Première question.
La différence entre les figures 1 et 2 est manifestement attribuable à un mauvais réglage du logiciel d'affichage, en l'occurrence Thunderbird. Essayons d'être plus précis.
On constate que dans les deux cas les caractères ASCII sont reproduits sans changement, mais que les nombreuses lettres porteuses de signes diacritiques de la fig. 2 apparaissent systématiquement sous la forme de séquences de deux caractères dans la fig. 1. Ceci fait soupçonner un codage d'origine en UTF-8, où les caractères en question sont représentés par deux octets, interprété selon un code à 8 bits (probablement Windows 1252 puisqu'on nous précise que le logiciel tourne sous Windows XP localisé en France). Pour s'en convaincre, il suffit d'examiner quelques exemples en utilisant l'Annexe 2 (tables Latin-1 et Latin Extended-A).
Les lettres diacritées qui apparaissent se répartissent en deux groupes : les voyelles portant un accent aigu (en tchèque, marque de longueur) qui appartiennent à la table Latin-1, et les lettres "typiquement tchèques" qui se trouvent dans la table Latin Extended-A. Les premières ont des numéros Unicode qui tiennent dans un octet, de la forme 0x00xy, où x = E ou F (ce sont toutes des minuscules), les secondes ont des numéros qui dépassent l'octet, de la forme 0x01xy, où x est compris entre 0 et 7, avec exactement 9 bits "utiles".
En répartissant les 8 ou 9 bits utiles dans la matrice UTF-8 à deux octets : 110abcde 10fghijk
on voit que les codes correspondants auront l'allure suivante :
- Pour les premières (8 bits) : a = b = c = 0,
et sachant que E = 1110 et F = 1111, à coup sûr d = e = 1 ;
le premier octet UTF-8 est donc toujours 11000011 = C3.
- Pour les secondes (9 bits) : a = b = 0, c = 1, et sachant que x ne dépasse pas 7 = 0111, à coup sûr d = 0,
mais e peut valoir 0 ou 1. Le premier octet UTF-8 sera donc soit 11000100 = C4, soit 11000101 = C5.
Achevons la démonstration pour le caractère slovaque 'l palatalisé' (dernière lettre du nom propre Figeľ) dont la forme qui apparaît dans la figure 2 ('l' surmonté d'un caron) ne se retrouve pas exactement dans la table Latin Extended-A.
On ne trouve dans cette table qu'un 'l' affublé d'une virgule : 'ľ', comme 'ď' et 'ť'.
Est-ce bien le même caractère ?
Oui, car son numéro Unicode est 0x013E et son code UTF-8 C4BE.
L'octet BE donne en Windows 1252 le caractère '¾', et sur la figure 1 nous lisons bien Figeľ.
Certaines lettres semblent échapper à la règle: l'affriquée minuscule 'č' (ligne 5 : Počet et autres), le d palatalisé minuscule 'ď' (ligne 6 : teďi) apparaissent en fig. 1 comme une seule lettre 'Ä' : PoÄet, teÄi.
C'est que le second caractère est non imprimable.
En effet, les numéros Unicode de 'č' et de 'ď' sont 0x010D et 0x010F, leurs codes UTF-8 sont C48D et C48F,
et dans la table de Windows 1252 les cases 8D et 8F sont vides !
On peut prévoir le même phénomène pour trois autres caractères du même bloc Unicode, mais ils n'apparaissent pas dans notre texte.
Le cas du i long 'í' est plus curieux : lui aussi se transcrit apparemment en un monocaractère 'Ã',
alors que son n° est 0xED et son code UTF-8 C3AD : d'après l'Annexe 1, l'octet AD paraît tout-à-fait imprimable en Windows 1252, quelque chose comme '-'.
Il faut croire que ce caractère était absent de la police qui a servi à l'affichage de la figure 1 !
Le doute n'est donc pas possible, nous avons bien affaire à de l'UTF-8 interprété comme du Windows 1252.
- Pour les premières (8 bits) : a = b = c = 0,
et sachant que E = 1110 et F = 1111, à coup sûr d = e = 1 ;
- Comment y remédier ? Voici la fenêtre qu'offre Thunderbird pour fixer le codage des caractères :
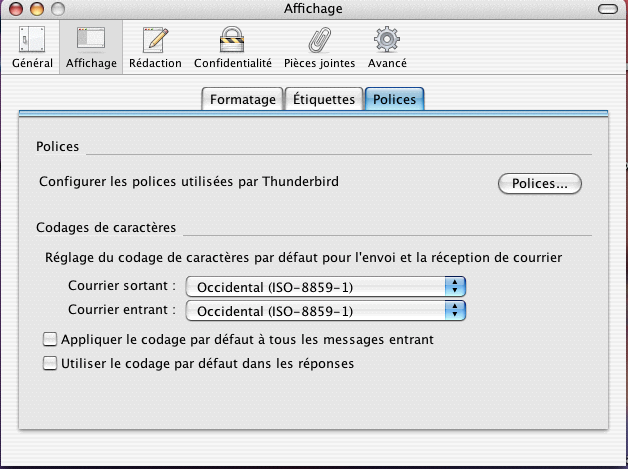
On voit qu'il n'est guère possible de demander de lire un certain fichier avec un certain codage.
Le seul réglage possible est celui du codage par défaut.
Or, il ne s'applique que si les en-têtes du message ne contiennent pas la mention charset dans le champ Content-Type.
Dans notre cas, sachant que le ficher est en UTF-8 (format "moderne"),
on peut penser que le logiciel de courrier qui l'a envoyé a fait correctement son travail
et qu'il a placé les deux en-têtes réglementaires :
Content-Type: text/plain; charset="utf-8"et
Content-Transfer-Encoding: 8bit(on peut le vérifier en demandant à Thunderbird d'afficher le code-source du message).
Dans ces conditions, on se demande comment l'affichage de la fig. 1 a pu être obtenu,
vu que le comportement normal est d'appliquer le codage des caractères annoncé dans l'en-tête du message,
ce qui donne l'affichage de la fig. 2.
C'est probablement parce que l'utilisateur a coché par mégarde la case Appliquer le codage par défaut à tous les messages entrants,
tout en conservant Occidental comme codage par défaut.
Il suffit alors de décocher cette case pour que tout rentre dans l'ordre !
Quant à l'option Utiliser le codage par défaut dans les réponses, elle répond au souci suivant :
normalement, la réponse à un message se fait avec le même codage que celui du message,
mais l'utilisateur peut souhaiter uniformiser ses envois.
Si cette option est choisie, la réponse sera écrite avec le codage par défaut
- et le message d'origine inclus dans la réponse sera recodé en conséquence, dans la mesure du possible.
Si ce recodage est impossible, Thunderbird en informe courtoisement l'utilisateur et lui propose d'employer UTF-8,
considéré comme "en général peu risqué".
[Ce dernier paragraphe est clairement de la publicité (gratuite) pour Thunderbird !]
Deuxième question.
L'analyse de la figure 3 montre que l'éditeur hexadécimal utilisé interprète les octets comme des numéros Unicode du bloc Latin-1au-delà de l'ASCII 7 bits (contrairement à ce que fait l'utilitaire Unix hexdump vu en cours).
Les octets FF et FE sont les numéros des caractères 'ÿ' et 'þ' dans Latin-1, 4E celui de 'N' (ASCII), etc, E8 celui de 'è' (Latin-1).
Les octets nuls donnent des blancs, ainsi que l'octet 20 (espace - ASCII).
Sauf les deux octets initiaux, chaque octet 'significatif' est suivi d'un octet nul. À quoi bon ?
La seule exception se trouve à la ligne 2 avec les deux octets consécutifs 19 20, l'octet 19 non imprimable donnant le signe '⊦'
et l'octet 20 normalement un blanc. À cet endroit le contexte demanderait une apostrophe,
qui se trouve en Unicode dans le bloc General Punctuation sous le n° 0x2019... Tiens, tiens !
Nous sommes certainement en UTF-16 : chaque caractère occupe deux octets, avec la plupart du temps un octet nul
vu que les caractères employés appartiennent tous (sauf l'apostrophe) à Latin-1.
Deux point restent en suspens :
- que signifient les deux octets initiaux "irréguliers" ?
- l'apostrophe a pour numéro 0x2019 et non pas 0x1920.
C'est l'ordre de lecture des octets qui est en cause, le caractère gros-boutien ou petit-boutien de la machine où la photo a été prise.
En l'occurrence, les deux octets initiaux FFFE sont le BOM (Bit Order Mark) du fichier.
Ils indiquent que le processeur visé est petit-boutien, ce qui signifie que les octets apparaissent dans le fichier
dans l'ordre inverse de l'ordre 'arithmétique'.
C'est pour cela que le numéro 0x2019 est réalisé par la séquence d'octets 19 20,
et que chaque octet 'significatif' est suivi d'un octet nul au lieu d'être précédé par lui.
Ce fichier est donc en UTF-16LE (Little Endian).
Troisième question.
Il s'agit ici du délicat problème du rapport entre un programme et son texte.Le programme est une entité exécutable, qui se présente matériellement comme un assemblage d'octets produit par le compilateur
(on peut parfaitement le lire avec hexdump),
et le texte en est une représentation accessible au programmeur, qui est elle-même un assemblage d'octets d'une nature complètement différente.
En principe le compilateur C ne connaît que les caractères ASCII.
Par extension, il accepte tous les caractères que lui transmet l'éditeur de textes utilisé,
à la condition expresse que ceux-ci soient représentés par un seul octet :
si on essaie de compiler le texte du programme après l'avoir sauvegardé en UTF-8, on obtient :
Le programme de l'énoncé offre deux sources de difficultés (en négligeant le commentaire initial) :
- les lettres accentuées figurant dans les messages envoyés par printf ;
- les deux constantes 'œ' et 'Œ' dans la comparaison fondamentale.
avec éventuellement des point d'interrogation à la place des caractères qu'il ne comprend pas.
Par exemple, si on sauvegarde le texte du programme avec le codage Windows, dans lequel 'œ' et 'Œ' sont effectivement codés sur un seul octet,
et si ce fichier s'appelle "prog.c",
l'exécution de la séquence "gcc prog.c; ./a.out prog.c" sur Macintosh
donne un message dont le contenu est exact mais dont la forme laisse à désirer :
et si ce fichier s'appelle "progM.c", l'exécution de la commande "gcc progM.c; ./a.out progM.c" donne aussi :
Et encore de même avec le codage ISO-8859-15 (Latin-9)
- mais pas avec ISO-8859-1 (Latin-1) pour lequel l'éditeur de texte refuse la sauvegarde car il détecte des "unmappable characters".
Bien évidemment, une commande comme "gcc progM.c; ./a.out prog.c" donne
En particulier, c'est ce phénomène qui est la cause de l'effet décrit dans l'énoncé, où le programme est enregistré en Windows
et appelé sur un texte provenant de Linux, donc (probablement) en Latin-9.
En somme, tant qu'on utilise des codages sur 8 bits le programme fonctionne normalement, compte-tenu des octets en présence.
Les choses changent si on veut utiliser UTF-8.
Appelons progU.c le texte sauvegardé en UTF-8. Voici ce que donne la commande "gcc progU.c; ./a.out progU.c":
progU.c:24:26: warning: character constant too long for its typeRien ne va plus ! En revanche, la chaîne-message est à présent imprimée correctement, sans points d'interrogation ...
progU.c: In function `main':
progU.c:24: warning: comparison is always false due to limited range of data type
progU.c:24:49: warning: character constant too long for its type
progU.c:24: warning: comparison is always false due to limited range of data type
Le fichier progU.c contient 0 occurrence(s) du caractère < œ>
Faites vous-même ces essais ! Voici le texte en question
(version remaniée de l'énoncé, conforme aux règles de portabilité formulées au cours 6,
à compiler par "gcc -Wall -pedantic progU.c").