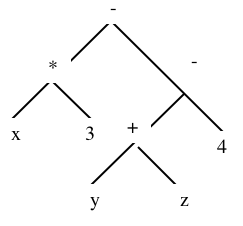
Le premier de nos trois exemples sera donc construit par une séquence d'instructions du genre
ArbExp* a1 = new ArbExp("x");ArbExp* a2 = new ArbExp("3");a1 = new ArbExp ("*", a1, a2);a2 =new ArbExp("y");ArbExp* a3 =new ArbExp("z");a2 = new ArbExp ("+", a2, a3);a3 =new ArbExp("4");a2 = new ArbExp ("-", a2, a3);a1 = new ArbExp ("-", a1, a2);
- On peut appliquer à ces arbres le principe des notations
polonaises, et c'est ainsi que nous les visualiserons,
- tantôt en préfixée :
- * x 3 - + y z 4
obtenu en exécutant "a1->printPref();" après le calcul ci-dessus
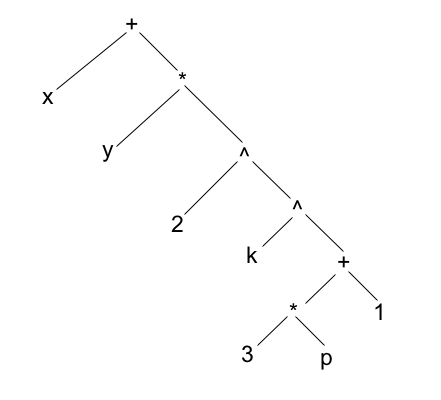
+ + x y * z 2+ x * y ^ 2 ^ k + * 3 p 1
- tantôt en postfixée
x 3 * y z + 4 - -
obtenu en exécutant "a1->printPost();" après le calcul ci-dessus
x y + z 2 * +x y 2 k 3 p * 1 + ^ ^ * +
- tantôt en préfixée :
- Nous utiliserons naturellement la pile de chaînes qui
intervient dans nos parseurs,
et en outre une pile d'arbres (dont les éléments sont de typeArbExp*)
- interface
pilArb.h - implémentation
pilArb.cpp
- interface
Analyse-construction ascendante pour la polonaise postfixée
Réalisation de l'algorithme shift-reduce : à chaque réduction d'une règle correspond un pas de construction de l'arbre.-
Problème
Le problème est d'avoir sous la main toutes les données nécessaires à chaque pas :
- les sous-arbres déjà construits sont dans la pile des
arbres,
- mais l'opérateur, l'entier lu ou le nom de variable a
disparu :
- dans les réalisations des années passées il était
identifié au caractère le représentant, et il se trouvait dans la pile
du parseur ;
- avec notre lexeur, nous n'avons plus dans cette pile que la classe lexicale, non la chaîne de caractères dont nous avons besoin !
- il va falloir ruser...
- dans les réalisations des années passées il était
identifié au caractère le représentant, et il se trouvait dans la pile
du parseur ;
- les sous-arbres déjà construits sont dans la pile des
arbres,
-
Solution
Dans le cas de la polonaise postfixée, (cf. cours précédent, 2ème version du parseur)
- les réductions sont déclenchées par l'apparition en
sommet de pile d'une classe lexicale
(alors que l'autre possibilité, à savoir "l'axiomeSen sommet de pile", provoque toujours un shift). - à ce moment-là, la chaîne du lexème en question a disparu
de la variable
chnLue... - ... car elle vient d'en être chassée par
getNext(). - Il suffit donc de conserver "la chaîne lue au coup d'avant" dans une variable ad hoc pour avoir notre information sous la main.
Nous appelons cette variablederChnLue, et nous faisons précéder chaque appel àgetNext()de sa mise à jour :
l'opération shift se réalise donc ainsi :
p.push(lexLu);
derChnLue = chnLue;
getNext(moTag, leLex, lexLu, chnLue); // on avance
continue;
et les pas de construction de l'arbre s'écrivent (la variablepAcontient la pile des arbres) :
- pour une feuille :
pA.push(new ArbExp (derChnLue)); - pour un nœud :
arbd = pA.top();
pA.pop();
arbg = pA.top();
pA.pop();
pA.push ( new ArbExp (derChnLue, arbg, arbd));
- les réductions sont déclenchées par l'apparition en
sommet de pile d'une classe lexicale
-
Réalisation
Le lexeur est le même que précédemment.
Le parseur se déduit de celui du cours précédent, 2ème version.
Pour montrer qu'il construit bien l'arbre, on envoie comme résultat ce dernier en forme préfixée :
comme, à la fin du calcul, l'arbre construit se trouve seul au sommet de la pile des arbres, cet envoi s'écrit simplement :
pA.top()->printPref();
jfp$ cat po.txt
12 xxx 89+* 678 yyy++
jfp$ ./pp < po.txt
xxx -- cte
xxx -- S
89 -- var S
89 -- S S
+ -- cte S S
+ -- S S S
* -- op S S S
* -- S S
678 -- op S S
678 -- S
yyy -- cte S
yyy -- S S
+ -- var S S
+ -- S S S
+ -- op S S S
+ -- S S
$ -- op S S
$ -- S
OK : 2 3 2 1 1 2 3 1 1
+*12+xxx89+678yyy
Analyse-construction descendante pour la polonaise préfixée
-
Pas de problème...
Le processus descendant de construction de l'arbre est fort différent de celui que nous venons de voir (cf. les notes de cours de 2012).
De plus, le problème relatif à la disponibilité des chaînes de caractères ne se pose pas.
En effet, le principe même de l'analyse descendante veut que
- la prédiction de la règle appliquée se fasse au vu de la classe lexicale qui vient d'être lue,
- et que cette même prédiction se traduise par la mise en place d'un sous-arbre idoine.
Et de fait, dans le cas de la préfixée telle que nous la pratiquons, elle est tout bonnement la valeur de la variablechnLue.
Soulignons qu'il s'agit là d'un résultat structurel, lié à la nature même de l'analyse descendante, et non conjoncturel, lié au cas particulier traité,
comme c'est le cas pour la solution simple que nous avons eu le bonheur de trouver pour la construction ascendante de la postfixée.
Le traitement de la grammaire de Louis nous fera voir clairement la différence !
-
Réalisation
Le lexeur est le même que pour la postfixée.
Le parseur se déduit de celui de l'avant-dernier cours.
Pour montrer qu'il construit bien l'arbre, on envoie comme résultat ce dernier en forme postfixée :
comme,
- à la fin du calcul, la pile des arbres est vide comme la
pile de contrôle,
- l'arbre construit est logé dans une variable nommée
rac, et ce dès le début du calcul
- car il s'agit de son adresse, ne l'oublions pas ! au
début du calcul elle pointe vers un arbre encore vide, qui sera
progressivement rempli...
rac->printPost();
jfp$ cat pr.txt
+* 12+xxx 89+678 yyy
jfp$ ./pp < pr.txt
+ -- S
* -- S S
12 -- S S S
+ -- S S
xxx -- S S S
89 -- S S
+ -- S
678 -- S S
yyy -- S
OK : 1 1 2 1 3 2 1 2 3
12xxx89+*678yyy++
- à la fin du calcul, la pile des arbres est vide comme la
pile de contrôle,
Analyse-construction ascendante pour la grammaire de Louis Lecaillez
Les expressions booléennes décrites par cette grammaire se représentent par les mêmes arbres que le expressions arithmétiques,à condition d'adopter une convention pour adapter l'opérateur unaire au lit de Procuste des arbres binaires :
- le fils gauche prendra en charge l'argument unique
- le fils droit sera
NULL.
-
Problème
Dans cette analyse (cf. avant-dernier cours, 2ème version du parseur) les réductions sont déclenchées par l'apparition en sommet de pile
- soit du lexème
"chn"- auquel cas l'observation faite pour le postfixée s'applique,
c-à-d. la chaîne correspondante est la valeur précédente de la variablechnLue;
- soit du lexème "
pf" (parenthèse fermante), ce qui ne nous informe nullement sur l'opérateur à mettre en place !
Pire, nous savons que ce dernier a été lu juste après la parenthèse ouvrante qui vient de se fermer, il y a peut-être fort longtemps...
En pareil cas, un seul remède ! Il faut gérer une pile...
En vérité, il apparaît clairement que nous aurions besoin que la pile de contrôle du parseur fût une pile de lexèmes et non une pile destring.
Nous adressons donc une demande pressante à l'adresse du cours de C++...
- soit du lexème
-
Solution bricolée
En attendant que les outilleurs nous procurent l'instrument adéquat, nous pouvons adapter la pile destringà nos besoins
en codant les lexèmes sous forme de chaînes : classe lexicale + un blanc + chaîne représentative.
Ainsi, les opérations shift s'écriront :
p.push(lexLu+" "+chnLue);
getNext(moTag, leLex, lexLu, chnLue);
continue;
Pour extraire les informations pertinentes d'une telle chaîne codée, nous définissons deux fonctions d'accès :
string classeLex(string chn){ // à ne pas confondre avec la méthode homonyme de la classe lexeme
return chn.substr (0, chn.find(" "));
}
string chnLex(string chn){ // idem
return chn.substr (chn.find(" ")+1);
}
Détail technique :
- ne pas oublier de modifier en conséquence la procédure
pushST(),
- ce qui exige de placer les définitions nouvelles avant
celle de
pushST().
Moyennant quoi notre parseur s'écrira avec des tests du genreif( classeLex(sp) == "chn" ) { // reduce 3...
- ne pas oublier de modifier en conséquence la procédure
-
Réalisation
Le lexeur est le même que précédemment (analyse ascendante aussi bien que descendante).
Le parseur se déduit de celui du cours précédent, 2ème version.
Pour montrer qu'il construit bien l'arbre, on envoie comme résultat ce dernier en forme préfixée et en forme postfixée :
comme, à la fin du calcul, l'arbre construit se trouve seul au sommet de la pile des arbres, ces envois s'écrivent simplement :
pA.top()->printPref();
pA.top()->printPost();
jfp$ cat e.txt
(~(|| xxx (&& (~ vvv) yyy)) )
jfp$ ./pp < e.txt
~ -- po (
( -- op1 ~ po (
|| -- po ( op1 ~ po (
xxx -- op2 || po ( op1 ~ po (
( -- chn xxx op2 || po ( op1 ~ po (
( -- S op2 || po ( op1 ~ po (
&& -- po ( S op2 || po ( op1 ~ po (
( -- op2 && po ( S op2 || po ( op1 ~ po (
~ -- po ( op2 && po ( S op2 || po ( op1 ~ po (
vvv -- op1 ~ po ( op2 && po ( S op2 || po ( op1 ~ po (
) -- chn vvv op1 ~ po ( op2 && po ( S op2 || po ( op1 ~ po (
) -- T op1 ~ po ( op2 && po ( S op2 || po ( op1 ~ po (
yyy -- pf ) T op1 ~ po ( op2 && po ( S op2 || po ( op1 ~ po (
yyy -- S op2 && po ( S op2 || po ( op1 ~ po (
) -- chn yyy S op2 && po ( S op2 || po ( op1 ~ po (
) -- S S op2 && po ( S op2 || po ( op1 ~ po (
) -- pf ) S S op2 && po ( S op2 || po ( op1 ~ po (
) -- S S op2 || po ( op1 ~ po (
) -- pf ) S S op2 || po ( op1 ~ po (
) -- T op1 ~ po (
$ -- pf ) T op1 ~ po (
$ -- S
OK : 3 3 2 3 1 1 2
~||xxx&&~vvvyyy
xxxvvv~yyy&&||~
Exercices
- Compléter le dispositif 2014 en réalisant la construction de l'arbre
pour la grammaire de Louis par analyse descendante.
-
Réécrire avec la technique FOMA les différents parseurs-constructeurs
que vous trouverez dans le notes de cours des années passées :
- Pour les expressions arithmétiques en notation complètement parenthésée (desc., asc.)
- Pour la polonaise préfixée par analye ascendante
- Pour la notation à deux niveaux de précédence par analye ascendante
- Toujours en analye ascendante, pour l'arbre binaire associé à un système de parenthèses