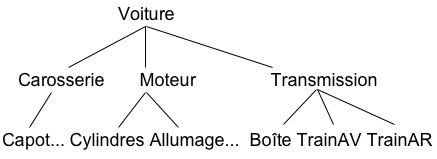
Les
flux RSS
Exemple : fichier Extrait.xml
avec Safari !
<?xml version="1.0" encoding="iso-8859-1"?>
<rss version="2.0" xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<channel>
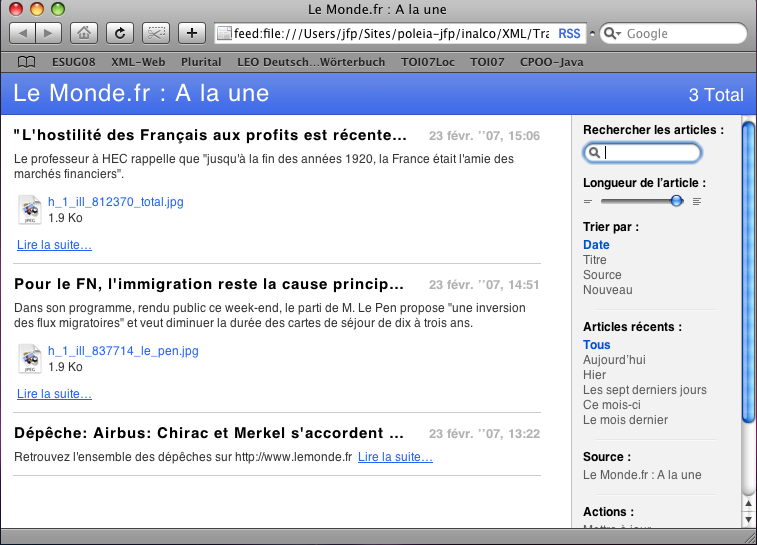
<title>Le Monde.fr : A la une</title>
<link>http://www.lemonde.fr</link>
<description>Toute l'actualité au moment de la connexion</description>
<copyright>Copyright Le Monde.fr</copyright>
<image>
<url>http://medias.lemonde.fr/mmpub/img/lgo/lemondefr_rss.gif</url>
<title>Le Monde.fr</title>
<link>http://www.lemonde.fr</link>
</image>
<pubDate>Fri, 23 Feb 2007 14:38:06 GMT</pubDate>
<item>
<title>
Pour le FN, l'immigration reste la cause principale des problèmes de la France
</title>
<link>
http://www.lemonde.fr/web/article/0,1-0@2-823448,36-875546,0.html?xtor=RSS-3208
</link>
<description>Dans son programme, rendu public ce week-end, le parti
de M. Le Pen propose &#34;une inversion des flux migratoires&#34;
et veut diminuer la durée des cartes de séjour de dix à trois ans.
</description>
<pubDate>Fri, 23 Feb 2007 13:51:01 GMT</pubDate>
<guid isPermaLink="false">
http://www.lemonde.fr/web/article/0,1-0@2-823448,36-875546,0.html?xtor=RSS-3208
</guid>
<enclosure url="http://medias.lemonde.fr/mmpub/edt/ill/2006/11/23/h_1_ill_837714_le_pen.jpg"
type="image/jpeg" length="1923">
</enclosure>
</item>
<item>
<title>"L'hostilité des Français aux profits est récente", selon David Thesmar</title>
<link>http://www.lemonde.fr/web/article/0,1-0@2-3234,36-875560,0.html?xtor=RSS-3208</link>
<description>Le professeur à HEC rappelle que &#34;jusqu&#39;à la fin des années 1920,
la France était l&#39;amie des marchés financiers&#34;.
</description>
<pubDate>Fri, 23 Feb 2007 14:06:50 GMT</pubDate>
<guid isPermaLink="false">
http://www.lemonde.fr/web/article/0,1-0@2-3234,36-875560,0.html?xtor=RSS-3208
</guid>
<enclosure url="http://medias.lemonde.fr/mmpub/edt/ill/2007/02/23/h_1_ill_812370_total.jpg"
type="image/jpeg" length="1968">
</enclosure>
</item>
<!-- autres items -->
<item>
<title>Dépêche: Airbus: Chirac et Merkel s'accordent sur un partage des efforts</title>
<link>http://www.lemonde.fr/web/depeches/0,14-0,39-29881330@7-37,0.html?xtor=RSS-3208</link>
<description>Retrouvez l'ensemble des dépêches sur http://www.lemonde.fr
</description>
<pubDate>Fri, 23 Feb 2007 12:22:10 GMT</pubDate>
<guid isPermaLink="false">
http://www.lemonde.fr/web/depeches/0,14-0,39-29881330@7-37,0.html?xtor=RSS-3208
</guid>
</item>
</channel>
</rss>
Cet extrait provient d'un fichier plus long venant du site du Monde : fichier 0,2-3208,1-0,0.xml.
Contrairement à ce qu'on attendrait, les fichiers RSS (Really
Simple Syndication) ne font pas appel
à un espace de noms spécifique.
La référence à RDF paraît sans conséquence pratique...
Le format minimum d'un Document RSS 2.0 est le
suivant (http://www.rssboard.org/rss-specification):
- L'élément-racine est <rss
version="2.0">.
- La racine a exactement un fils, qui est un élément <channel>.
- Ledit <channel>
possède
d'abord 3 fils :
- un élément <title>,
qui contient du texte,
- un élément <description>,
qui contient du texte,
- un élément <link>,
qui contient aussi du texte (une URL).
- Le <channel>
contient
ensuite un nombre quelconque d'éléments <item>.
- Chaque <item>
possède
au moins un fils, qui peut être
- un élément <title>,
qui contient du texte,
- ou un élément <description>,
qui contient aussi du texte.
Il peut contenir les deux,
et on peut utilement lui ajouter un élément <link>,
qui contient aussi du texte (une URL).
Cette URL sera "cliquable" pour obtenir une forme développée de
l'information donnée par l'<item>.