Première partie
| Définition Étant donné un ensemble fini de mots E, on appelle arbre lexical associé à E un automate fini ainsi conçu :
Questions
|
Exemple ensemble E = { le, leur, lui, ses } Alphabet : { e, i, l, r, s, u }États : { "", l, s, le, lu, se, leu, lui, ses, leur } État initial : "" États terminaux : { le, leur, lui, ses} Transitions
|
- Oui, avec la convention habituelle que toutes les
transitions qui
n'apparaissent pas dans le tableau ont pour but un "état-poubelle",
qui est renvoyé sur lui-même par toutes les lettres de l'alphabet.
Moyennant cette convention, vu la définition, il y a pour chaque état et chaque lettre une transition unique.
On peut même observer que, si on se limite aux transitions écrites dans le tableau, en laissant de côté les transitions vers la "poubelle",
deux transitions différentes aboutissent toujours à deux états différents !
- Le langage reconnu par cet automate est l'ensemble de mots E
lui-même.
En effet, étant donné un mot w sur l'alphabet de l'automate, deux situations peuvent se présenter :
- soit w est un des préfixes de E (au sens large)
- soit ce n'est pas le cas.
- Dans le premier cas, appelons s l'état
correspondant au préfixe w :
cet état n'est pas la "poubelle" (puisqu'il apparaît dans la table), et la lecture du mot w à partir de l'état initial conduit à l'état s
(par préfixes successifs en commençant par "", tout préfixe d'un préfixe étant lui-même préfixe de E).
Le mot w ne sera accepté que si l'état s est terminal, c'est-à-dire si w ∈ E.
- Dans le second cas, le mot w a un préfixe qui est
aussi un préfixe de E, ne serait-ce que le mot vide (qui est préfixe e
tout le monde !).
Soit u le plus long préfixe de w qui est aussi préfixe de E
[dans notre exemple, prenons w = "leurre" : le préfixe le plus long en question est u = "leur"].
Puisque w lui-même n'est pas préfixe de E, cela signifie que u est strictement plus court que w, nous pouvons donc écrire w = uxv
pour une certaine lettrexet un certain suffixe v (peut-être vide).
[dans notre exemple,x= 'r' et v = "e"]
Comme le préfixe u est le plus long possible, son "prolongé" uxn'est plus préfixe de E.
Cela signifie que, si t est l'état de l'automate correspondant au préfixe u, la transition de t parxtombe dans la poubelle !
Et du coup la suite du calcul de w y reste.
[dans notre exemple, c'est le second 'r' qui est fatal]
En somme, dans le second cas, la lecture du mot w à partir de l'état initial conduit à la poubelle, et le mot est donc rejeté.
- Non, cet automate n'est en général pas minimal : tous les
états qui correspondent aux préfixes "non-prolongeables"
- sont terminaux (en tant que mots, il appartiennent à E)
- et ils ont le même avenir : la poubelle.
Dans notre exemple, il s'agit de leur, lui et ses ; il n'y a pas d'autre réduction.
Mais dans d'autres cas on peut aller plus loin : si nous prenons E = {aimer, boire, et, chanter},
non seulement les 4 préfixes maximaux aimer, boire, et, chanter sont équivalents,
mais aussi les préfixes "intermédiaires" aim et chant, ainsi que aime et chante.
Dans quels cas peut-il être minimal ?
D'abord, il doit n'y avoir qu'un seul préfixe non-prolongeable,
c'est à dire que l'ensemble E est composé d'un choix de préfixes d'un même mot.
Par exemple E = {anti, anticonstitution, anticonstitutionnel, anticonstitutionnelle, anticonstitutionnellement}.
Et cela suffit !
Seconde partie
On veut décrire de manière précise la structure des balises ouvrantes en XML.Exemple :
<transition source="0" lettre="x" but="1" >- Une balise ouvrante commence par '<', immédiatement suivi
d'un nom, et se termine par '>',
qui peut être précédé de blancs, de tabulations et même de sauts de ligne.
- Entre le nom et le chevron fermant se trouve une suite (qui
peut être vide) de couples attributs-valeurs formés
- d'un nom
- d'un signe '=' qui peut être entouré de blancs, de tabulations et de sauts de ligne
- d'une valeur placée entre '"'
- Un nom est non-vide, formé de lettres et de chiffres, mais ne
peut pas commencer par un chiffre
- Une valeur est une chaîne qui peut être vide, sans
restriction sur les caractères qui la composent,
y compris blancs, tabulations et sauts de ligne,
mais elle ne doit pas contenir de chevron ouvrant '<'.
Questions
- De quelles classes de caractères avez-vous besoin pour
décrire cette structure ?
Désignez-les par des lettres conventionnelles A, B, C...
Nous aurons besoin de distinguer, outre les caractères indivduels '<', '>', '=' et '"'
- les lettres
L,
- les chiffres
D(comme digit),
- le blanc,
la tabulation et le saut de ligne regroupés sous
S(comme space) - les "autres"
A, pour écrire les valeurs d'attributs, à savoir "n'importe quoi d'autre",
- sauf '<' comme indiqué dans l'énoncé,
- et sauf '"', car la première apparition d'un
guillemet double vient clore le couple attribut-valeur.
- les lettres
- Utilisez ces lettres pour écrire une expression régulière
décrivant le langage des balises ouvrantes.
N.B. Nous employons la barre verticale '|' pour noter la réunion ensembliste, et non le symbole mathématique '∪'.
Procédons par ordre :
- les noms sont décrits par l'exp. reg.
L(L|D)*
- les valeurs d'attributs, entourées de leurs guillemets de
chaîne, par
"(L|D|S|A|=|>)*"
- les couples attribut-valeur, par
L(L|D)*S*=S*"(L|D|S|A|=|>)*"
- Le nom de la balise doit être distinct du nom du premier
attribut,
il y a donc nécessairement au moins un espace (S+) après le premier nom.
- Mais faut-il un espace entre le guillemet fermant une
valeur et le nom de l'attribut suivant ?
Ce n'est pas dit dans l'énoncé !
Expérience faite, oui, il en faut un !
[jean-francois:cours12/Automates/XML] jfp% xmllint Ex1.xml
Ex1.xml:14: parser error : attributes construct error
<transition source="0"lettre="x"but="1" />
^
Ex1.xml:14: parser error : Couldn't find end of Start Tag transition line 14
<transition source="0"lettre="x"but="1" />
^
[jean-francois:cours12/Automates/XML] jfp%
Nous décrirons donc la séquence de couples attribut-valeur par(S+L(L|D)*S*=S*"(L|D|S|A|=|>)*")*.
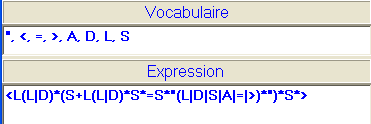
- Par conséquent, l'expression complète est
<L(L|D)*(S+L(L|D)*S*=S*"(L|D|S|A|=|>)*")*S*>.
- les noms sont décrits par l'exp. reg.
- Dessinez un automate fini déterministe reconnaissant ce
langage.
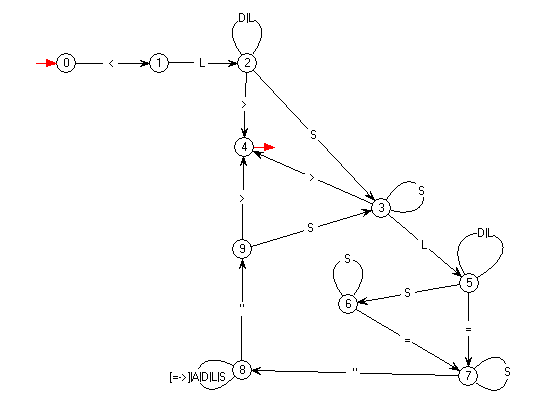
De quels états avons-nous besoin ? Appelons 0, comme d'usage, l'état initial.
Voici schématiquement la succession tout au long de l'expression régulière :
< L (L|D)*(S+ L (L|D)* S* = S* " (L|D|S|A|=|>)*" )* S* >
0 1 2 2 3 5 5 6 7 7 8 8 9 3 4- La seule transition à partir de 0 se fait par '
<', elle va à un nouvel état 1, qui marque "on a lu le '<' initial". - Dans l'état 1 on doit lire la lettre initiale du nom de
la balise : la seule transition à partir de 1 se fait par
L, elle va à un nouvel état 2, qui marque "on a lu l'initiale du nom". - Dans l'état 2, on boucle par
Let parD, pour finir de lire le nom, et on en sort parSou par '>'.
La sortie parSindique la fin du nom, et soit le début d'une liste d'attributs-valeurs, soit un ou plusieursSavant le chevron final.
Elle va donc dans un nouvel état 3, en attente de l'initiale d'un nom d'attribut, ou d'autres S, ou du chevron final.
La sortie par '>' correspond au choix du mot vide simultanément dans les deux étoiles qui suivent le nom de la balise (celle de la liste des attributs-valeurs et celle desSavant le chevron final). Elle conduit tout droit à un nouvel état 4, terminal. - Dans l'état 3, on boucle par
S, on va en 4 par '>' le chevron final, et dans un nouvel état 5 parL, qui est alors l'initiale du nom du premier attribut. - De l'état terminal 4 ne part aucune transition (on a achevé la lecture de la balise).
- Dans l'état 5 on boucle par
Let parD, pour finir de lire le nom de l'attribut courant, et on en sort parSou par '='.
Le comportement de l'état 5 est fort analogue à celui de l'état 2, mais leurs rôles sont évidemment différents (nom d'attribut pour 5, nom de balise pour 2).
Si on sort de 5 parS, c'est pour lire une suite deSen attente de '=', on doit donc aller en un nouvel état 6.
Si on quitte 5 par '=', on va en un nouvel état 7, à partir duquel on lira la valeur de l'attribut dont on vient d'analyser le nom. - Dans l'état 6 on boucle par
S, et on en sort par '=', qui conduit à 7. - Dans l'état 7, on attend le guillemet qui va ouvrir la
valeur, et on boucle par
S. La lecture du guillement fait passer à un nouvel état 8.
- Dans l'état 8 on lit la valeur de l'attribut, en bouclant
par
L,D,S, A, '=' et '>', et en sortant par le guillemet '"' qui clôt la lecture de la valeur.
La sortie par '"' conduit à un nouvel état 9 d'où on partira pour lire soit un nouveau couple attribut-valeur, soit le chevron fermant. - La sortie de 9 par '
>' le chevron final conduit à l'état terminal 4.
L'autre possibilité est unSqui indique soit la suite de la liste d'attributs-valeurs, soit un ou plusieursSavant le chevron final. On est alors exactement dans la même situation que dans l'état 3. Minimalité oblige, on va donc en 3
Voici comment le logiciel automate le dessine :
À titre d'anecdote, on observera que le logiciel en question, prié de construire l'automate à partir de l'expression régulière :
a produit d'abord un automate déterministe à 21 états :
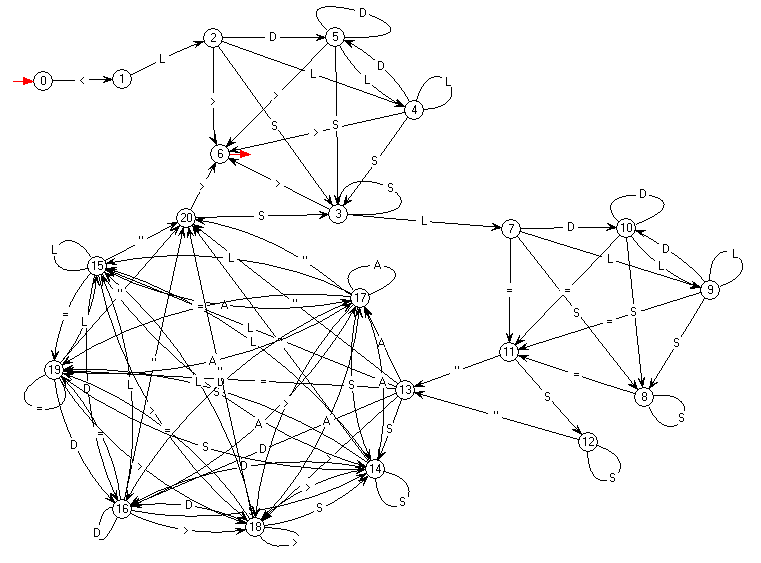
Exercice : vérifier qu'en réduisant cet automate on trouve bien celui qui a été décrit ci-dessus.
Naturellement, si on demande ensuite au logiciel quelle expression régulière il associe à l'automate minimal, il produit une forme assez différente de la nôtre :

Nous ne chercherons pas à prouver que cette expression décrit bien le même langage !
- La seule transition à partir de 0 se fait par '