D'un codage à l'autre
Voici les octets contenus dans un fichier nomméEx.txt. 6c 65 73 20 64 e9 70 65 6e 73 65 73 20 64 65 20
6c 92 c9 74 61 74 20 0d 0a 76 69 73 61 6e 74 20
e0 20 73 74 69 6d 75 6c 65 72 20 0d 0a 6c 92 e9
63 6f 6e 6f 6d 69 65 2e 0d 0aQuand je le donne à lire à mon éditeur de textes favori, ce dernier me fait la réponse suivante :
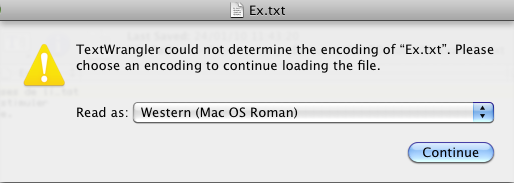
et voici les choix qu'il me propose :
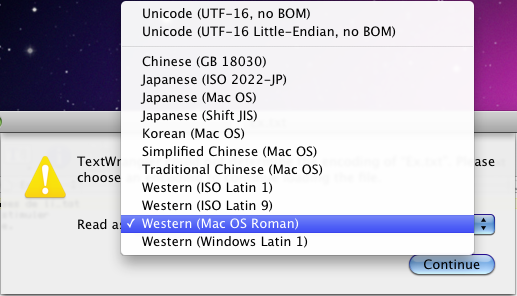
Dans cette liste "Windows Latin 1" doit se comprendre comme "Windows 1252".
- Pourquoi le codage "Unicode
(UTF-8)"
est-il absent du menu ?
Et pourquoi les codages UTF-16 proposés portent-ils la mention "no BOM" ?
UTF-8 est absent car il n'est pas applicable,
et que l'éditeur TextWrangler est assez perfectionné pour s'en rendre compte.
En effet, on trouve dans notre fichier
- en majorité, des octets ASCII (dont le 1er chiffre ne
dépasse pas 7),
décodables tels quels en UTF-8
- mais aussi 6 occurrences d'octets non-ASCII, en rouge
ci-dessous:
6c 65 73 20 64 e9 70 65 6e 73 65 73 20 64 65 20
6c 92 c9 74 61 74 20 0d 0a 76 69 73 61 6e 74 20
e0 20 73 74 69 6d 75 6c 65 72 20 0d 0a 6c 92 e9
63 6f 6e 6f 6d 69 65 2e 0d 0a
- En UTF-8, chacun de ces octets devrait marquer le début
d'une séquence de 2 à 4 octets,
codant un caractère hors du bloc Basic Latin.
Et pour chacun, l'octet suivant devrait commencer par10, donc avoir pour premier chiffre8,9,AouB.
- Les séquences de 2 octets présentes dans notre fichier
:
e9 70,92 c9,e0 20, et92 e9,
sont donc toutes inacceptables en UTF-8.
FF FEouFE FF
(ou encoreEF BB BFsi on était en UTF-8) qui pourrait apparaître tout au début du fichier,
il est tout simplement absent.
- en majorité, des octets ASCII (dont le 1er chiffre ne
dépasse pas 7),
- J'hésite entre les quatre options "Western".
Pouvez-vous prévoir le texte affiché par l'éditeur suivant chacun de ces choix ?
Quel est "le bon choix" ?
Les quatre interprétations occidentales auront en commun tous les caractères ASCII :
l e s d e9 p e n s e s d e
l 92 c9 t a t CR LF v i s a n t
e0 s t i m u l e r CR LF l 92 e9
c o n o m i e . CR LF
elles divergeront sur les octets non-ASCII.
- ISO Latin 1
les dépenses de l?État.
visant à stimuler
l?économie
Le gros point d'interrogation signale que l'octet92ne fait pas partie du codage,
il signale donc une erreur (qui se matérialise de manières diverses selon le logiciel employé pour l'affichage).
- ISO Latin 9
Même jeu. Les différences avec Latin-1 n'apparaissent pas dans notre échantillon.
- Mac OS Roman
les dÈpenses de lí…tat.
visant ‡ stimuler
líÈconomie
Les lettres accentuées de Latin-1 sont interprétées différemment par MacRoman, comme on sait,
et l'octet92fait partie du système. L'affichage se fait donc sans erreur.
- Windows Latin 1
les dépenses de l’État.
visant à stimuler
l’économie
On a fortement grossi les deux occurrences de l'apostrophe, caractère codé en Windows-1252 par l'octet92
(seule différence avec Latin-1 perceptible sur notre échantillon).
Ici aussi, l'affichage se fait sans erreur...
et, au contraire de MacRoman, il donne un résultat "correct" pour un regard francophone (métaphore hardie !).
ce qui est cohérent avec les sauts de ligne marqués parCR LF.
- ISO Latin 1
- Je veux utiliser ce fichier pour faire des essais avec le
logiciel
recode,
qui, comme son nom l'indique, permet de faire passer un fichier d'un codage à un autre.
- En entendant par erreur un signal quelconque
indiquant caractère inconnu,
puis-je le recoder sans erreur en ISO-8859-1 ? en MacRoman ?
D'après les lectures ci-dessus, le recodage en ISO-8859-1 (alias Latin-1) va buter sur l'apostrophe,
caractère inconnu du système-cible, qui va provoquer une erreur.
Il est possible (le nombre d'options à l'usage derecodeest considérable) qu'une règle d'adaptation
soit invoquée, transformant l'apostrophe en "simple quote" (par exemple), mais ceci est une autre histoire.
En revanche, le recodage vers MacRoman ne pose aucun problème, puisque
tous les caractères du texte font partie du système MacRoman.
- Si je le recode en UTF-8, combien d'octets contiendra le
fichier recodé ?
En passant en UTF-8, les octets ASCII restent inchangés.
Les 6 octets non-ASCII vont donner :
- 2 octets chacun pour les 3 lettres accentuées
à,é, etÉ, qui logent dans le bloc Latin-1 Supplement.
donc 4 octets supplémentaires (2 occurrences deé) ; - 3 octets pour l'apostrophe
U+2019, en UTF-8E2 80 99, qui loge dans la zone Symbols Area, bloc General Punctuation.
[ Son nom officiel estRIGHT SINGLE QUOTATION MARK, il fait pendant àU+2018LEFT SINGLE QUOTATION MARK,
conformément aux dispositions de Windows-1252 (octets92et91) et de MacRoman (octetsD5etD4).
Le fichier documentaire officielNamesList.txtdéclare à son sujet :
* this is the preferred character to use for apostrophe
Dont acte !]
Au titre de l'apostrophe (2 occurrences) nous aurons donc 4 octets supplémentaires.
Le texte actuel contient 58 octets, une fois recodé en UTF-8 il en contiendra 66.
N.B. Le passage à UTF-8 est indépendant du codage des sauts de ligne.
Résultats expérimentaux :
On note que l'apostrophe a été recodée en Latin-1 par l'accent aigu (octetB4).
recode WINDOWS-1252..ISO-8859-1 < /Users/marie-annemoreaux/Desktop/exam\ 2.txt > res.txt
les dépenses de l´État
visant à stimuler
l´économie.
0000: 6C 65 73 20 64 E9 70 65 6E 73 65 73 20 64 65 20 les d.penses de
0010: 6C B4 C9 74 61 74 20 0D 0A 76 69 73 61 6E 74 20 l..tat ..visant
0020: E0 20 73 74 69 6D 75 6C 65 72 20 0D 0A 6C B4 E9 . stimuler ..l..
0030: 63 6F 6E 6F 6D 69 65 2E 0D 0A conomie...
/* ************************************************************************ */
recode WINDOWS-1252..MacRoman < /Users/marie-annemoreaux/Desktop/exam\ 2.txt > res.txt
les dépenses de l’État
visant à stimuler
l’économie.
0000: 6C 65 73 20 64 8E 70 65 6E 73 65 73 20 64 65 20 les d.penses de
0010: 6C D5 83 74 61 74 20 0D 0A 76 69 73 61 6E 74 20 l..tat ..visant
0020: 88 20 73 74 69 6D 75 6C 65 72 20 0D 0A 6C D5 8E . stimuler ..l..
0030: 63 6F 6E 6F 6D 69 65 2E 0D 0A conomie...
/* ************************************************************************ */
recode WINDOWS-1252..utf-8 < /Users/marie-annemoreaux/Desktop/exam\ 2.txt > res.txt
les dépenses de l’État
visant à stimuler
l’économie.
0000: 6C 65 73 20 64 C3 A9 70 65 6E 73 65 73 20 64 65 les d..penses de
0010: 20 6C E2 80 99 C3 89 74 61 74 20 0D 0A 76 69 73 l.....tat ..vis
0020: 61 6E 74 20 C3 A0 20 73 74 69 6D 75 6C 65 72 20 ant .. stimuler
0030: 0D 0A 6C E2 80 99 C3 A9 63 6F 6E 6F 6D 69 65 2E ..l.....conomie.
0040: 0D 0A ....
- 2 octets chacun pour les 3 lettres accentuées
- En entendant par erreur un signal quelconque
indiquant caractère inconnu,
Courrier électronique
Une estimable société savante m'envoie une newsletter que mon mailer ne trouve pas à son goût :
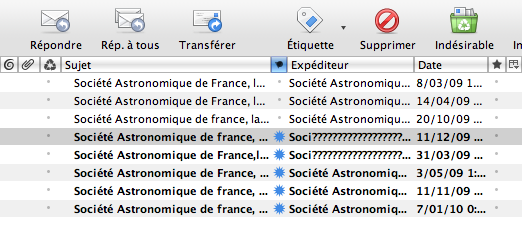
Pourquoi ces points d'interrogation ? Je vais lire le code-source du message et je vois :
From: Société Astronomique de France
<saf.lalettre@club-internet.fr>
To: Jean-Francois.Perrot@lip6.fr
Subject: =?iso-8859-1?Q?Soci=E9t=E9_Astronomique_de_franc?=
=?iso-8859-1?Q?e,_la_lettre,_d=E9cembre_2009?=
Content-Type: multipart/related;
type="multipart/alternative";
boundary="----=_NextPart_001_35D9_61CB1D76.1EE4647A"
Date: Fri, 11 Dec 2009 00:57:27 +0100- Pouvez-vous m'expliquer ces points d'interrogation étranges ?
Ce message est libellé de manière incorrecte : le champFrom:contient des caractères non-ASCII,
en l'occurrence des "e accent aigu".
Le logiciel chargé de l'afficher peut donc à bon droit refuser de le faire.
La version 2 de Thunderbird ici illustrée proteste en envoyant des points d'interrogation jusqu'à la fin du champ fautif,
la version suivante se contente d'un point d'interrogation par caractère non-ASCII :

- À quoi riment ces indications cabalistiques
=?iso-8859-1?Q?Soci=E9t=E9_...?
Justement, il s'agit de concilier le désir d'écrire "Société" avec ses accents et de rester conforme au règlement
qui les proscrit dans les en-têtes. Voir le cours n° 3.
Ici, on dit au logiciel-client que le champSubject:est codé en Latin-1 et transmis en quoted-printable,
ce qui explique pourquoi les "e accent aigu" apparaissent comme "=E9".
C'est ce qu'il aurait aussi fallu faire pour le champFrom:!
Cédille aléatoire
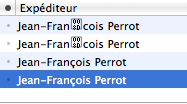
J'ai un nouveau mailer perfectionné qui me montre des choses étonnantes, par exemple :- dans une liste d'expéditeurs, votre serviteur apparaît
comme :
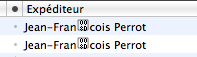
- je me vois cité comme ceci :

- mais aussi comme cela :

- Les "expéditeurs" ainsi affichés correspondent en général à
des
textes-sources
From: =?windows-1252?Q?Jean-Fran=8Dcois_Perrot?=<Jean-Francois.Perrot@lip6.fr>
mais aussi bien à
From: =?UTF-8?B?SmVhbi1GcmFuwo1jb2lzIFBlcnJvdA==?=<Jean-Francois.Perrot@lip6.fr>
L'affichage ci-dessus vous paraît-il justifié ?
Le premier texte-source donne comme texte du "carnet d'adresses" (au sens du cours 3)
les octets de "Jean-Fran=8Dcois_Perrot" à décoder en quoted-printable, lus en Windows-1252.
Les octets en question sont au nombre de 21 :
- les 9 octets ASCII "
Jean-Fran", - l'octet non-ASCII
8D - les 11 octets ASCII "
cois_Perrot"
8Dne fait pas partie du code,
et par conséquent il est normal que l'affichage montre une symbole bizarre signalant cette erreur.
Le second texte-source donne une chaîne de 30 caractères ASCII à décoder en base 64 et à lire en UTF-8.
Ces 30 caractères correspondent à 30 blocs de 6 bits, soit 180 bits ou 22,5 octets.
En fait il s'agit de 22 octets, 176 bits complétés à 180 par les 4 derniers bits du dernier caractère de la chaîne
qui estA=000000(le premier indice dans la chaîne base 64).
Donc 2 octets de plus que les 20 de "Jean-Francois Perrot" :
ce sont probablement ces deux octets qui sont affichés par le symbole bizarre en question.
Pour en avoir le cœur net, utilisons l'outil du cours 3 : il traduit notre chaîne en 23 octets :
4a 65 61 6e 2d 46 72 61 6e c2 8d 63 6f 69 73 20 50 65 72 72 6f 74 00
L'octet nul à la fin n'est pas significatif, il complète à 8 les 4 derniers bits duA.
En remplaçant les octets ASCII par leurs valeurs on lit "Jean-Franc2 8dcois Perrot".
Orc2 8dest la représentation UTF-8 normale de l'octet non-ASCII8d, lequel comme nous le savons n'appartient pas
au code Latin-1. Ces deux octets ne sont donc pas interprétables, ainsi que nous l'avions soupçonné.
- les 9 octets ASCII "
- Les deux "citations" sont issues de deux messages également
paramétrés :
Content-Type: text/plain; charset=ISO-8859-1;
Content-Transfer-Encoding: quoted-printable
dont l'un contient
Le 19 janv. 10 =E0 18:50, Jean-Fran=3D8Dcois_Perrot a =E9crit :
et l'autre
Le 18 janv. 10 =E0 14:26, Jean-Fran=8Dcois Perrot a =E9crit :
Which is which ?
Le premier message se décode normalement en :
Le 18 janv. 10 à 14:26, Jean-Fran=8Dcois_Perrot a écrit :
car "=3D" se décode en "=" et "8D" reste invariant puisque c'est de l'ASCII.
Il correspond donc à la seconde citation.
Le second en revanche ne se décode pas sans erreur, toujours à cause de l'octet8Dqui n'appartient pas au codeISO-8859-1.
C'est cet octet qui provoque l'apparition du carré blanc dans le première citation.
- Le texte de la "première citation" se laisse analyser en
octets. Pour le fragment
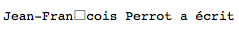
on trouve :
4A 65 61 6E 2D 46 72 61 6E C2 8D 63 6F 69 73 20
50 65 72 72 6F 74 20 61 20 C3 A9 63 72 69 74
Le carré blanc vous paraît-il justifié ?
Oui, il correspond aux octetsC2 8Dqui codent (en UTF-8) un caractère qui n'existe pas dans le catalogue Unicode.
(cf. la sous-question 1 ci-dessus).
- J'ai fait le nécessaire pour retrouver ma cédille et
désormais j'apparais dignement
sauf une fois où je suis déguisé en
dont voici le code-source :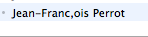
From: =?ISO-2022-JP?B?SmVhbi1GcmFuYyxvaXMgUGVycm90?=<Jean-Francois.Perrot@lip6.fr>
Que s'est-il passé ?
À en juger par les libellés corrects avec cédille, le message d'origine était "Jean-François Perrot".
Le problème vient du code japonaisISO-2022-JPtraité au cours 3 : le "c cédille" ne fait pas partie de ce code,
puisqu'il n'est ni un caractère ASCII, ni un caractère japonais !
Comment cette contradiction a-t-elle pu être levée ?
Le code-source donne une chaîne de 28 caractères à décoder en base 64, soit 21x6 = 168 bits ou 21 octets,
qui font fortement soupçonner une lecture en 21 caractères ASCII "Jean-Franc,ois Perrot".
Ce serait alors le mailer perfectionné qui aurait pris sous son bonnet la décision d'adapter le message au codage
en substituant "c," à "ç".
Confirmation avec l'outil du cours 3 : il traduit notre chaîne en 21 octets :
4a 65 61 6e 2d 46 72 61 6e 63 2c 6f 69 73 20 50 65 72 72 6f 74c'est-à-dire
Jean-Franc,ois Perrotcomme prévu.