Informations relatives aux caractères Unicode
Le consortium Unicode met en ligne une véritable base de données relative aux caractères de son catalogue.D'un point de vue conceptuel, on peut considérer que c'est ce modèle de données qui définit la notion de caractère !
En effet, la nature des propriétés en question ne peut s'expliquer qu'au vu des problèmes qui se posent
dans la mise en œuvre du standard Unicode.
Néanmoins, nous essaierons de donner ici une idée de cette base de données avant d'aborder quelques-uns de ces
problèmes, afin de pouvoir suggérer, pour chacun d'entre eux, la manière dont il est résolu.
On trouvera dans le chapitre 3 du livre de Y. Haralambous une analyse des propriétés en question,
plus approfondie que celle de B. Desgraupes.
L'expression "base de données" est à prendre ici en un sens intuitif et non pas au sens technique
qu'elle revêt en informatique (avec un SGBD, etc). La taille des données en question (quelques mégaoctets)
ne rend pas nécessaire de recourir à une technologie lourde, des fichiers texte suffisent (en ASCII pur, bien entendu).
Nous donnons ici quelques indications sommaires sur l'organisation retenue.
Pour en avoir plus de détais sur cette organisation, voir le chapitre 2 du livre de Bernard Desgraupes.
-
Le répertoire UNIDATA
Cette base de données est matérialisée par le répertoire http://www.unicode.org/Public/UNIDATA/
qui contient un ensemble de fichiers-texte (ASCII) assez rébarbatifs,
mais à la syntaxe très soigneusement définie en vue d'une exploitation automatique.
Cette syntaxe est expliquée dans le document http://unicode.org/Public/UNIDATA/UCD.html.
- Le principal de ces fichiers est UnicodeData.txt,
qui rassemble les propriétés fondamentales des caractères autres que les caractères chinois :
ces derniers sont traités à part, dans un (gros) fichier nommé Unihan.txt,
dont le format est expliqué dans http://unicode.org/charts/unihan.html.
Chaque ligne du fichier UnicodeData.txt correspond à un numéro Unicode, et donne quinze propriétés du caractère,
séparées par des virgules : en voici un exemple
015F;LATIN SMALL LETTER S WITH CEDILLA;Ll;0;L;0073 0327;;;;N;LATIN SMALL LETTER S CEDILLA;*;015E;;015E
On y lit, de gauche à droite :- le numéro (code-point) en hexadécimal : 015F
- le nom officiel du caractère : LATIN SMALL LETTER S WITH CEDILLA
- sa catégorie (lettre, nombre, etc : en tout 30 possibilités - ici "Lettre lowercase") : Ll
- sa classe combinatoire (utile dans l'accumulation de signes diacritiques) : 0
- sa direction (gauche-droite, etc : en tout 18 possibilités - ici Left-to-Right) : L
- sa décomposition (ici
s+cédille) : 0073 0327
- sa valeur numérique en tant que chiffre décimal :
- sa valeur numérique en tant que chiffre autre que décimal :
- sa valeur numérique en tant que symbole isolé :
- s'il a la propriété "miroir" (changer de forme
si on change le sens d'écriture - vrai ou faux) : N
- son nom dans la version 1.0 du catalogue
Unicode : LATIN SMALL LETTER S CEDILLA
- le commentaire qui lui est attaché dans la norme ISO10646 : *
- le caractère majuscule associé : 015E
- le caractère minuscule associé :
- le caractère "titre" associé (variante de la
majuscule) : 015E
-
Ces données de base sont complétées par une collection de fichiers
annexes (voir liste et explications
dans le livre de Desgraupes).
Certains ajoutent d'utiles précisions, notamment PropList.txt, qui introduit une série de sous-catégories fines,
comme celle des chiffres hexadécimaux Hex_Digit.
D'autres sont d'un usage poins évident, par exemple :
- le fait d'avoir ou non une forme minuscule
(resp. majuscule)
se déduit de la ligne associée au caractère dans UnicodeData.txt
- mais l'indication "opérationnelle" du caractère
"canonique"
(nécessaire pour les manipulations indépendantes de la casse)
est donnée dans le fichier CaseFolding.txt.
Voir ci-dessous.
voire pour être lus par des humains, comme NamesList.txt.
Enfin, on trouve commodément une partie de ces informations dans les documents pdf
relatifs aux différents blocs : Haralambous consacre une section entière de son livre
à l'exégèse de ce genre de fichiers (p. 117 - 122). - le fait d'avoir ou non une forme minuscule
(resp. majuscule)
- Le principal de ces fichiers est UnicodeData.txt,
-
Exemple :
quelques informations relatives au caractère s cédille ş, n° x015F
extraites du fichier dérivé (à l'usage des lecteurs humains) NamesList.txt :
015F LATIN SMALL LETTER S WITH CEDILLA *
La dernière ligne indique que le même caractère (au sens de la normalisation : voir plus loin)
* Turkish, Azerbaijani, Romanian, ...
* this character is used in both Turkish and Romanian data
* a glyph variant with comma below is preferred for Romanian
x (latin small letter s with comma below - 0219)
: 0073 0327
est obtenu par la séquence s (ASCII x73) suivi de "cédille souscrite" ̧0327 COMBINING CEDILLA
qu'il ne faut pas confondre avec le caractère "cédille isolée"
* French, Turkish, Azerbaijani
x (cedilla - 00B8)
00B8 CEDILLA
* this is a spacing character
* other spacing accent characters: 02D8-02DB
x (combining cedilla - 0327)
# 0020 0327
- La connaissance de cette base est directement utile
pour déterminer
quels caractères doivent être pris en considération pour traiter une langue donnée.
Par exemple, le bloc arabe comporte une quantité de lettres dérivées de l'alphabet de base,
utilisées pour noter des langues de l'Iran, de l'Afghanistan et du Pakistan
(pashto, sindhi, ourdou, etc), et les noms de ces caractères ne sont pas toujours très évocateurs
ainsi le caractère ھ : 06BE ARABIC LETTER HEH DOACHASHMEE.
La lecture du fichier NamesList.txt permet de s'y retrouver.
(en l'occurrence :
06BE ARABIC LETTER HEH DOACHASHMEE
* Urdu
* forms aspirate digraphs)
À un niveau plus technique, les informations de la base alimentent les procédures
qui effectuent les traitements suivants.
L'affichage du
texte
C'est bien entendu la première préoccupation relative aux "caractères
d'imprimerie" !Au-dela de la production des pixels pour chaque caractère,
qui relève de la mécanique typographique de la police choisie (voir le cours 3),
certaines préoccupations relèvent du texte lui-même, ou plus exactement de sa représentation comme fichier
de caractères (eux-mêmes réalisés comme des octets - par exemple, en UTF-8).
Nous allons voir qu'Unicode adopte un principe simple, mais dont la mise en œuvre pose quelques problèmes.
-
Principe : Ordre de lecture
On considère que le texte affiché (sur l'écran ou par l'imprimante) possède un ordre naturel de lecture.
Cet ordre "logique" est différent de l'ordre spatial : ce dernier peut être horizontal de gauche à droite,
ou de droite à gauche, ou dans les deux sens une ligne sur deux (écriture boustrophédon),
ou encore vertical de haut en bas, et là encore de gauche à droite ou de droite à gauche.
Plus précisément, dans l'ordre de lecture la voyelle suit la consonne, comme dans "b-a, ba".
Principe : Les caractères Unicode sont rangés dans le fichier dans l'ordre de lecture.
Corollaire : la disposition spatiale du texte affiché est entièrement à la charge du logiciel d'affichage.
Nous allons examiner à présent trois des questions qui se posent dans ce contexte.
-
Ordre d'écriture
- A priori, écrire de droite à gauche n'offre pas
plus de difficultés qu'écrire de gauche à droite...
mais en fait l'ordre gauche-droite s'applique aux chiffres même pour les écritures droite-gauche.
On n'échappe donc pas à la bidirectionnalité !
Ce problème est traité par Unicode
- en attribuant à chaque caractère une propriété
de directionnalité
(5ème champ dans le fichier UnicodeData.txt)
- en spécifiant un algorithme
d'affichage bidirectionnel qui exploite ces
propriétés,
dont on trouvera une analyse détaillée chez Haralambous, p. 129 - 141.
- en attribuant à chaque caractère une propriété
de directionnalité
- Exemple (repris du livre de
Bernard Desgraupes, p. 165, en le rectifiant et en le complétant) :
Et Dieu dit "fiat lux" : יהי אור, et la lumière fut : ויהי-אור
(mieux que "et facta est lux" de la Vulgate !)
- Pour apprécier la subtilité de la chose,
réfléchissons par exemple au statut des parenthèses :
les seules parenthèses présentes en Unicode ont les numéros x0028 (ouvrante) et x0029 (fermante).
Or, la forme (glyphe) de la parenthèse ouvrante (resp. fermante) n'est pas la même selon qu'on écrit
de gauche à droite ou de droite à gauche !
Par conséquent, en Unicode les parenthèses possèdent la propriété dite "miroir bidirectionnel",
fixée dans le fichier UnicodeData.txt (10ème champ), et le changement de forme lui-même
est réglé par le fichier annexe BidiMirroring.txt.
- Illustration : Dans l'exemple
précédent, le choix de l'ordre d'affichage des caractères est fait sans
erreur
par le logiciel car les caractères hébraïques sont connus comme s'écrivant de droite à gauche
(champ n° 5 dans UnicodeData.txt).
Certains signes de ponctuation, comme la virgule ou le point d'interrogation, sont naturellement orientés
"de gauche à droite". Il existe donc une virgule spécifique aux écritures de droite à gauche
(arabic comma, n° 1548, 0x060C) et un point d'interrogation idem.
Mais d'autres signes, comme le point, n'ont pas d'orientation propre. Il y a "un seul" point dans Unicode.
Si un point est entouré de caractères "droite-gauche", il sera traité de même.
Mais un point qui termine une plage "droite-gauche" et qui est suivi par une plage "gauche-droite",
où faut-il l'écrire ?
Pour lever cette ambiguïté, en HTML il faut placer le fragment de texte concerné dans une plage
marquée "droite-gauche" (<span dir="rtl">....</span>).
À l'intérieur de cette plage, en vertu de la propriété "miroir bidirectionnel", l'interprétation des parenthèses
est inversée. (démo)
Et Dieu dit "fiat lux" (יהי אור !) et la lumière fut (ויהי-אור !)
(mieux que "et facta est lux" de la Vulgate !)
- A priori, écrire de droite à gauche n'offre pas
plus de difficultés qu'écrire de gauche à droite...
-
Signes diacritiques
Il n'y a guère de système d'écriture qui se passe entièrement de signes accessoires
(accents, points, cédilles et autres) posés sur ou sous les caractères majeurs.
Le traitement de ces signes pose des problèmes qui diffèrent suivant les cas.
Nous donnons ici au terme "signe diacritique" une acception large, comme on le verra,
sans nous soucier des divers sens techniques que le mot diacritic peut prendre dans le standard Unicode
(3 entrées dans l'index du livre de Desgraupes !)
- Il arrive que ces signes accessoires soient
intégrés au caractère principal :
c'est le cas notamment pour les lettres accentuées du français,
(et plus généralement des extensions à l'alphabet latin),
ainsi que pour les accents, esprits et iota souscrits du grec polytonique.
Dans ce cas, la théorie de l'ordre de lecture s'applique sans difficulté pour l'affichage,
c'est en revanche le logiciel d'acquisition qui a le problème d'engendrer le caractère "complexe"
à partir de plusieurs frappes consécutives (voyez notre accent circonflexe !).
- Mais il arrive aussi que les signes diacritiques
représentent des entités indépendantes,
comme les voyelles de l'hébreu ou de l'arabe, ou soient traités comme tels
(en hébreu, les points distinguant le sin שׂ du shin שׁ,
en arabe, l'absence de voyelle sûkûn et le signe de redoublement shadda).
Das ce cas, ces signes apparaissent comme des caractères à part entière,
mais ils ont des propriétés particulières relative à l'espace qu'ils occupent (non-spacing characters).
On les qualifie de combinatoires - puisqu'ils se combinent avec d'autres -
et on leur donne une catégorie (3ème champ dans le fichier UnicodeData.txt)
dont le nom commence par M (comme "marque") : Mn, Mc ou Me
selon qu'ils ne prennent point de place, qu'ils en prennent ou qu'ils entourent le caractère principal.
Précisions que dans l'ordre de lecture - donc dans le fichier - ils viennent après le caractère principal.
S'il y en a plusieurs, leur accumulation est réglée par un ordre donné par la classe combinatoire
du caractère principal (3ème champ dans le fichier UnicodeData.txt)
Voici notre exemple précédent en hébreu dûment vocalisé :
יְהִי אוֹר; וַיְהִי-אוֹר
- Notons enfin qu'on passe insensiblement des signes
diacritiques, où il y a clairement une hiérarchie
entre le caractère principal et le caractère annexe, au problème plus général de la combinaison
des caractères (liaisons, ligatures et autres modifications liées à la position du caractère dans le mot).
- Il arrive que ces signes accessoires soient
intégrés au caractère principal :
-
Liaisons, ligatures et autres modifications liées à la position du caractère dans le mot
Nous n'aborderons que deux exemples de ce type de problèmes posés aux logiciels de visualisation :
les ligatures de l'écriture indienne devanâgari et la forme variable des caractères arabes.
Les problèmes de la devanâgari se retrouvent mutatis mutandis dans toutes les écritures indiennes (y compris la tibétaine),
et ceux de l'arabe affectent aussi le syriaque.
-
Mise en œuvre de la devanâgari : traitement des ligatures
-
Le problème
- L'écriture
devanâgari considère que la voyelle a (bref) est inhérente à
chaque consonne.
Elle ne l'écrit donc pas : le caractère x0915 क = ka
- Les autres voyelles en revanche sont
écrites : कु = ku, को
= ko, etc.
Les caractères de voyelles en question ont le statut de signes diacritiques
(indiqué dans le 3ème champ du fichier UnicodeData.txt par un libellé commençant par 'M' - comme Mark)-
le 'u' bref ' ु ' U+0941 est de la
catégorie Mn :
0941;DEVANAGARI VOWEL SIGN U;Mn;0;NSM;;;;;N;;;;;,
c'est donc un signe qui ne prend point de place (non-spacing character),
d'où son indifférence au sens d'écriture (dans le champ n° 5 :NSM= Non-Spacing Mark) - tandis que le 'o' (toujours long) ' ो' U+094B est
de la catégorie Mc :
094B;DEVANAGARI VOWEL SIGN O;Mc;0;L;;;;;N;;;;;
car il occupe clairement autant de place qu'un caractère "normal", et il s'écrit de gauche à droite - de même pour le '
i' bref 'ि 'U+093F:093F;DEVANAGARI VOWEL SIGN I;Mc;0;L;;;;;N;;;;;
qui a pourtant un comportement différent : il vient se placer avant la consonne !
cette affaire d'importance est confiée au zèle du moteur de rendu... - et de même encore en tamoul et en bengali pour des voyelles qui s'écrivent autour (des deux côtés) de la consonne !
-
le 'u' bref ' ु ' U+0941 est de la
catégorie Mn :
- Mais comment faire si on ne veut pas de
voyelle, pour avoir un groupe de 2 ou 3 consonnes ?
On a alors recours à une ligature, qui peut prendre des formes variées (glyphes), où les caractères composants sont plus ou moins reconnaissables :
क + व = क्व , क + म = क्म , क + ष = क्ष , क + र = क्र
- On trouve un tableau complet des ligatures binaires sur la Wikipedia anglaise
(il y en a aussi de ternaires, commestrdans स्त्रीstrī= femme, épouse) .
Mais les formes correspondantes ne figurent pas dans le catalogue Unicode !
- Comment va-t-on faire ?
- L'écriture
devanâgari considère que la voyelle a (bref) est inhérente à
chaque consonne.
-
La solution
- Il existe dans l'alphabet devanâgari une
lettre spéciale, le virâma, n° 2381 = x094D,
de catégorie Mn
indiquant l'absence de voyelle.
Ce caractère appartient à une sous-catégorie Grapheme_Link donnée dans le fichier PropList.txt
(ce qu'Haralambous p. 114 traduit par gluon de graphème).
Il s'écrit comme une sorte de virgule souscrite : क् = k sans voyelle.
- Dans l'usage normal, cette lettre n'est
employée qu'en fin de mot : महान् mahãn = grand
(comme dans mahãrãjã et dans mahãtmã).
Elle apparaît également pour éviter aux typographes des ligatures particulièrement acrobatiques,
ou pour simplifier la lecture à l'intention des enfants :
- dans un manuel de hindi pour classes élémentaires on trouve दुपट्टा dupaṭṭã = écharpe, avec virâma
- mais le dictionnaire donne दुपट्टा,
avec ligature.
- Même si l'emploi du virâma est assez restreint
dans l'usage courant,
il offre la possibilité d'une écriture normalisée sans ligature.
- Il existe dans l'alphabet devanâgari une
lettre spéciale, le virâma, n° 2381 = x094D,
de catégorie Mn
- Le
choix de réalisation avec Unicode est :
- on écrira (dans le fichier) sous forme normalisée, avec virâma
- et
la réalisation des ligatures sera confiée au logiciel d'affichage.
- Il en résulte une exigence très forte à l'égard
des éditeurs de texte, des navigateurs, entre autres !
Tous ne sont pas également performants...
Soulignons que le standard Unicode est très discret sur ces ligatures
(la seule indication étant la qualification du virâma comme gluon de graphème)
alors même que certaines d'entre elles ont pratiquement acquis le statut de caractères indépendants
et que leur emploi est quasi-obligatoire (kṣa : क + ष = क्ष, et jña : ज + ञ = ज्ञ).
D'autre part, il faut reconnaître que le choix est vaste et qu'il est largement affaire de style typographique
(traditionnaliste, moderniste...) si bien qu'on sort très vite du domaine de compétence du standard.
Exemple : comparez le savoir-faire de différents outils sur le mantra गायत्री (Gâyatrî)
Comme votre instrument d'observation sera peut-être différent du mien,
je vous montre les images de ce que je vois sur Mac-OS X.3 :
- d'abord le
contenu du fichier html tel que le révèle TextEdit.
- le travail impeccable du navigateur Safari,
- le travail beaucoup moins satisfaisant de Firefox
2 sur Macintosh, qui visiblement n'a pas investi sur ce point,
contrairement à ses versions sur Windows et sur Linux.
- d'abord le
contenu du fichier html tel que le révèle TextEdit.
-
Illustrations
- Il suffit pour se convaincre d'examiner
avec un outil révélant les octets des fichiers
contenant de la devanâgari :
la représentation du virâma en UTF-8 est <E0><A5><8D>
- Sachant que क= <E0><A4><95>
et que व = <E0><A4><B5>
on trouve bien dans le fichier क्व = <E0><A4><95><E0><A5><8D><E0><A4><B5>
etc...
- Pour obtenir l'absence de ligature dans
दुपट्टा,
il a fallu insérer un caractère supplémentaire après le virâma,
à savoir le n° x200C antiliant sans chasse, alias ZWNJ (Zero-Width Non-Joiner), en UTF-8 : <E2><80><8C>.
(Merci à Y. Haralambous pour son excellent livre!)
Il y a donc à cet endroit dans le fichier :
<E0><A4><A6><E0><A5><81><E0><A4><AA><E0><A4><9F><E0><A5><8D><E2><80><8C><E0><A4><9F><E0><A4><BE>
et une ligne plus loin, avec un caractère de moins :
<E0><A4><A6><E0><A5><81><E0><A4><AA><E0><A4><9F><E0><A5><8D><E0><A4><9F><E0><A4><BE>
- Nombreux exemples dans la page de
démonstration "Qu'est-ce
qu'Unicode" en hindi.
- Il suffit pour se convaincre d'examiner
avec un outil révélant les octets des fichiers
contenant de la devanâgari :
-
Démonstration... et difficultés techniques
-
Écrire dans un éditeur comme TextEdit : on voit les ligatures se former
à l'écran...
- Mais aussi problème d'avoir une police qui se prête à ce rendu complexe :
à ce niveau de complexité les mécaniques de Microsoft (Uniscribe) et d'Apple (ATSUI = Apple Type Services for Unicode Imaging)
ne sont plus compatibles, et une police valable sous Windows ne fonctionne pas sous MacOS. - Pour plus de détails sur les ligatures des écritures indiennes, voir le chapitre 10
sur le site de Patrick Andrièshttp://hapax.qc.ca/.
-
Écrire dans un éditeur comme TextEdit : on voit les ligatures se former
à l'écran...
-
-
Formes des caractères arabes
-
Rappel : chaque lettre de l'alphabet
arabe peut revêtir en principe quatre formes,
suivant qu'elle isolée, initiale, médiale ou finale.
Exemple 1 : les quatre formes de la lettre ha (U+0647) :
- isolée : ه
- initiale : هـ
- médiale : ـهـ
- finale : ـه
Exemple 2 : les quatre formes de la lettre ayn (U+0639) :
- isolée : ع
- initiale : عـ
- médiale : ـعـ
- finale : ـع
- isolée : ه
- Dans le répertoire Unicode, il n'y a qu'un code
par caractère, et non pas quatre correspondant aux quatre formes.
Les formes liées sont engendrées par le logiciel de visualisation.
Pour ce faire, le logiciel est aidé par les informations contenues dans le fichier ArabicShaping.txt,
qui formalise les "obligations de liaison" pour les écritures arabe et syriaque.
- Les
caractères sont toujours écrits de gauche à droite
dans le fichier, y compris les caractères arabes.
C'est le logiciel de visualisation qui les affiche de droite à gauche (bidirectional algorithm).
Notons que la propriété de directionalité (5ème champ dans le fichier UnicodeData.txt)
prend pour les caractères arabes (et syriaques) la valeur AL (comme Arabic Letter)
et non R (Right to Left) comme pour les lettres hébraïques.
-
En UTF-8 les caractères arabes sont codés sur 2 octets (comme les
lettres accentuées françaises),
tandis que les caractères indiens (devanâgari et autres) sont codés sur 3 octets, comme on a pu le voir.
- Exemple
le texte : &#
x0627;&# x0644;&# x0645;&# x064F;&#
x0639;&#
x064E;&# x0644;&# x0651;&# x064E;&#
x0642;&#
x064E;&# x0627;&# x062A;
(À votre avis, pourquoi ces blancs bizarres entre "&#" et "x...." ?)
qui se transcrit "almu`allaqât" est interprété comme suit par Safari, avec une belle ligature entre lâm et mîm
et le fatha impeccablement placé au-dessus du shadda qui redouble le second lâm :
et d'une manière différente par Firefox, avec un traitement plus fruste de la liaison lâm-mîm et un placement
moins précis du fatha au-dessus du shadda :
On trouvera de nombreux exemples dans la page de démonstration "Qu'est-ce qu'Unicode" en arabe.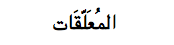
ainsi que dans une excellente introduction à la littérature arabe (en espagnol).
- Adaptation au persan ( فارسی
fârsi)
L'écriture du persan fait appel à trois lettres supplémentaires,
le pé : پ (x067E), le tché : چ (x0686), le jé : ژ (x0698), et le gaf گ (x06AF),
qui suivent les mêmes règles que les lettres arabes dont elles sont dérivées.
En outre, elle emploie en position finale un ya sans points : ی (x06CC),
qu'il ne faut pas confondre aec l'alif maksura de l'arabe : ى (x0649).
Nombreux exemples dans la page de démonstration "Qu'est-ce qu'Unicode" en persan.
Pour quelques URL de sites proposant des textes persans, voyez mes notes sur Khayyâm. - Pour plus de détails sur la réalisation des écritures hébraïque, arabe et syriaque, voir le chapitre 9
sur le site de Patrick Andrièshttp://hapax.qc.ca/.
-
Rappel : chaque lettre de l'alphabet
arabe peut revêtir en principe quatre formes,
-
Opérations sur les caractères
Nous abordons ici brièvement des manipulations des textes qui ne sont pas liées à l'affichage.Elles sont nombreuses, mais souvent cachées au regard extérieur.
Par exemple, dans le domaine administratif, la gestion de listes de noms rangées en ordre alphabétique,
ou la normalisation de "nom, prénom" en "NOM, Prénom" (avec des majuscules significatives).
Dans le domaine littéraire, les recherches de fréquence de mots dans des corpus, l'établissement de concordances.
La possibilité de traiter ce genre de questions d'une manière systématique est sans aucun doute un des grands progrès apportés par Unicode.
-
Classes de caractères
Comme on l'a vu, la baseUnicodeData.txtdéfinit toute une série de propriétés dont certaines sont directement accessibles
dans des langages de programmation comme Perl et Java, par le mécanisme des expressions régulières.
En Java, ces propriétés sont en outre accessibles via les classesjava.lang.Characteretjava.lang.Character.UnicodeBlock.
-
Expressions régulières.
L'interaction entre le standard Unicode et les moteurs d'expressions régulières est une question de fond qui a fait l'objet d'un rapport détaillé
de la part du consortium Unicode :
Unicode Technical Standard #18 :UNICODE REGULAR EXPRESSIONSdont la dernière révision date du 2008-08-29.
Nous nous limiterons ici à sa mise en œuvre dans les expressions régulières de Perl et de Java
La nomenclature issue d'Unicode est fort abondante ! L'idée est d'utiliser cette nomenclature dans les e.r. avec la notation
\p{nom_de_la_propriété}avec\pminuscule (et\P{nom_de_la_propriété}avec\Pmajuscule pour désigner la négation).
Exemple :LuouUppercaseLetterdésigne la classe des lettres majuscules,LlouLowercaseLettercelle des lettres minuscules.
\p{Lu}\p{Ll}+' va donc décrire les noms dont l'initiale est majuscule et le reste (non-vide) en minuscules,
quel que soit l'alphabet employé (à condition qu'il distingue majuscules et minuscules, comme le grec, le cyrillique ou l'arménien).
Les propriétés utilisables sont principalement de trois sortes :
- Les catégories générales, comme
LuetLlillustrées ci-dessus.
Ce sont celles qui apparaissent dans le champ n° 3 du fichierUnicodeData.txt,
auxquelles on peut ajouter les questions de directionnalité, par exemple\p{BidiClass:R}désignant les caractères qui s'écrivent de droite à gauche,
ainsi que les "propriétés étendues" commeWhiteSpaceet leurs dérivés commeAlphabeticouASCII.
- Les écritures (en anglais scripts)
:
Greek,Latin,Han...
- Les blocs Unicode, dont le nom est préfixé par '
In'.
Ces blocs recouvrent souvent des écritures (scripts) :InHiragana(bloc) est fonctionnellement identique àHiragana(script),
mais certaines écritures se répartissent à travers plusieurs blocs (notammentLatin).
La distinction n'est donc pas superflue.
section Unicode Character Properties.
Accès via des classes en Java
Les catégories générales (champ n° 3) sont représentées en Java par un jeu de constantes définies dans la classejava.lang.Character:
par exemple, la catégorie "Mn" (signe diacritique n'occupant point d'espace) est représentée par la constanteCharacter.NON_SPACING_MARK.
Étant donné un caractère connu par son n° Unicode k, cette catégorie s'obtient parCharacter.getType(k).
La classeCharacterdéfinit toute une batterie de prédicats dérivés de ces catégories, du genreCharacter.isLetter(k),
mais aussi quelques autres commeCharacter.isMirrored(k), qui dit si le caractère désigné a ou non la propriété de "miroir bidirectionnel"
que nous avons évoquée plus haut.
Rappelons que les blocs Unicode sont représentés en Java par la classejava.lang.Character.UnicodeBlock,
dont les instances sont répertoriées sous des noms directement dérivés de ceux qu'ils portent dans le standard Unicode.
Étant donné un caractère connu par son n° Unicode k, son bloc s'obtient parCharacter.UnicodeBlock.of(k).
On peut donc écrire quelquechose comme :
Character.UnicodeBlock hexgram = Character.UnicodeBlock.forName("YIJING HEXAGRAM SYMBOLS");
if( Character.UnicodeBlock.of(k)== hexgram ){... }
-
-
Minuscules/Majuscules
- Certains jeux de caractères (dont le
nôtre)
connaissent une distinction entre majuscules et minuscules
appelée dans le jargon des typographes la distinction de casse (bas de casse, haut de casse,
en anglais case, lowercase, uppercase).
En Unicode cette distinction a été introduite au niveau des caractères eux-mêmes,
et le A majuscule est donc un caractère différent du a minuscule.
Les caractères soumis à cette distinction sont appelés (dans le jargon Unicode) bicaméraux.
Comme on l'a vu, pour une lettre minuscule (resp. majuscule) la majuscule (resp. minuscule) correspondante
apparaît dans le 13ème (resp. 14 ème) champ du fichier UnicodeData.txt.
- Un mot pour éclairer le 15ème champ : la
forme
"majuscule de titre" (en anglais titlecase) est
celle
que doit prendre la lettre lorsqu'elle est initiale majuscule mais suivie de minuscules
(comme dans les noms propres en français, et comme les substantifs dans les titres en anglais,
d'où l'appellation titlecase). Cette forme n'est différente de la majuscule que pour des caractère digraphes,
introduits en croate pour des raisons de compatibilité avec le serbe, par exemple le caractère dž = x01C6.
- Cette distinction se traduit par la
possibilité
de
"mettre un mot en majuscules (resp. minuscules)",
et le problème est de fournir les informations nécessaires aux nombreux logiciels qui auront à s'en préoccuper.
Elle induit également la préoccupation de travailler "sans tenir compte de la casse",
et là aussi il y a des informations à fournir pour que cet "oubli de la casse" se fasse sans erreur,
c'est le rôle du fichier CaseFolding.txt.
- Les complications sont minimes : cas du i
sans
point turc ı, dont la majuscule est un I
"ordinaire",
du eszett allemand ß dont la majuscule est SZ - officiellement SS -, des lettres doubles du croate,
voire de certaines graphies traditionnelles comme le t du nom propre néerlandais 't Hooft.
- Démonstration.
- Certains jeux de caractères (dont le
nôtre)
connaissent une distinction entre majuscules et minuscules
-
Normalisation des caractères composés
Ce problème est lié à la présence possible de plusieurs signes diacritiques accompagnant un même caractère principal.
- Ce cas ne se présente pas en français,
mais il
est
fréquent par exemple en vietnamien,
où les marques de ton viennent s'ajouter à l'indication de sonorité des voyelles :
on trouve ces caractères composés dans le bloc Latin Extended Additional.
Exemples, dans le nom même de l'écriture vietnamienne romanisée, quốc ngữ
ố n°7889 = x1ED1 LATIN SMALL LETTER O WITH CIRCUMFLEX AND ACUTE
ữ n°7919 = x1EEF LATIN SMALL LETTER U WITH HORN AND TILDE
- Le grec polytonique est sans doute le
champion
de
l'accumulation des diacritiques,
avec jusqu'à trois signes sur la même lettre principale (accent, esprit et iota souscrit).
Exemple : le nom du dieu des morts, Hadès, est
ᾄδης, avec
ᾄ n°8068 = x1F84 GREEK SMALL LETTER ALPHA WITH PSILI AND OXIA AND YPOGEGRAMMENI
mais si on veut lui donner l'initiale majuscule à laquelle il a droit, on obtient
ᾌδης, avec
ᾌ n°8076 = x1F8C GREEK CAPITAL LETTER ALPHA WITH PSILI AND OXIA AND PROSGEGRAMMENI
Sur le passage de YPO- à PROS- dans le traitement du iota, voir http://www.tlg.uci.edu/~opoudjis/unicode/unicode_adscript.html
- Pour se faire une idée des questions quis
se
posent, regardons la décomposition
du caractère composé ᾄ donnée par la table UnicodeData.txt :
elle est en deux termes, dont le premier est lui-même composé
1F84 -> 1F04 0345
1F04 = GREEK SMALL LETTER ALPHA WITH PSILI AND OXIA -> 1F00 0301
1F00 = GREEK SMALL LETTER ALPHA WITH PSILI -> 03B1 0313
03B1 = GREEK SMALL LETTER ALPHA
0345 = COMBINING GREEK YPOGEGRAMMENI;Mn
0301 = COMBINING ACUTE ACCENT;Mn
0313 = COMBINING COMMA ABOVE;Mn
Ce qui nous amène à la décomposition finale : 1F84 = 03B1 0313 0301 0345
Mais on pourrait ordonner différemment les diacritiques...
Cette séquence a-t-elle un caractère canonique ? Sur quel critère peut-on en décider ?
Sur les questions de ce genre, voir le chap. 5 de Desgraupes.
- Ce cas ne se présente pas en français,
mais il
est
fréquent par exemple en vietnamien,
-
Ordre alphabétique
Le tri par ordre alphabétique et ses dérivés (p. ex. insertion dans une liste de manière à respecter l'ordre)
est une opération extrêmement fréquente dans de très nombreuses activités informatisées.
Il est effectué par des procédures codées "en dur" dans les langages et dans les environnements de programmation.
Par conséquent, il serait extrêmement utile d'en avoir une spécification qui permettrait de s'assurer
de la validité des implémentations...
Hélas, ce n'est pas simple !
-
Remarque préliminaire
Dès qu'on quitte les alphabets de base, l'ordre alphabétique ne relève plus de l'écriture, mais de la culture !
- En suédois, å, ä,
et ö viennent (dans cet ordre) en fin de
dictionnaire,
ce qui peut surprendre vu que å est souvent remplacée paraa(ancien ā long).
En danois et en norvégien, ce sont æ, ø, å qui viennent terminer la liste.
- En espagnol ch,
ll
et ñ sont traditionnellement considérés comme des lettres
indépendantes,
ce qui fait que, dans le dictionnaire, chacal vient après curial, et llamar après lupo.
- Et en français, dans quel ordre
rangez-vous
l'ensemble {cote, côte, côté, coté} ?
cote, coté, côte, côté, dit Larousse...
cote, côte, coté, côté, dit Robert...
Lequel a raison ?
- En suédois, å, ä,
et ö viennent (dans cet ordre) en fin de
dictionnaire,
-
UCA : Une base de départ
Unicode propose un algorithme de comparaison alphabétique par défaut (Unicode Collation Algorithm),
qui fournit un point de départ pour des réalisations plus raffinées.
Il doit tenir compte des diverses spécifications du standard,
comme celles qui règlent l'équivalence des caractères composés et de leurs décompositions.
On en trouvera une présentation au chapitre 6, section 6.5 du livre de Bernard Desgraupes.
-
-
Conclusion : Progrès irréversible d'Unicode
- L'adoption d'Unicode se heurte à des traditions et à des "particularismes locaux" en matière de codage. Toutefois, sa généralisation à terme ne fait guère de doute, portée par les recommandations du W3G,
- Citons notamment l'emploi systématique d'UTF-8 par
l'encyclopédie en ligne Wikipedia,
qui en plus des informations directes qu'elle apporte, donne des liens vers d'autres sites en UTF-8.
- On observe par exemple une multiplication des
sites
UTF-8 dans le domaine indien :
- un site Wikisource consacré à la
littérature sanscrite en devanâgari
(on trouve aussi la littérature sanscrite et plus généralement la littérature classique indienne
en translittération latine - avec signes diacritiques - UTF-8)
- par exemple, sur le site Wikipedia consacré à Rabindranath Tagore figurent des fragments de ses poèmes
en bengali UTF-8.
Les œuvres de Tagore en bengali sont disponibles sur au moins deux sites, dont un Wikisource.
- le cas du tamoul
est particulièrement spectaculaire : après avoir adopté un codage sur
8bits TSCII propre au tamoul,
la conversion à UTF-8 est en marche.
Ainsi pour le projet Madurai [le texte ci-après apparaît dans la seconde partie de la page, qui est en anglais]:
Since its launch in 1998, Project Madurai etexts are released in Tamil script form as per TSCII
(Tamil Script Code for Information Interchange) encoding. Since 2004 we have started releasing
etexts in Tamil unicode as well.
- un site Wikisource consacré à la
littérature sanscrite en devanâgari
- En revanche, les Japonais semblent plus réticents.
Une
grande partie de leurs (nombreux) sites
conserve des codages sur 8/16 bits comme Shift-JIS qui, n'étant pas liés par l'unification Han,
peuvent désigner des fromes d'idéogrammes "typiquement japonais" qui échappent au standard Unicode.
- L'histoire n'est pas terminée ! Unicode évolue, et
malgré sa masse imposante on ne doit pas désespérer de pouvoir
orienter son évolution dans le sens jugé le plus favorable au bonheur de l'humanité.
Voyez par exemple l'article de Yannis Haralambous paru dans la revue Document Numérique en 2002 :
Unicode et typographie, un amour impossible.
le groupe qui régit le World Wide Web.