Première partie
On veut repérer dans un texte en XML les entités-caractères, comme "ø"
ou "æ"qui permettent d'écrire en ASCII pur "
A.P.
Møller-Mærsk" pour signifier "A.P. Møller-Mærsk".
- On s'occupe d'abord de décrire les entités individuellement,
par l'expression "
&#[0-9]+;".
Construire un automate fini déterministe minimal reconnaissant le langage ainsi décrit.
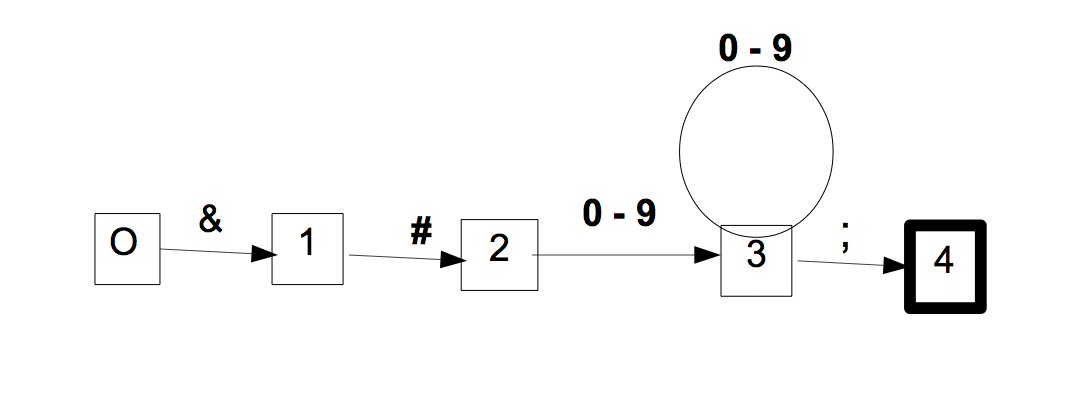
Cet automate aura 5 états (sans compter la poubelle) :
- état initial ;
- après avoir lu '
&' ;
- après avoir lu '
&', puis '#' ;
- après avoir lu '
&', puis '#', puis un premier chiffre décimal (puisqu'il en faut au moins un) ;
on reste dans l'état 3 tant qu'on lit des chiffres ; - après avoir lu '
&', puis '#', puis une suite non-vide de chiffres décimaux, enfin un point-virgule ;
cet état est terminal.
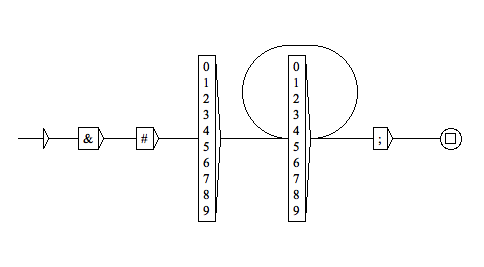
et en voici une autre avec les conventions d'Unitex : une box représente à la fois un état et la transition qui y conduit ;
l'état initial porte une transition vide (sa forme étant celle d'une flèche) ; les états terminaux sont ceux qui sont reliés à la sortie.
Cet autmate est manifestement minimal, car les 5 états ont des "avenirs" différents :
- ne peut accepter que '
&' ;
- ne peut accepter que '
#' ;
- ne peut accepter qu'un chiffre décimal ;
- ne peut accepter qu'un chiffre décimal ou un point-virgule ;
- ne peut accepter personne.
- état initial ;
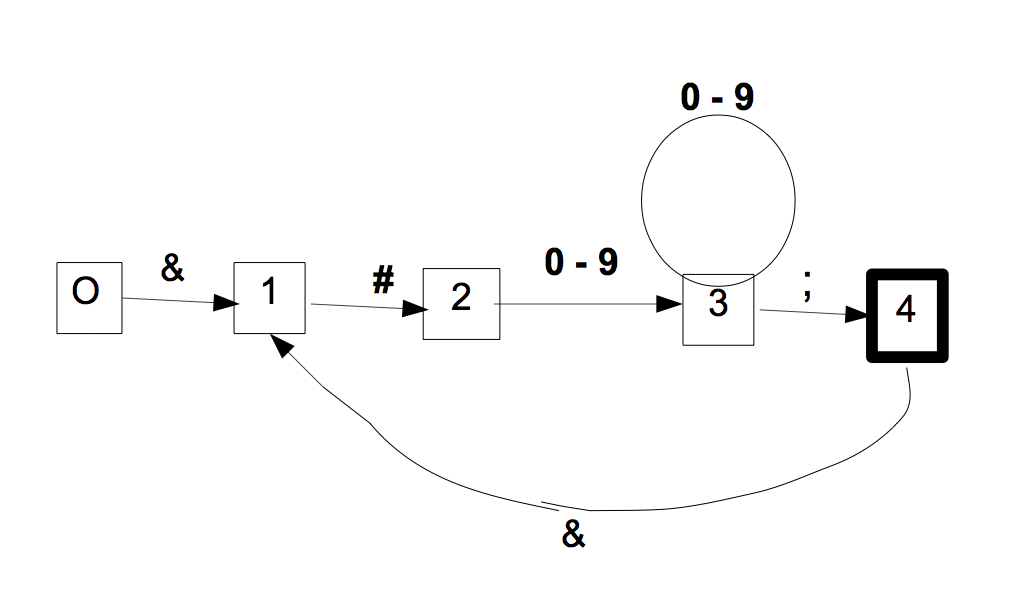
- Déduire de cet automate un automate reconnaissant les
séquences d'entités "
(&#[0-9]+;)+".
Dans l'expression ci-dessus il est spécifié que les séquences à reconnaître sont non-vides.
Il suffit donc d'ajouter dans l'automate précédent une transition de 4 vers 1 par '&', 4 restant l'unique état terminal.
Unitex dessine une image plus élégante :
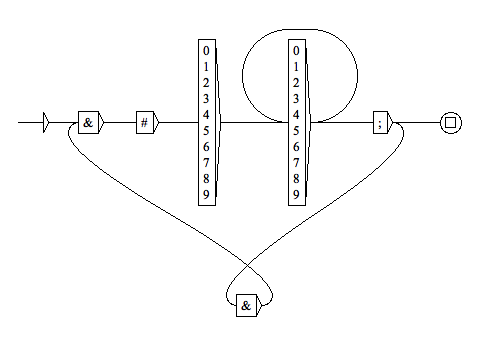
En effet, une suite d'entités se décompose de manière unique en entités individuelles.
L'état de l'automate marquera sa progression dans l'analyse de l'entité courante, quelque soit son rang dans la suite,
on sera dans l'état 4 à la fin de chaque entité.
Cet automate est minimal pour la même raison que le précédent.
La situation aurait été différente si la spécification avait autorisé la chaîne vide (en emplyant l'opérateur '*' au lieu de '+').
Dans ce cas, il aurait fallu que l'état 0 soit aussi terminal (pour accepter la chaîne vide), et l'automate n'aurait plus été minimal,
car les états 0 et 4 auraient eu "le même avenir" (à savoir, le langage lui-même). La réduction aurait confondu ces deux états, pour obtenir :
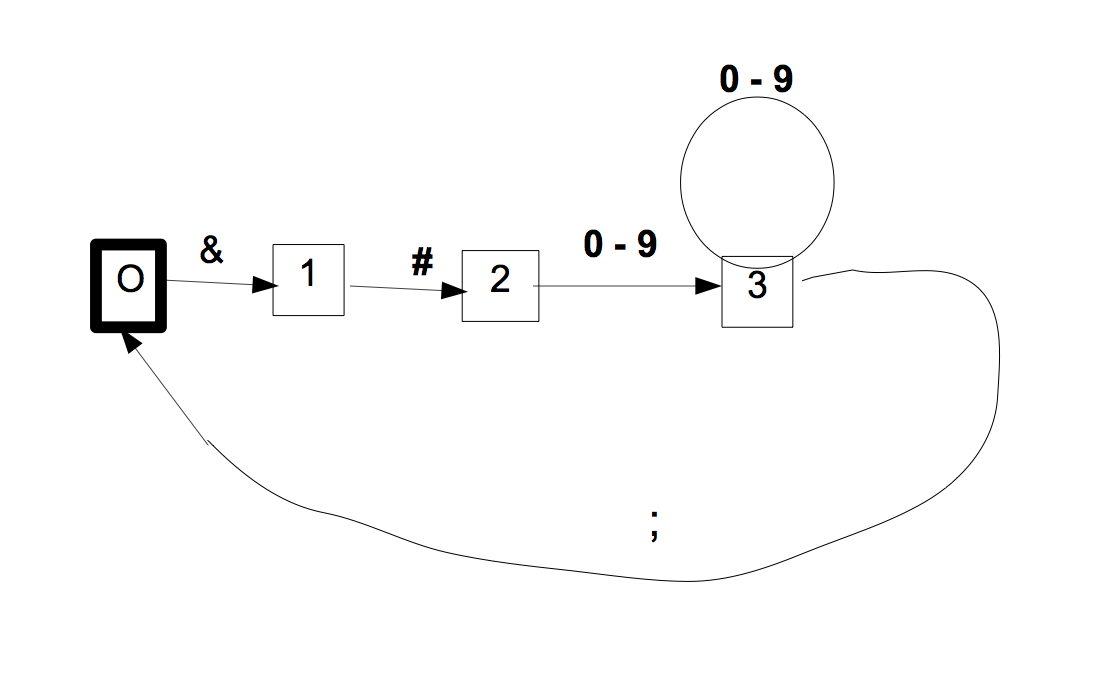
- Dans les séquences acceptées, on souhaite autoriser des
blancs (en quantité variable)
entre les entités.
Comment faut-il écrire l'expression régulière correspondante ?
Comment faut-il modifier l'automate construit en 2. ?
Comme il arrive souvent dans la pratique, la spécification (ici, l'énoncé) est imprécise :
accepte-on aussi des blancs avant toute entité, et après ?
Tout dépend du contexte dans lequel le problème est posé !
Nous adopterons l'interprétation stricte du texte : il est dit entre les entités, ni avant, ni après.
Aussitôt surgit un doute sur le sens précis de blanc : s'agit-il seulement du caractère ASCII n° 32 (octet20),
ou des divers caractères considérés comme blank space, comme le blanc, la tabulation, et les sauts de ligne ?
De nouveau, cela dépend du contexte !
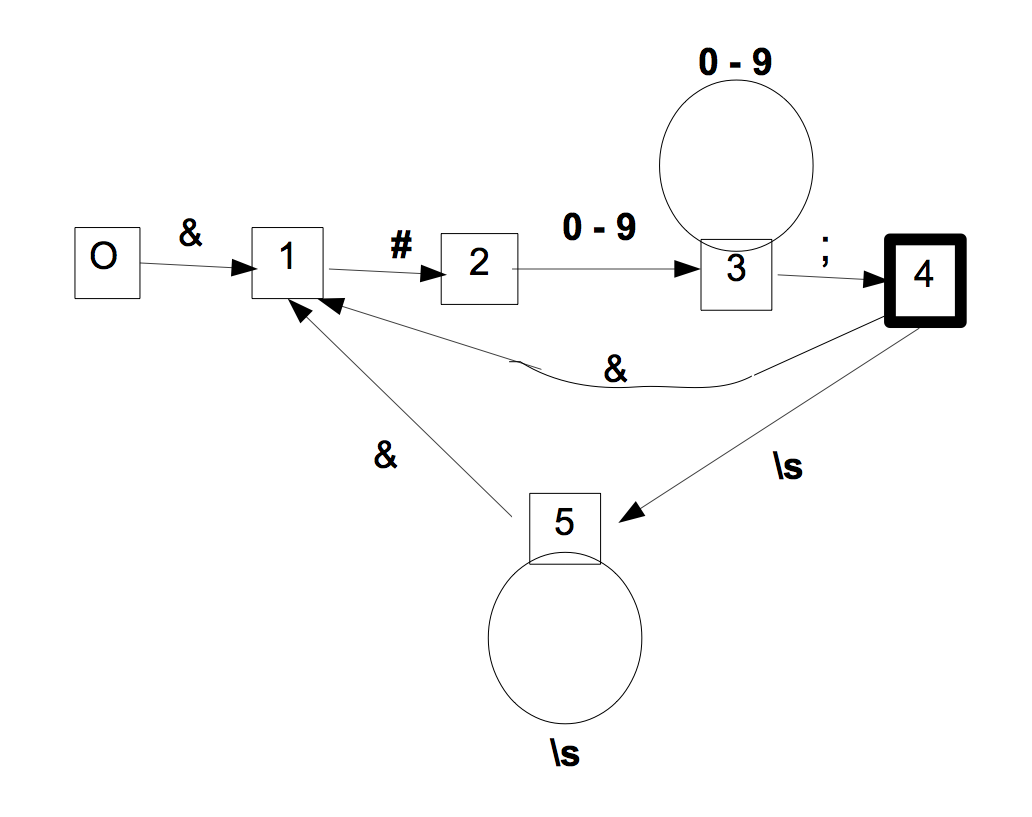
Nous choisirons ici l'interprétation large, celle de l'abrévivation standard "\s", en motivant ce choix par un projet :
celui d'extraire d'une page HTML comme celle-ci tout le texte arabe, qui est entièrement écrit en entités décimales
(pour le constater, examinez le texte-source de la page).
Voyez le script Perl qui effectue cette tâche et le résultat de notre extraction.
Si nous appelons E l'expression régulière correspondant à une entité individuelle, E = "&#[0-9]+;",
notre expression est alors "(E\s*)*E" - le E final étant nécessaire pour exclure les blancs après -
c'est-à-dire, sous forme développée "(&#[0-9]+;\s*)*(&#[0-9]+;)".
Dans l'automate, on doit donc dédoubler l'état 4 (terminal) pour boucler sur les blancs.
Seconde partie
On considère le programme C++ ci-joint, écrit à partir d'un automate fini par le procédé décritau cours n°7.
- Dessiner l'automate en question (en précisant l'état initial
et les états terminaux).
Le voici (état initial 0, unique état terminal 5) :
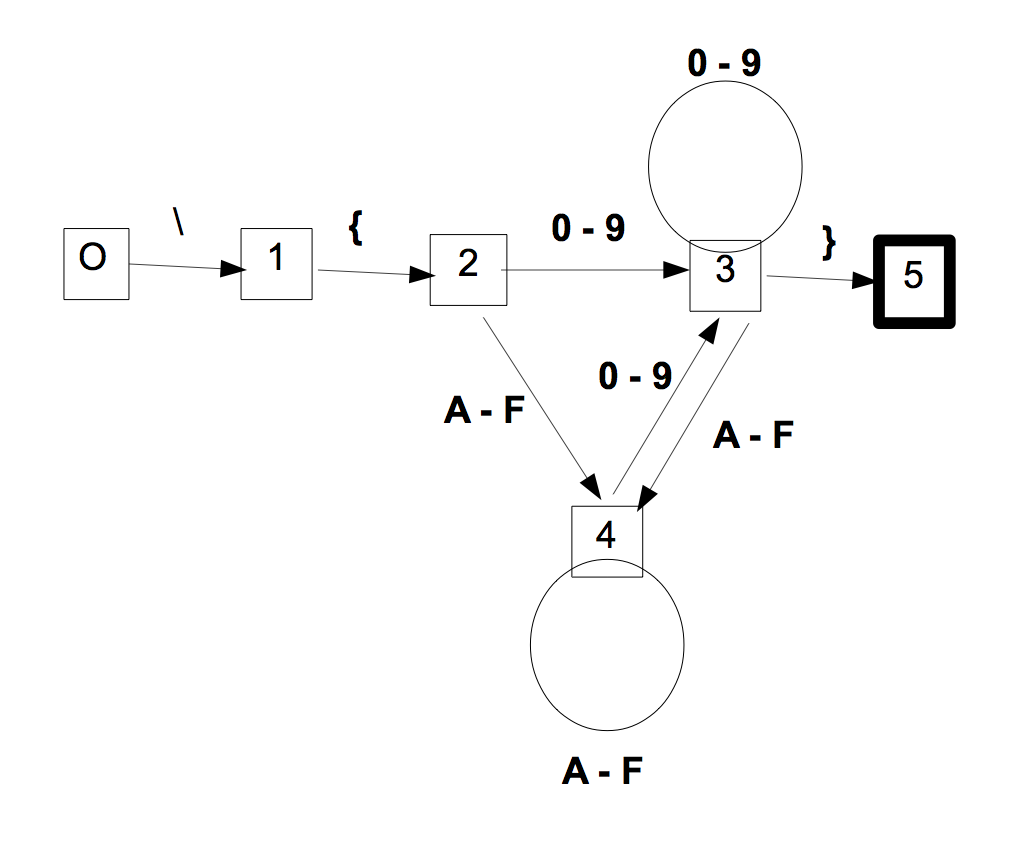
- Cet automate est-il minimal ?
Certes non ! Les états 3 et 4 ont le même avenir, à savoir "[0-9A-F]*}".
On se trouve en 3 ou en 4 selon qu'on vient de lire un chiffre décimal ou un chiffre hexa,
ce qui n'a aucune importance eu égard au but poursuivi...
Sinon, le réduire, et modifier le programme pour qu'il traduise l'automate minimal.
Le voici réduit :
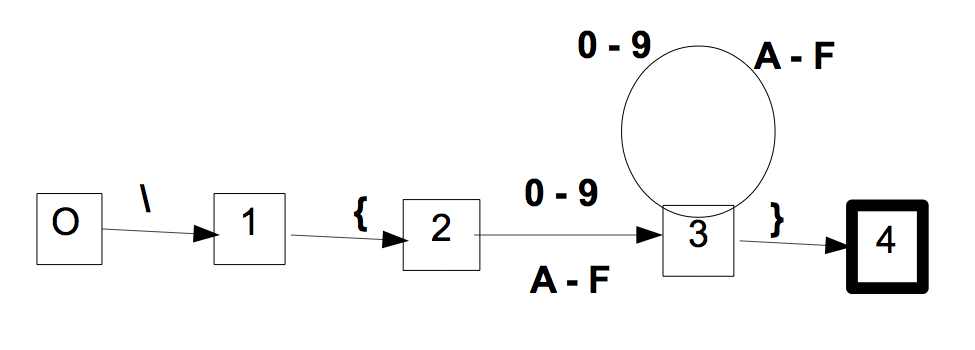
La ressemblance avec l'automate de la question I.1 est frappante...
Et voici le programme correspondant
- Proposer une expression régulière décrivant le langage
reconnu par cet automate.
Appelons L ce langage.
En s'appuyant sur l'analogie des deux automates, on est conduit à l'expression "\{[0-9A-F]+}"
(mais si on veut la faire exécuter par Perl, il faut protéger les accolades,
qui jouent un rôle spécial dans la syntaxe des exp. reg. de Perl : "\\\{[0-9A-F]+\}".
- Comment faut-il modifier le programme pour qu'il accepte L*
?
La question a été traitée dans la première partie du point de vue de l'automate.
Le programme s'en déduit, mutatis mutandis.
Et pour qu'il accepte les séquences de mots de L avec entre eux des blancs
en quantité variable ?
Pour changer, nous adoptons une interprétation du texte large sur les positions (blancs avant, entre et après),
mais stricte sur la nature des blancs (le seul caractère ASCII 32).
Il suffit alors d'ajouter deux instructions au programme précédent : voyez.