Principe de DOM
- DOM est un système pour représenter en mémoire centrale le
contenu d'un fichier XML.
Dans cette perpective, un contenu XML est vu comme une totalité immédiatement accessible.
En termes informatiques, c'est un objet.
DOM offre le moyen
- de construire (en mémoire) l'objet correspondant
à un fichier XML (sur disque)
par une opération d'analyse syntaxique (parsing) effectuée par un parseur. - de manipuler par programme un tel objet XML en
mémoire
- lecture
- modification
- construction
- d'écrire dans un fichier le texte XML correpondant à un objet en mémoire.
- de construire (en mémoire) l'objet correspondant
à un fichier XML (sur disque)
- DOM offre un cadre abstrait pour décrire et effectuer les
opérations ci-dessus.
Ce cadre se réalise dans divers langages de programmation, en utilisant de manière essentielle la notion informatique d'objet
qui est à peu près la même dans tous les langages.
La manière de programmer avec DOM est donc grosso modo la même en Java, en C++, en PHP-5 et en Perl.
Dans ce cours nous utiliserons Perl et plus particulièrement le module XML::DOM.
Pour un exposé plus détaillé, avec Java & PHP-5, voir ici.
- Du point de vue de l'utilisateur, DOM se présente comme la
technique fondamentale pour toute espèce de travail sur des documents
XML.
D'autres techniques existent, mieux adaptées à différentes applications (XPath, XSLT notamment).
DOM permet de traiter tous les problèmes, en adoptant un point de vue global.
Une seule contre-indication : les très gros fichiers, qui conduisent à une occupation excessive de la mémoire centrale.
La triade Document,
Element, Texte
-
Le document XML, sa totalité, ses parties
- L'objet associé à un fichier XML est unique mais
complexe.
Dans la terminologie DOM on l'appelle unDocument,
au sens de cet objet appartient à l'espèceDocument.
- Les multiples parties de cet objet sont aussi des
objets,
qui appartiennent à plusieurs espèces différentes.
Deux de ces espèces méritent notre attention :
Element: c'est l'espèce des sommets de l'arbre qui correspondent aux balises dans le texte XML.
UnElementpossède un nom (celui de la balise), des attributs et des enfants.
LeDocumentcontient unElementparticulier qui est la racine de l'arbre XML
Text: c'est l'espèce des objets qui représentent les contenus textuels qui apparaissent entre les balises.
Dans le système DOM, ces contenus sont représentés comme des objets à part entière.
UnTextsera toujours enfant d'unElement, tandis que lui-même n'aura ni attribut ni enfant,
mais on pourra lui demander de livrer la chaîne de caractères qu'il contient.
Voiture.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/css" href="Voiture.css"?>
<!DOCTYPE Voiture SYSTEM "Voiture.dtd" >
<Voiture marque="Renault" modèle="Safrane">
<Carosserie couleur="rouge">
<Capot>Un peu cabossé</Capot>
</Carosserie>
<Moteur>
<Cylindres />
<Allumage>Défectueux</Allumage>
</Moteur>
<Transmission type="automatique" nb_vitesses="5">
<Boîte />
<TrainAV />
<TrainAR />
</Transmission>
</Voiture>
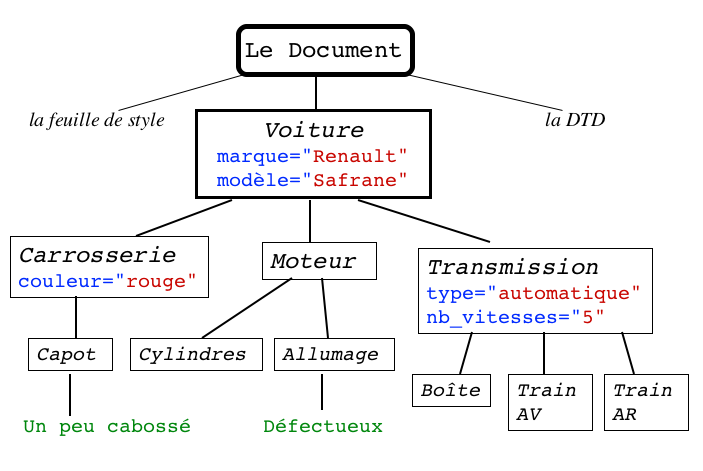
Il y a un seulDocument, 10Elements et 2Texts.
Du moins c'est ce que nous croyons à la lecture du fichier.
Comme on verra plus loin, la réalité est un peu différente...
- L'objet associé à un fichier XML est unique mais
complexe.
-
L'objet
Document.- Il est souvent créé par le parseur à partir d'un fichier
XML.
En Perl :
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile("Voiture.xml");
- Il livre l'
Element-racine par la méthodegetDocumentElement()
my $voiture = $doc->getDocumentElement();
- Il est souvent créé par le parseur à partir d'un fichier
XML.
-
Traitement d'un objet
Element.- Accès à son nom (comme chaîne de caractères) par la
méthode
getNodeName()
my $nom =$voiture->getNodeName();
- Accès aux valeurs de ses attributs, connaissant leurs
noms :
getAttribute(le-nom)
my $marque = $voiture->getAttribute("marque");
my $modele = $voiture->getAttribute("mod\x{00E8}le");
- Accès à la liste de ses enfants par
getChildNodes()
my @cmt = $voiture->getChildNodes();
foreach my $enf ( @cmt ){
print ($enf->getNodeName());
}
- Attention !
getChildNodes()nous donne tous les enfants de l'Elementconcerné.
Notamment tous les contenus textuels qu'on y a introduits pour rendre le fichier lisible :
les indentations, les blancs et les sauts de ligne sont considérés par DOM comme des textes !!!!...
Dans notre fichier-exemple, chaqueElementest entouré par deux objetsText.La boucle ci-dessus donne :
#text Carosserie #text Moteur #text Transmission #text
- Accès à son nom (comme chaîne de caractères) par la
méthode
-
Traitement d'un objet
Text.- Attention ! Un objet
Textn'est pas une chaîne de caractères !
UnTextest une "boîte" qui contient une chaîne.
C'est cette boite qu'on obtient comme enfant de la balise...
- Il faut lui demander
getData()pour avoir la chaîne.
- Cas d'une "feuille" :
Elementne contenant que du texte (commeCapotetAllumagedans l'exemple ci-dessus)
L'objetTextest alors son unique enfant, on l'obtient directement pargetFirstChild().
my $carosserie = $cmt[1]; # après l'indentation
my @caps = $carosserie->getChildNodes();
my $capot = $caps[1]; # idem
my $txt = $capot->getFirstChild(); # capot est une feuille
my $chn = $txt->getData();
- Attention ! Un objet
-
Intégration
Mise en œuvre minimale de tout ce que nous venons de voir : fichiervoiture1.pl
use strict;
use warnings;
use XML::DOM;
# le fichier sera lu automatiquement en UTF-8,
# on prépare les impressions sur la sortie standard
binmode(STDOUT, ":utf8");
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile("Voiture.xml");
my $voiture = $doc->getDocumentElement();
my $nom = $voiture->getTagName();
print("$nom\n");
my $marque = $voiture->getAttribute("marque");
my $modele = $voiture->getAttribute("mod\x{00E8}le");
print("$marque $modele\n");
my @cmt = $voiture->getChildNodes();
foreach my $enf ( @cmt ){
print ($enf->getNodeName());
print(" ");
}
print("\n");
my $carosserie = $cmt[1]; # après le saut de ligne
my @caps = $carosserie->getChildNodes();
foreach my $cap ( @caps ){
print ($cap->getNodeName());
print(" ");
}
print("\n");
my $capot = $caps[1]; # idem
my $txt = $capot->getFirstChild(); # capot est une feuille
my $chn = $txt->getData();
print("$chn\n");
Exécution :
jfp% perl voiture1.pl
Voiture
Renault Safrane
#text Carosserie #text Moteur #text Transmission #text
#text Capot #text
Un peu cabossé
jfp%
Savoir à qui on s'adresse
-
Le genre
Les trois espèces d'objetsNodeDocument,ElementetTextappartiennent toutes au même genre, appeléNode.
(Le mot genre est pris ici au sens de la classfication linnéenne des êtres vivants, non au sens de la sémantique textuelle :
famille > genre > espèce. Par exemple Orchidées [ Orchidaceae] > Dactylorhiza > Orchis tacheté [Dactylorhiza maculata].)
La liste fournie pargetChildNodes()est une liste de d'objetsNode, contenant aussi bien desElementque desText.
Or, on ne peut pas s'adresser de la même manière à unElementet à unText!
On ne peut pas demandergetData()à unElement, nigetAttribute(...)à unText...
Comment savoir à qui on s'adresse ?
-
La méthode
Pour ungetNodeName()peut être demandée à toute espèce deNode.Elementelle renvoie son nom, pour unTextelle renvoie la chaîne fixe "#text".
[Cette chaîne ne peut pas être un nom, le caractère '#' est interdit dans une balise.]
Elle nous fournit donc un moyen de discrimination.
Notez que la même question peut se formulergetTagName()pour unElementseulement.
(Il est souvent utile d'être rigoureux : mieux vaut une erreur à l'exécution qu'un résultat aberrant !)
Nous pouvons donc réécrire la boucle de tout à l'heure :
foreach my $enf ( @cmt ){
if(getNodeName()ne '#text' ){
print ($enf->getTagName());
}else{
print ($enf->getData());
}
}
-
Éliminer les parasites (indentations, etc)
Notre aventure avec le fichierVoiture.xmlnous suggère de mettre à part les objetsTexts parasites
produits par la mise en forme du fichier.
Ces objets sont caractérisés par leur contenu qui ne comporte que des blancs, des tabulations et des sauts de ligne.
La fonction Perl suivante, appliquée à un objetNode, va répondre vrai si cet objet n'est pas unTextparasite.
sub nonVide($){ # arg. Node
my ($node) = @_;
return ($node->getNodeName() ne '#text') || ($node->getData() !~ /^\s*/$);
}
Mise en œuvre, sachant que tous les enfants non-parasites de l'Element$voituresont bien desElements :
my @cmt = $voiture->getChildNodes();
foreach my $enf ( @cmt ){
if( nonVide($enf) ){
print ($enf->getTagName());
}
}
-
Un autre mode d'accès :
Si la structure du document XML est connue, ce qui est fréquent (les DTDs sont là pour ça !),getElementsByTagName(un-nom)
on peut employer une autre méthode pour accéder à coup sûr aux bonsElements :
demandé à unElementou à unDocument,getElementsByTagName(un-nom)va renvoyer
- la liste de tous ses descendants (directs et indirects)
- qui sont des
Elements et portent le nom passé en paramètre - dans l'ordre de parcours "préordre" (de gauche à droite,
en profondeur).
Si, comme le cas se présente souvent, lesElements de même nom sont tous des successeurs d'un même sommet,
cette méthode est bien adaptée. Nous en verrons des exemples plus loin.
Si au contraire chaque nom correspond à un enfant unique, on l'obtiendra en indexant la liste.
Pour assurer que l'évaluation se produit en contexte de liste, on utilisera la forme filtrante :
my ($var) = $l-element->getElementsByTagName(un-nom);
Par exemple :
my ($capot) = $voiture->getElementsByTagName("Capot");
Ce mode d'accès est excellent lorsqu'on connaît la structure (DTD) du document XML,
et que cette structure est bien adaptée au but poursuivi. Nous allons l'illustrer dans une première famille d'exemples.
Dans le cas contraire, il faudra revenir àgetChildNodes, et à un parcours attentif à la nature des enfants,
comme nous le verrons dans une seconde famille d'exemples.
-
Intégration
Mise en œuvre minimale de tout ce que nous venons de voir : fichiervoiture2.pl
use strict;
use warnings;
use XML::DOM;
binmode(STDOUT, ":utf8");
sub nonVide($){ # arg. Node
my ($node) = @_;
return ($node->getNodeName() ne '#text') || ($node->getData() !~ /^\s*$/);
}
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile("Voiture.xml");
my $voiture = $doc->getDocumentElement();
my $nom = $voiture->getTagName();
print("$nom\n");
my $marque = $voiture->getAttribute("marque");
my $modele = $voiture->getAttribute("mod\x{00E8}le");
print("$marque $modele\n");
my @cmt = $voiture->getChildNodes();
foreach my $enf ( @cmt ){
if( nonVide($enf) ){
print ($enf->getTagName());
print(" ");
}
}
print("\n");
my ($capot) = $voiture->getElementsByTagName("Capot");
my $chn = $capot->getFirstChild()->getData(); # abrégeons !
print("Capot : $chn\n");
Exécution :
jfp% perl voiture2.pl
Voiture
Renault Safrane
Carosserie Moteur Transmission
Capot : Un peu cabossé
jfp%
Exemples-1
Utilisation de getElementsByTagName(...) sur des
documents bien structurés.
-
Exploitation d'un fichier de noms & notes (représentation par attributs)
Exemple : fichierEx1.xml
<?xml version="1.0" ?>
<liste>
<eleve nom="Pierre" note="12"/>
<eleve nom="Paul" note="13"/>
<eleve nom="Jacques" note="17"/>
</liste>
On lit le document en imprimant les noms & notes, et en même temps on calcule la moyenne
fichierLire_1.pl
use strict;
use warnings;
use XML::DOM;
sub lire_1 ($) { #Document -> flottant
my ($doc) = @_;
my $liste = $doc->getDocumentElement();
my $k = 0; #nombre de notes
my $s = 0; #le total des notes
my @les_eleves = $liste->getElementsByTagName("eleve");
foreach my $l_eleve ( @les_eleves ){
#lecture
my $le_nom = $l_eleve->getAttribute("nom");
my $la_note = $l_eleve->getAttribute("note");
#action
print("$le_nom a pour note $la_note\n");
$s += $la_note;
$k++;
}# foreach
if( $k == 0 ){
die("fichier vide");
}else{
return $s/$k;
}
}# lire_1
sub lecture ($){# nom de fichier
my ($fichIn) = @_;
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile($fichIn);
my $moy = lire_1($doc);
print("\nMoyenne : $moy\n");
}#lecture
lecture($ARGV[0]);
Exécution :
jfp% perl Lire_1.pl Ex1.xml
Pierre a pour note 12
Paul a pour note 13
Jacques a pour note 17
Moyenne : 14
jfp%
-
Même chose en représentation par enfants
Exemple : fichierEx2.xml<?xml version="1.0" ?>
<liste>
<eleve>
<nom> Toto</nom> <note> 12 </note>
</eleve>
<eleve>
<nom> Tata</nom> <note> 13 </note>
</eleve>
<eleve>
<nom> Tutu</nom> <note> 17 </note>
</eleve>
</liste>
Le programme est le même que ci-dessus, sauf la phase de "lecture" qui devient plus compliquée.
On note au passage que le nombre d'élèves peut être connu directement (c'est la longueur de la liste)
au lieu d'être calculé au cours de la boucle.
Mettons cette remarque en pratique...
fichierLire_2.pl
use strict;
use warnings;
use XML::DOM;
sub lire_2 ($) { #Document -> flottant
my ($doc) = @_;
my $liste = $doc->getDocumentElement();
my $s = 0; #le total des notes
my @les_eleves = $liste->getElementsByTagName("eleve");
my $k = @les_eleves; # longueur de la liste (évaluation "en contexte scalaire")
foreach my $l_eleve ( @les_eleves ){
#lecture
my ($elt_nom) = $l_eleve->getElementsByTagName("nom");
my $le_nom = $elt_nom->getFirstChild()->getData();
my ($elt_note) = $l_eleve->getElementsByTagName("note");
my $la_note = $elt_note->getFirstChild()->getData();
#action
print("$le_nom a pour note $la_note\n");
$s += $la_note;
}# foreach
if( $k == 0 ){
die("fichier vide");
}else{
return $s/$k;
}
}# lire_2
sub lecture ($){# nom de fichier
my ($fichIn) = @_;
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile($fichIn);
my $moy = lire_2($doc);
print("\nMoyenne : $moy\n");
}#lecture
lecture($ARGV[0]);
Exécution : pourquoi les noms sont-ils "indentés" ?
jfp% perl Lire_2.pl Ex2.xml
Toto a pour note 12
Tata a pour note 13
Tutu a pour note 17
Moyenne : 14
jfp%
-
Extraire le poème de Pablo Neruda de son "enveloppe XML"
On veut se laisser un maximum de liberté dans les choix typographiques.
La réalisation que voici produit du HTML.
fichierNeruda.pl
use strict;
use warnings;
use XML::DOM;
# La structure
sub printPoema($){ #arg. Element "poema"
my ($poema) = @_;
my ($titre) = $poema->getElementsByTagName("t\x{00ED}tulo");
printTitre($titre->getFirstChild()->getData());
my @estrofas = $poema->getElementsByTagName("estrofa");
foreach my $estrofa ( @estrofas ){
printEstrofa($estrofa);
printFinStrofa();
}
}#printPoema
sub printEstrofa($){ #arg. Element "estrofa"
my ($str) = @_;
my @versos = $str->getElementsByTagName("verso");
foreach my $verso ( @versos ){
print($verso->getFirstChild()->getData());
printFinVerso();
}
}#printEstrofa
# Choix typographiques
sub printTitre($){ # arg. chaîne
my ($chn) = @_;
print("<h2>$chn</h3>\n");
}
sub printFinVerso(){
print("<br />\n");
}
sub printFinStrofa(){
print("<hr />\n");
}
# Exécution
sub lecture ($){# nom de fichier
my ($fichIn) = @_;
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile($fichIn);
binmode(STDOUT, ":utf8");
print(
'<html><head><meta content="text/html; charset=UTF-8" http-equiv="content-type" />
<title>FromXML</title></head><body>'
);
printPoema ($doc->getDocumentElement());
print("</body></html>\n");
}#lecture
lecture($ARGV[0]);
Exercices : Modifier le programme ci-dessus de manière à...
- imprimer le texte à une strophe par ligne, les vers étant
séparés par des obliques :
Me gustas cuando callas porque estás como ausente / y me oyes desde lejos y mi voz no te toca. /....
- imprimer le texte à un vers par ligne, en numérotant les
vers de 5 en 5.
- imprimer le texte à une strophe par ligne, les vers étant
séparés par des obliques :
Exemples-2
Utilisation degetChildNodes
sur des documents mal ou peu
structurés.Des documents de ce genre sont fournis en abondance par le corpus Frantext, dont nous avons analysé la DTD au cours n° 2..
Les lignes ni les pages n'y sont individualisées, seuls les sauts de ligne et les sauts de page sont marqués par des balises vides.
Voici un extrait du fichier
L922.xml,
qui contient les Odes funambulesques de Théodore de Banville :<div>
<head>ÉCRIT SUR 1 EXEMPLAIRE ODELETTES</head>
<pb n="237"/>
<p>quand j'ai fait ceci,<lb/>
moi que nul souci<lb/>
ne ronge,<lb/>
la fièvre de l'or<lb/>
nous tenait encor :<lb/>
j'y songe !<lb/>
Pendant ces moments,<lb/>
comme les romans<lb/>
que fonde<lb/>
le joyeux About,<lb/>
elle avait pris tout<lb/>
le monde !<pb n="238"/>
Vous rappelez-vous<lb/>
les efforts jaloux,<lb/>
les brigues,<lb/>
les peurs, les succès ?<lb/>
Le combat eut ses<lb/>
Rodrigues !<lb/>
Oh ! Qu'il fut ardent,<lb/>
hélas ! Moi pendant<lb/>
la lutte<lb/>
et son bruit d'enfer,<lb/>
j'essayais un air<lb/>
de flûte !<lb/>
<hi rend="I"> juin 1858 : </hi></p>
</div>Dans ce fichier, chaque poème est enveloppé dans une balise
<div>,
laquelle contient - un
<head>avec le titre - un
<p>avec le texte, sur le modèle ci-dessus.
Chaque vers ne pourra être obtenu que comme un objet
Text
qu'on devra aller chercher parmi les ChildNodes de l'Element
p,lesquels sont de plusieurs sortes : des objets
Text, et
des Elements lb, pb et hi.Nous sommes donc bien obligés d'abandonner le confortable
getElementsByTagName
et de revenir à la technique minutieuse présentée à la section III.-
Engendrer une table donnant la liste des titres et, pour chacun, le nombre de vers du poème.
fichierLireTEI-1.pl
use strict;
use warnings;
use XML::DOM;
sub printDoc($){ #Document
my ($doc) = @_;
my @listDivs = $doc->getDocumentElement()->getElementsByTagName("div");
foreach my $div ( @listDivs ){
printDiv($div);
}
}#printDoc
sub printDiv($){ # objet "div"
my ($div) = @_;
my ($head) = $div->getElementsByTagName("head");
print($head->getFirstChild()->getData());
print(" : ".nbVers($div)." vers.\n");
}#printDiv
sub nbVers($){ # objet "div"
my ($div) = @_;
my $k =0; # le compteur de vers
my ($txt) = $div->getElementsByTagName("p");
my @enfs = $txt->getChildNodes();
foreach my $enf ( @enfs ){
if( $enf->getNodeName() eq '#text' ){ # c'est un vers
$k++;
}
}
return $k;
}# nbVers
# Exécution
sub lecture ($){# nom de fichier
my ($fichIn) = @_;
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile($fichIn);
binmode(STDOUT, ":utf8");
printDoc ($doc);
}#lecture
lecture($ARGV[0]);
Résultat :
jfp% perl LireTEI-1.pl L922.xml
LA CORDE ROIDE : 61 vers.
LA VILLE ENCHANTÉE : 108 vers.
LA BELLE VÉRONIQUE : 53 vers.
VARIATIONS LYRIQUES : 201 vers.
PREMIER SOLEIL : 45 vers.
LA VOYAGEUSE : 127 vers.
éVOHé, NéMéSIS INTéRIMAIRE : 1087 vers.
LES FOLIES NOUVELLES : 582 vers.
OCCIDENTALES : 970 vers.
RONDEAUX : 100 vers.
TRIOLETS : 186 vers.
à 1 AMI POUR PRIX TRAV. LITTéR. : 49 vers.
VILLANELLE DE BULOZ : 26 vers.
ÉCRIT SUR 1 EXEMPLAIRE ODELETTES : 25 vers.
VILLANELLE DES PAUVRES HOUSSEURS : 38 vers.
CHANSON SUR L'AIR DES LANDRIRY : 121 vers.
BALLADE CéLéBRITéS TEMPS JADIS : 29 vers.
VIRELAI à MES éDITEURS : 57 vers.
BALLADE DES TRAVERS DE CE TEMPS : 38 vers.
MONSIEUR COQUARDEAU, CHANT ROYAL : 64 vers.
MONSELET D'AUTOMNE, PANTOUM : 41 vers.
RÉALISME : 78 vers.
MÉDITATION POÉTIQUE LITTÉRAIRE : 28 vers.
MA BIOGRAPHIE À HENRI D'IDEVILLE : 49 vers.
À AUGUSTINE BROHAN : 37 vers.
LA SAINTE BOHÈME : 71 vers.
BALLADE DE LA VRAIE SAGESSE : 37 vers.
LE SAUT DU TREMPLIN : 62 vers.
jfp%
-
Imprimer le texte d'un poème sélectionné par un fragment de son titre
fichierLireTEI-2.pl
use strict;
use warnings;
use XML::DOM;
sub printDoc($$){ #Document, fragment de titre
my ($doc, $frag) = @_;
my @listDivs = $doc->getDocumentElement()->getElementsByTagName("div");
foreach my $div ( @listDivs ){
my ($head) = $div->getElementsByTagName("head");
my $titre = $head->getFirstChild()->getData();
if( $titre =~ m/$frag/ ){
printTitre($titre);
printDiv($div);
return;
}
}
print("Je n'ai pas trouv\x{00E9} de titre contenant '$frag'\n");
}#printDoc
sub printDiv($){ # objet "div"
my ($div) = @_;
my ($par) = $div->getElementsByTagName("p");
my @cont = $par->getChildNodes();
foreach my $frag ( @cont ){
my $indic = $frag->getNodeName();
if( $indic eq 'lb' || $indic eq 'pb'){
printFinLigne();
}elsif( $indic eq '#text' ){
my $chn = $frag->getData();
$chn =~ s/^\s*(\S*)/$1/; # supprime un saut de ligne initial
print( $chn );
}else{
# hi, ne rien faire
}
}
}#printDiv
sub printTitre($){ # arg. chaine
my ($txt) = @_;
print("***$txt***\n")
}#printTitre
sub printFinLigne(){
print("\n");
}
# Exécution
sub lecture ($$){# nom de fichier, fragment de titre
my ($fichIn, $frag) = @_;
my $parseur = XML::DOM::Parser->new();
my $doc = $parseur->parsefile($fichIn);
binmode(STDOUT, ":utf8");
printDoc ($doc, $frag);
}#lecture
lecture($ARGV[0], $ARGV[1]);
Résultat :
jfp% perl LireTEI-2.pl L922.xml EXEMPLAIRE
***ÉCRIT SUR 1 EXEMPLAIRE ODELETTES***
quand j'ai fait ceci,
moi que nul souci
ne ronge,
la fièvre de l'or
nous tenait encor :
j'y songe !
Pendant ces moments,
comme les romans
que fonde
le joyeux *About,
elle avait pris tout
le monde !
Vous rappelez-vous
les efforts jaloux,
les brigues,
les peurs, les succès ?
Le combat eut ses
*Rodrigues !
Oh ! Qu'il fut ardent,
hélas ! Moi pendant
la lutte
et son bruit d'enfer,
j'essayais un air
de flûte !
jfp% perl LireTEI-2.pl L922.xml SOLAILLE
Je n'ai pas trouvé de titre contenant 'SOLAILLE'
jfp%
Exercice : En combinant les deux programmes précédents,
en écrire un troisième qui imprime le poème le plus court du fichier.