Principe : les triplets RDF
-
Triplets
L'élément de base de RDF est l'énoncé d'une relation binaire aRb, où a et b sont les deux termes et R la relation.
Comme on le voit, un tel énoncé prend naturellement la forme d'un triplet (a, R, b).
Les trois composants du triplet portent des noms variables selon le point de vue du locuteur :
- au ras des octets :
le premier terme a sera appelé ressource, la relation R sera vue comme une propriété, et le second terme b sera sa valeur. - en termes philosophiques :
le premier terme a sera appelé sujet, la relation R sera savamment appelée prédicat, et le second terme b sera un objet.
- au ras des octets :
-
Nature des termes
Les deux termes de la relation ne jouent pas des rôles symétriques, ainsi que le laissent entendre les deux terminologies ci-dessus.
- Le premier
terme aura toujours le statut de ressource
: pour une réflexion utile sur l'acception de ce mot dans le cadre du
World Wide Web,
lire Wikipédia.
- Pratiquement, une ressource sera désignée par une chaîne de caractères qui aura le statut exorbitant d'URI.
- On envisage aussi, dans le cadre de RDF,
des ressources
anonymes.
- Le second terme sera
- soit une ressource (éventuellement
anonyme),
- soit un littéral - c'est-à-dire une
chaîne de caractères banale, sans statut privilégié.
Cette chaîne pourra être assortie d'un type de données (datatype), p. ex. pour dire que c'est un nombre.
- soit une ressource (éventuellement
anonyme),
- Quant à la relation, qui est une entité d'une
tout
autre nature (cf. en logique, la différence entre le 1er ordre et le
2ème ordre),
on admet froidement qu'elle sera désignée, elle aussi, par une URI...
- Disons sans plus attendre que cette URL fera le plus
souvent partie
d'un vocabulaire plus ou moins publiquement reconnu,
- comme Dublin
Core (ou DCMI = Dublin Core Metadata
Initiative)
http://purl.org/dc/elements/1.1/ - ou FOAF (Friend of a Friend)
http://xmlns.com/foaf/0.1/
- comme Dublin
Core (ou DCMI = Dublin Core Metadata
Initiative)
- Ce vocabulaire pourra évoluer vers une
organisation hiérarchique appelée ontologie (c'est le cas de
FOAF)
- Disons sans plus attendre que cette URL fera le plus
souvent partie
d'un vocabulaire plus ou moins publiquement reconnu,
- Le premier
terme aura toujours le statut de ressource
: pour une réflexion utile sur l'acception de ce mot dans le cadre du
World Wide Web,
-
Exemple
Nous pouvons à présent montrer un premier exemple de triplet RDF, qui énonce que
- un certain John
Smith, vu comme
une ressource : "
http://.../JohnSmith" (premier terme) - a comme nom sur sa carte de visite (relation : précisions ci-après)
- la chaîne de
caractères (banale) "
John Smith".
- l'URI "
http://.../JohnSmith" - et le littéral "
John Smith".
le namespace [voir plus loin] esthttp://www.w3.org/2001/vcard-rdf/3.0. À l'intérieur de cet espace de nommage, alias vocabulaire,
elle porte le nom local "FN" (comme Full Name). Sa désignation complète esthttp://www.w3.org/2001/vcard-rdf/3.0#FN
(et non simplementhttp://www.w3.org/2001/vcard-rdf/3.0:FNcomme on aurait pu croire).
Ce triplet peut être représenté graphiquement ainsi :
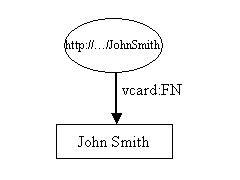
où la notation abrégéevcard:FNrenvoie à une déclarationxmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'.
En notation N3, ce triplet s'écrit :
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://somewhere/JohnSmith> <http://www.w3.org/2001/vcard-rdf/3.0#FN> "John Smith".
ou bien
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix vcard: <http://www.w3.org/2001/vcard-rdf/3.0#> .
<http://somewhere/JohnSmith> vcard:FN "John Smith".
En syntaxe XML, le même triplet s'écrit :
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:about='http://somewhere/JohnSmith'>
<vcard:FN>John Smith</vcard:FN>
</rdf:Description>
</rdf:RDF>
- un certain John
Smith, vu comme
une ressource : "
Ensemble (graphe) de triplets
L'idée est de manipuler des collections de triplets, censées représenter des connaissances.Il pourra arriver qu'une même ressource soit à la fois sujet et objet, qu'un même sujet entre dans plusieurs relations,
ce qui donnera à la collection l'aspect d'un graphe au sens de ce terme en Combinatoire.
-
Suite de l'exemple
le vocabulairevcarddistingue le nom complet (FN= Full Name), dont la valeur est une chaîne de caractères,
et le nom (N= Name), dont la valeur est un objet complexe formé du nom de famille (Family) et du prénom (Given).
Cet agrégat sera représenté en RDF par une ressource anonyme.
D'où un graphe comme celui-ci :
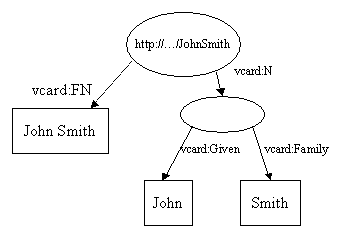
en notation N3
@prefix vcard: <http://www.w3.org/2001/vcard-rdf/3.0#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://somewhere/JohnSmith> vcard:FN "John Smith".
<http://somewhere/JohnSmith>vcard:N [ vcard:Family "Smith" ; vcard:Given "John"] .
ou bien, dans une écriture plus compacte
@prefix vcard: <http://www.w3.org/2001/vcard-rdf/3.0#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://somewhere/JohnSmith>
vcard:FN "John Smith" ;
vcard:N [ vcard:Family "Smith" ; vcard:Given "John"] .
et en XML
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:about='http://somewhere/JohnSmith'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A0">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</rdf:Description>
</rdf:RDF>
-
Un exemple un peu plus fourni
en notation N3 : fichiervcardCat.N3@prefix vcard: <http://www.w3.org/2001/vcard-rdf/3.0#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://somewhere/RebeccaSmith/>
vcard:FN "Becky Smith" ;
vcard:N [ vcard:Family "Smith" ; vcard:Given "Rebecca"] .
<http://somewhere/JohnSmith/>
vcard:FN "John Smith" ;
vcard:N [ vcard:Family "Smith" ; vcard:Given "John"] .
<http://somewhere/SarahJones/>
vcard:FN "Sarah Jones" ;
vcard:N [ vcard:Family "Jones" ; vcard:Given "Sarah"] .
<http://somewhere/MattJones/>
vcard:FN "Matt Jones" ;
vcard:N [ vcard:Family "Jones" ; vcard:Given "Matthew"] .
et en XML: fichiervcardCat.rdf
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:nodeID="A0">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>John</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/JohnSmith/'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/SarahJones/'>
<vcard:FN>Sarah Jones</vcard:FN>
<vcard:N rdf:nodeID="A1"/>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/MattJones/'>
<vcard:FN>Matt Jones</vcard:FN>
<vcard:N rdf:nodeID="A2"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A3">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>Rebecca</vcard:Given>
</rdf:Description>
<rdf:Description rdf:nodeID="A1">
<vcard:Family>Jones</vcard:Family>
<vcard:Given>Sarah</vcard:Given>
</rdf:Description>
<rdf:Description rdf:nodeID="A2">
<vcard:Family>Jones</vcard:Family>
<vcard:Given>Matthew</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/RebeccaSmith/'>
<vcard:FN>Becky Smith</vcard:FN>
<vcard:N rdf:nodeID="A3"/>
</rdf:Description>
</rdf:RDF>
-
Outillage
-
Traduction N3 <-> XML
Essayez !
-
Validation
Le W3C met à votre disposition un service de validation :http://www.w3.org/RDF/Validator/
auquel vous pouvez soumettre vos fichiers en RDF-XML (soit par copier-coller, soit en donnant une URL publique).
La validateur vous livrera la liste des triplets (sous forme d'un tableau à 4 colonnes : n°, sujet, prédicat, objet),
et, si vous le demandez, il vous dessinera le graphe correspondant dans le format de votre choix.
Voici par exemple comment il voit les 16 triplets de notrevcardCat.rdf(format "PNG - embedded"):
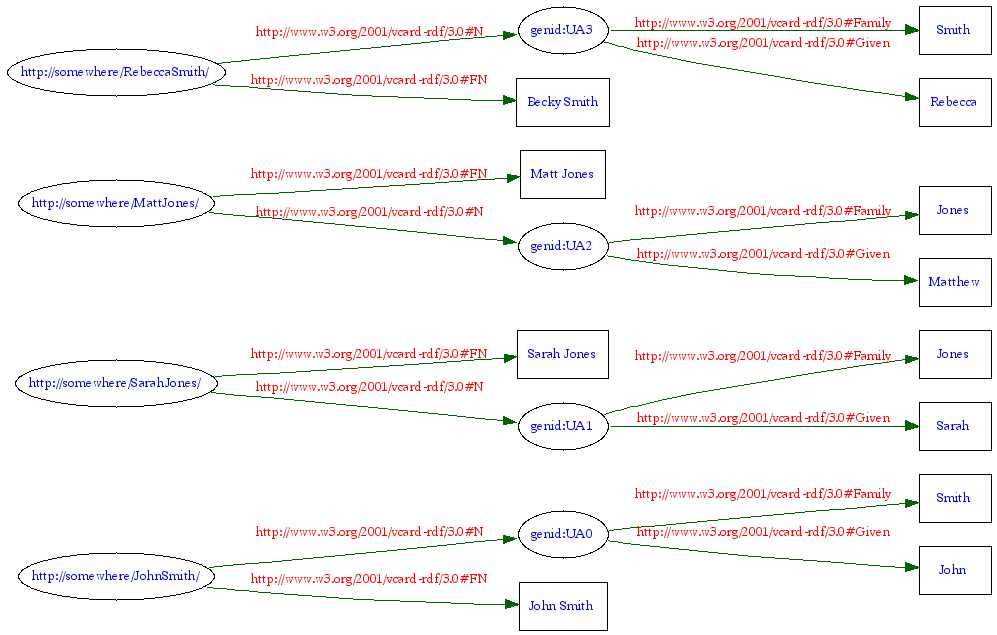
-
Note sur la syntaxe XML
-
Espaces de noms
Nous allons devoir utiliser systématiquement
- l'espace de noms RDF :
http://www.w3.org/1999/02/22-rdf-syntax-ns#
qui interviendra également pour qualifier les attributs.
- différents espaces de noms associés à différents
vocabulaires, parmi lesquels
VCARD(cartes de visite)http://www.w3.org/2001/vcard-rdf/3.0- Dublin Core (ou DCMI = Dublin Core Metadata
Initiative)
http://purl.org/dc/elements/1.1/
- FOAF (Friend of a Friend)
http://xmlns.com/foaf/0.1/
- l'espace de noms RDF :
-
Structure de base
Le triplet élémentaire s'écrit comme un élément<rdf:Description>
- le sujet,
qui est toujours une URL, est donné
comme
valeur de l'attribut
rdf:aboutde cet élément ;
- le prédicat,
qui est aussi une URL, apparaît comme
le nom (balise) d'un
élément-fils de
<rdf:Description>;
- si l'objet
est une chaîne terminale, cette chaîne
apparaît comme le contenu textuel de l'élément-prédicat,
qui est alors une feuille de l'arbre XML ;
lorsque ladite chaîne est typée, son type est donné comme valeur de l'attributrdf:datatypede la balise ;
- si l'objet est une ressource repérée par une URL,
cette URL apparaît
comme
valeur de l'attribut
rdf:resource
de l'élément-prédicat, qui est alors vide.
- si l'objet est une ressource anonyme), voir
ci-après.
- le sujet,
qui est toujours une URL, est donné
comme
valeur de l'attribut
-
Cas des ressources anonymes
Elles sont notées en XML par des noms (uniques à l'échelle du fichier) introduits par l'attributrdf:nodeID
- en position de sujet, pas d'attribut
rdf:about, on écrit directement
<rdf:Description rdf:nodeID="A0">
- en position
d'objet, même écriture de l'attribut
rdf:nodeIDdonné à l'élément-prédicat,
qui est alors un élément vide.
- en position de sujet, pas d'attribut
-
Fragments et URL-base
Il s'agit d'une manière d'écrire commodément des URLs qui font partie d'un même vocabulaire
- On se fixe une
URL de base par la déclaration (par exemple)
xml:base = "http://inalco/M2-Trad/poetes"
qui apparaît comme attribut de l'élément-racinerdf.
- Un fragment est
alors un identificateur qui doit être complété
par l'URL de base pour former un nom de ressource.
Pour être interpété correctement, cet identificateur doit être préfixé par un dièze "#".
- en position
de sujet, il apparaît comme valeur de l'attribut
rdf:aboutdans l'élémentrdf:Description
- en position
d'objet, il apparaît comme valeur de l'attribut
rdf:resourcedonné à l'élément-prédicat,
qui est alors un élément vide.
- en position
de sujet, il apparaît comme valeur de l'attribut
- L'URL complète
est alors l'URL-base concaténée au fragment, avec le dièze interstitiel.
Exemple : (fichierRR.rdf)<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:vc="http://www.w3.org/2001/vcard-rdf/3.0#"
xml:base="http://inalco/M2-Trad/poetes">
<rdf:Description rdf:about="#Messéniennes">
<dc:title>Messéniennes</dc:title>
</rdf:Description>
<rdf:Description rdf:about="#Casimir_DELAVIGNE">
<vc:FN>Casimir DELAVIGNE</vc:FN>
</rdf:Description>
</rdf:RDF>
Traduction du fichier RDF-XMLRR.rdfen RDF-N3
@prefix vc: <http://www.w3.org/2001/vcard-rdf/3.0#> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://inalco/M2-Trad/poetes#Casimir_DELAVIGNE>
vc:FN "Casimir DELAVIGNE" .
<http://inalco/M2-Trad/poetes#Messéniennes>
dc:title "Messéniennes" .
- On se fixe une
URL de base par la déclaration (par exemple)
-
Pour mémoire : Fragments-sujets introduits par
Un fragment en position de sujet peut aussi être donné comme valeur de l'attributrdf:IDrdf:IDdans la baliserdf:Description,
en lieu et place derdf:about.
En ce cas,
- le fragment ne doit pas être préfixé par un dièze,
- il doit apparaître une seule fois dans le fichier
(identificateur unique).
- L'intention qui motive cette syntaxe (construire des
catalogues) ne nous concerne pas.
- Ce procédé est source de confusions et d'erreurs :
le même attributrdf:IDdans la balise-prédicat a une toute autre interprétation (réification d'un triplet) !
- Bien qu'il soit illustré dans le RDF Primer, je
suggère à ma lectrice de ne pas l'utiliser.
-
Utiliser des entités
[Primer : Example 7]
In line 5 of Example 7, a typed literal is given as the value of the exterms:creation-date property element by adding anrdf:datatypeattribute to the element's start-tag to specify the datatype. The value of this attribute is the URIref of the datatype, in this case, the URIref of the XML Schema date datatype. Since this is an attribute value, the URIref must be written out, rather than using the QName abbreviation xsd:date used in the triple.
.....
RDF/XML requires that URIrefs used as attribute values must be written out, rather than abbreviated as a QName. XML entities can be used in RDF/XML to improve readability in such cases
Je ne trouve pas trace de cette exigence dans RDF-SYNTAX...
-
Clause résolutoire
Ce que dit le Primer (fin du § 3.1) :
Although additional abbreviated forms for writing RDF/XML are available, the facilities illustrated so far provide a simple but general way to express graphs in RDF/XML. Using these facilities, an RDF graph is written in RDF/XML as follows:
- All blank nodes are assigned blank node identifiers.
- Each node is
listed in turn as the subject of an
un-nested
rdf:Description element, using an rdf:about attribute if the node has a
URIref, or an rdf:nodeID attribute if the node is blank.
- For each triple
with this node as subject, an appropriate
property
element is created, with
- either
literal content (possibly empty),
- an
rdf:resource attribute specifying the object of the triple (if the
object node has a URIref),
- or an
rdf:nodeID attribute specifying the
object of the triple (if the object node is blank).
- either
literal content (possibly empty),