L'écriture japonaise ne sépare pas les mots par des espaces. Dans texte japonais normalement constitué, les espacements qu'on aperçoit sont en général attachés à d'autres signes de ponctuation (parenthèses, guillemets, points ou virgules). Néanmoins, on rencontre parfois de vrais espaces, et on s'aperçoit alors qu'ils sont plus larges que les nôtres, occupant toute la place qui serait normalement dévolue à un caractère chinois (kanji) ou à un symbole d'un des deux syllabaires hiragana ou katakana. Voici par exemple une indication de lieu (場所) donnée en deux parties séparées par un blanc :
場所: 京都大学百周年時計台記念館 国際交流ホール
(source : http://www.i.kyoto-u.ac.jp/gcoe/).
On se pose alors la question :
l'effet observé est-il dû au rendu de la police employée pour les caractères chinois,
ou bien s'agit-il d'un caractère "blanc" spécifique, différent de notre ASCII x20 familier et dûment recensé par le catalogue Unicode ?
- Donnez votre jugement a priori, en l'étayant le plus solidement possible.
Pour alimenter votre réflexion, on vous signale que le texte ci-dessus ne fait l'objet d'aucune mise en forme, et que les polices employées sont donc tout bonnement celles que le navigateur utilise par défaut en fonction du numéro Unicode du caractère qu'il doit afficher.
En l'absence de mise en forme, s'il s'agissait d'un blanc ordinaire (ASCII x20), il n'y aurait aucune raison pour qu'il soit affiché
tantôt en largeur réduite (comme pour le premier blanc, qui suit les deux points), tantôt en grande largeur (comme pour le suivant).
Un spectacle comme celui de l'énoncé supposerait donc plusieurs caractères ASCII x20 successifs pour réaliser le second blanc.
Naturellement, tout ceci n'est qu'hypothèse, et la réalité peut être toute autre : ce que nous prenons pour "deux points suivis d'un blanc"
pourait fort bien être un unique caractère comportant de l'espace, à la manière des parenthèses japonaises U+FF08 et U+FF09
qui interviendront dans l'exemple suivant.
Il est donc indispensable de contrôler notre intuition en examinant les octets.
- Pour en avoir le cœur net, on fait appel à hexdump.
L'exemple ci-dessus étant logé dans un fichier nommé ExSp.txt, on demande hexdump -C ExSp.txt, et on obtient :
00000000 e5 a0 b4 e6 89 80 3a 20 e4 ba ac e9 83 bd e5 a4 |......: ........|
00000010 a7 e5 ad a6 e7 99 be e5 91 a8 e5 b9 b4 e6 99 82 |................|
00000020 e8 a8 88 e5 8f b0 e8 a8 98 e5 bf b5 e9 a4 a8 e3 |................|
00000030 80 80 e5 9b bd e9 9a 9b e4 ba a4 e6 b5 81 e3 83 |................|
00000040 9b e3 83 bc e3 83 ab e2 85 a2 |..........|
0000004a
Que vous en semble ?
On observe un "rythme" ternaire, le premier temps commençant par le quartet e = 1110.
Ceci indique un codage UTF-8 sur 3 octets, qui est bien ce qu'on attend pour les caractères chinois.
La seule exception est la séquence "3a 20" qui comporte deux caractères ASCII, les deux points ":" et notre fameux blanc.
Nous pouvons donc d'ores et déjà conclure que le "grand blanc" n'est pas composé de plusieurs ASCII x20 successifs,
est qu'il est donc réalisé par un caractère appartenant à la même plage que les caractères chinois.
Pour repérer ce caractère et déterminer son code UTF-8, il nous faut à présent compter les octets...
場 所 : 京 都 大
00000000 e5 a0 b4 e6 89 80 3a 20 e4 ba ac e9 83 bd e5 a4 |......: ........|
学 百 周 年 時
00000010 a7 e5 ad a6 e7 99 be e5 91 a8 e5 b9 b4 e6 99 82 |................|
計 台 記 念 館 X
00000020 e8 a8 88 e5 8f b0 e8 a8 98 e5 bf b5 e9 a4 a8 e3 |................|
X X 国 際 交 流 ホ
00000030 80 80 e5 9b bd e9 9a 9b e4 ba a4 e6 b5 81 e3 83 |................|
ー ル ? ? ?
00000040 9b e3 83 bc e3 83 ab e2 85 a2 |..........|
0000004a
Le code UTF-8 de notre "blanc japonais" est donc e38080.
Le triplet final e285a2 jette un doute, car il n'apparaît pas sur la ligne affichée.
Mais le comptage est suffisamment régulier pour qu'on écarte ce doute et qu'on mette ce caractère parasite sur le compte
d'une erreur de manipulation.
- En vue d'une ultime vérification, on a besoin du numéro Unicode du caractère "espace japonais" -
ne serait-ce que pour connaître sa dénomination officielle !
Peut-on vous le demander ?
Le code UTF-8 e38080 se développe en binaire (avec les notations du cours 4) 1110 0011 1000 0000 1000 0000.
Le numéro Unicode s'écrit donc en binaire sur 16 bits 0011 0000 0000 0000, et en hexa 0x3000.
En cherchant dans les tables Unicode on trouve effectivement sous ce numéro un caractère appelé IDEOGRAPHIC SPACE.
- On rencontre une ambiguïté du même ordre avec les chiffres : par exemple
出張講義2 授業風景(山形新聞2007年10月26日朝刊)
(source : http://web.yl.is.s.u-tokyo.ac.jp/members/yonezawa/is.kojinshoukai.htm)
On voit que le n° 2 d'une part et les éléments de date d'autre part apparaissent sous des formes légèrement différentes.
Est-ce affaire de rendu, ou bien y aurait-il aussi des chiffres japonais (en dehors des kanjis désignant les nombres, bien sûr) ?
- Adaptez votre raisonnement a priori à cette nouvelle observation.
Le raisonnement précédent est renforcé par le rendu manifestement différent pour le premier chiffre 2 et pour les élémentes de la date.
En l'absence de mise en forme, une telle différence est impossibe à obtenir sans faire intervenir deux jeux de caractères différents
au sens d'Unicode.
- On loge le nouvel exemple dans un fichier nommé ExChif.txt, on demande hexdump -C ExChiff.txt,
et on obtient :
00000000 e5 87 ba e5 bc b5 e8 ac 9b e7 be a9 ef bc 92 20 |............... |
00000010 e6 8e 88 e6 a5 ad e9 a2 a8 e6 99 af ef bc 88 e5 |................|
00000020 b1 b1 e5 bd a2 e6 96 b0 e8 81 9e 32 30 30 37 e5 |...........2007.|
00000030 b9 b4 31 30 e6 9c 88 32 36 e6 97 a5 e6 9c 9d e5 |..10...26.......|
00000040 88 8a ef bc 89 |.....|
00000045
Qu'en dites-vous ?
Comme précédemment, on observe une succession de triplets UTF-8, sauf pour les éléments de la date qui sont en ASCII,
et pour un blanc ASCII x20 qui s'est glissé en 16ème position.
Notamment, les parenthèses ne sont pas "nos parenthèses" ASCII x28 et x29, mais des "parenthèses japonaises".
Pour connaître leurs codes, il nous faut à nouveau compter les octets...
出 張 講 義 2 X X
00000000 e5 87 ba e5 bc b5 e8 ac 9b e7 be a9 ef bc 92 20 |............... |
授 業 風 景 ( 山
00000010 e6 8e 88 e6 a5 ad e9 a2 a8 e6 99 af ef bc 88 e5 |................|
形 新 聞 年
00000020 b1 b1 e5 bd a2 e6 96 b0 e8 81 9e 32 30 30 37 e5 |...........2007.|
月 日 朝 刊
00000030 b9 b4 31 30 e6 9c 88 32 36 e6 97 a5 e6 9c 9d e5 |..10...26.......|
)
00000040 88 8a ef bc 89 |.....|
00000045
Point de caractère parasite cette fois-ci !
Notre chiffre 2 japonais a donc efbc92 pour code UTF-8.
On note que les parenthèses japonaises ont pour codes efbc88 pour l'ouvrante, efbc89 pour la fermante,
et que (comme annoncé dans le commentaire à la question 1) l'ouvrante comporte un espace à sa gauche,
et la fermante un espace à sa droite : ce sont bien des caractères différents des nôtres !
- Quelle est selon vous la plage de numéros Unicode occupée par ces caractères apparemment familiers mais en fait exotiques ?
Si on suit les bonnes traditions, les chiffres occupent une plage de 10 positions qui se suivent.
En UTF-8, cette plage serait efbc90 - efbc99.
Et en numéros Unicode ?
Refaisons le calcul : efbc90 = 1110 1111 1011 1100 1001 0000
Le n° Unicode correspondant est sur 16 bits 1111 1111 0001 0000, soit 0xFF10.
La plage de n°s Unicode est ainsi 0xFF10 - 0xFF19, et on y trouve effectivement une série de
FULLWIDTH DIGIT ZERO, FULLWIDTH DIGIT ONE, etc.
- Adaptez votre raisonnement a priori à cette nouvelle observation.
Lorsque le courrier électronique est apparu, dans les années 70, les messages échangés étaient en texte "pur" (text/plain), sans aucune mise en forme. Progressivement, les logiciels de courrier se sont mis à interpréter et à engendrer le format HTML, ce qui permet des échanges plus riches, mais aussi plus dispendieux.
À moins qu'on ne les en dissuade explicitement, les logiciels modernes envoient donc leurs messages sous le double format text/plain et text/html. C'est alors le texte HTML qui est affiché à la réception, sauf si le client récepteur est trop primitif, auquel cas il traite la version en text/plain qui sert de secours.
Ceci se traduit par un message en deux parties ("Content-Type: multipart/alternative"), dont chacune porte ses propres indications de codage.
En voici deux exemples, l'un en sans mise en forme, l'autre avec mise en forme.
Pour chacun, on montre le spectacle affiché (par Thunderbird) et le code-source correspondant.
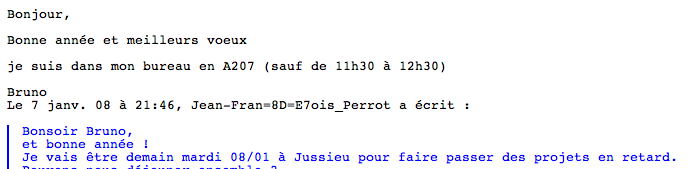
Content-Type: text/plain; charset=ISO-8859-1; format=flowed
Content-Transfer-Encoding: quoted-printable
Bonjour,
Bonne ann=E9e et meilleurs voeux
je suis dans mon bureau en A207 (sauf de 11h30 =E0 12h30)
Bruno
Le 7 janv. 08 =E0 21:46, Jean-Fran=3D8D=3DE7ois_Perrot a =E9crit :
> Bonsoir Bruno,
> et bonne ann=E9e !
> Je vais =EAtre demain mardi 08/01 =E0 Jussieu pour faire passer des =20=

Content-type: multipart/alternative;
boundary="Boundary_(ID_INUNPUiVRCT2n3/sjPY0xg)"
This is a multi-part message in MIME format.
--Boundary_(ID_INUNPUiVRCT2n3/sjPY0xg)
Content-type: text/plain; charset=utf-8
Content-transfer-encoding: quoted-printable
Bonjour=20M.=20Perrot,=20=0A=0ASuite=20=C3=A0=20une=20discussion=20avec=20Yousse=
f=20et=20D=C3=A9borah,=20on=20se=20demandait=20s'il=20fallait=20cr=C3=A9er=202=20=
tables=20(personnes,=20notes)=20ou=20une=20seule=20table.=0A=0Amerci=0A=0A=0A=
--Boundary_(ID_INUNPUiVRCT2n3/sjPY0xg)
Content-type: text/html; charset=utf-8
Content-transfer-encoding: quoted-printable
<font=20face=3D"Arial,=20Helvetica,=20sans-serif">Bonjour=20M.=20Perrot,=20<br>=0A=
<br>=0ASuite=20=C3=A0=20une=20discussion=20avec=20Youssef=20et=20D=C3=A9borah,=20=
on=20se=20demandait=20s'il=20fallait=20cr=C3=A9er=202=20tables=20(personnes,=20n=
otes)=20ou=20une=20seule=20table.<br>=0A<br>=0Amerci<br>=0A<br>=0A<br>=0A</font>=
--Boundary_(ID_INUNPUiVRCT2n3/sjPY0xg)--
-
Dans le second exemple, on vous demande de décoder la deuxième partie
du message, c'est à dire de donner fragment de texte HTML qui est
interprété par Thunderbird, ou en d'autres termes, ce que serait cette
partie du message si l'en-tête "Content-Transfer-Encoding:" portait "8bit" au lieu de "quoted-printable".
Il s'agit de décoder le "quoted-printable" pour retrouver les caractères eux-mêmes tels que les transmettrait un transfer-encoding sur 8 bits,
sachant d'autre part qu'ils sont codés en UTF-8. Les "=20" redeviennent des espaces, les "=0A" des sauts de ligne, les sauts de ligne précédés de "=" disparaissent, et les octets UTF-8 des lettres accentuées sont interprétés normalement (puisque charset = "UTF-8")
<font face= "Arial, Helvetica, sans-serif">Bonjour M. Perrot, <br>
<br>
Suite à une discussion avec Youssef et Déborah, on se demandait s'il fallait créer 2 tables (personnes, notes) ou une seule table.<br>
<br>
merci<br>
<br>
<br>
</font> - Toujours dans le second exemple, que contiendrait la première partie si le "charset" était "ISO-8859-1" comme dans le premier exemple, au lieu de "utf-8".
Cette fois, on conserve "Content-Transfer-Encoding:quoted-printable" mais on change le charset.
Seuls vont être modifiés les octets représentant les lettres accentuées : "é" deviendra E9, et "à" sera E0.
Bonjour=20M.=20Perrot,=20=0A=0ASuite=20=E9=20une=20discussion=20avec=20Yousse=
f=20et=20D=E0borah,=20on=20se=20demandait=20s'il=20fallait=20cr=E9er=202=20=
tables=20(personnes,=20notes)=20ou=20une=20seule=20table.=0A=0Amerci=0A=0A=0A= - Dans le premier exemple, pouvez-vous expliquer l'affichage de "Jean-Fran=8D=E7ois_Perrot" ?
Cette forme est très étrange : elle cumule le code du c cédille en MacRoman (8D) et en Latin-1 (E7).
Elle apparaît dans une position bien particulière, au sein d'une réponse à un message,
dans une ligne qui n'est pas produite par le scripteur mais engendrée par le logiciel de courrier
à partir d'informations qu'il trouve dans le message initial.
L'enquête doit donc se diriger vers le message en question.
Et là, surprise ! Voici un extrait du code-source dudit message :
From: =?windows-1252?Q?Jean-Fran=8D=E7ois_Perrot?=
<Jean-Francois.Perrot@lip6.fr>
Reply-To: Jean-Francois.Perrot@lip6.fr
User-Agent: Thunderbird 2.0.0.9 (Macintosh/20071031)
MIME-Version: 1.0
..........................
Content-Type: text/plain; charset=windows-1252; format=flowed
Content-Transfer-Encoding: 8bit
Bonsoir Bruno,
et bonne année !
...........................
...........................
Hic jacet lepus !
Dans le champ From : (qui fait partie des en-têtes obligatoires pour le protocole SMTP) apparaît l'étrange salmigondis
aux deux c cédilles, assorti de la mention incongrue "windows-1252".
C'est de là que provient notre affichage, fidèlement transmis par le logiciel qui a élaboré la réponse.
Et dans l'en-tête Content-Type: le charset annoncé est effectivement "windows-1252".
Pour en savoir plus sur ce codage à 8 bits non standard, voyez Wikipedia, comme toujours.
Utiliser ce codage sur un Macintosh ne peut que conduire à des incohérences !
Par quelle aberration un logiciel (Thunderbird) normalement réglé pour envoyer de l'UTF-8
s'est-il mis à coder en "windows-1252", qui ne figure même pas dans la liste des codages disponibles,
je ne le sais pas.
Morale de l'histoire : on ne surveille jamais assez ses outils informatiques !
Les mieux réglés peuvent soudain se dérégler ... Et je ne parle pas des questions de sécurité !