D'un codage à l'autre
Les puissants moyens informatiques de mon université m'ont permis de télécharger un fichier intituléextract.csv.xls. Je cherche à en lire le contenu...
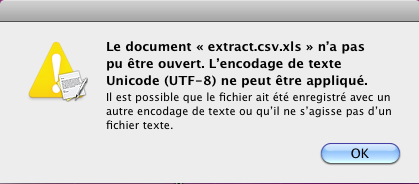
Mon éditeur de textes favori (TextEdit) me répond sèchement
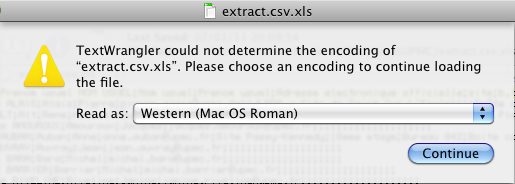
Un autre éditeur de textes (TextWrangler) me fait la réponse suivante :
et voici les choix qu'il me propose :
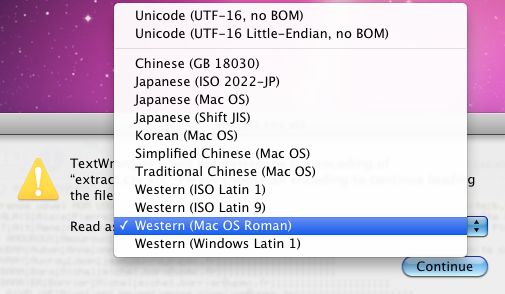
N.B. Dans cette liste "Windows Latin 1" doit se comprendre comme "Windows 1252".
Enfin mon vieil Excel (version Macintosh) accepte d'ouvrir le
fichier !
En regardant à la
loupe, je vois qu'il s'agit de champs séparés par des points-virgules
(comme annoncé par l'extenion ".csv"),
mais les lettres accentuées sont bizarres...

- Que s'est-il passé ? En pratique, que dois-je répondre à
l'interrogation de l'éditeur TextWrangler ?
- Si je choisis le codage "UTF-16, no BOM",
voici le début de ce que TextWrangler me montre :
Suis-je en butte à une tentative d'espionnage industriel ? Pouvez-vous me rassurer ?
- Et si je prends "UTF-16 Little-Endian, no
BOM",
j'obtiens :
Mon inquiétude redouble... À l'aide !
Courrier électronique
Je traduis un petit texte de Grazia Deledda (romancière sarde,
Prix
Nobel en 1926),
je l'envoie à mon épouse par e-mail, en pièce jointe, et voici ce
qu'elle reçoit :
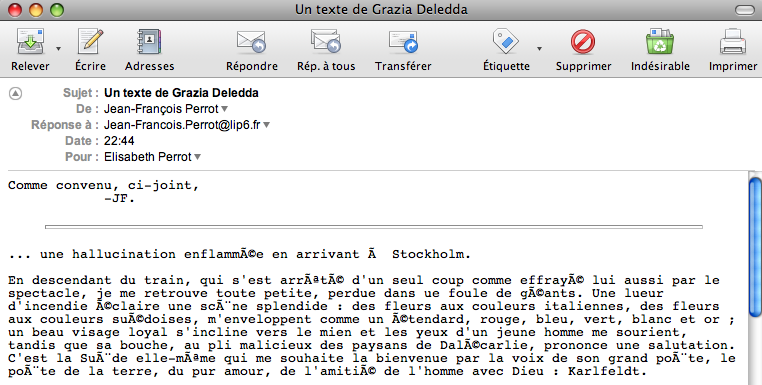
Explication ? Remède ?
pdf et les accents
Je trouve sur le réseau un intéressant document en pdf dont voici l'en-tête :

Pour travailler commodément je fais dans OpenOffice un copier-coller qui réussit apparemment :

mais lorsque j'essaie de rechercher un mot, ça se gâte !
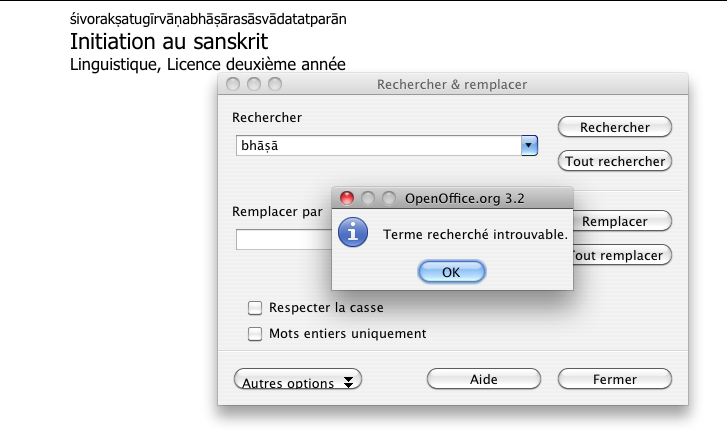
-
Que se passe-t-il ?
Je vous donne un indice : lorsque je dirige mon copier-coller non plus vers OpenOffice, mais vers mon éditeur HTML (KompoZer),
je vois apparaître :
-
Si je demande à l'outil Statistiques d'OpenOffice le nombre de caractères de la première ligne,
que va-t-il me répondre ?
Devinette
Une annonce d'habilitation à diriger des recherches récemment diffusée comporte le résumé suivant :
La résolution de problèmes algébriques non linéaires constitue l’un
des grands défis posés au calcul scientifique. Dans de nombreux domaines
des sciences de l’ingénieur, ces problèmes algébriques encodent des
situations géométriques imposées à des variables à valeurs dans les
réels. Le plus souvent, on cherche donc à obtenir des informations sur
les solutions réelles de systèmes polynomiaux. La complexité de ces
problèmes est souvent exponentielle en le nombre de variables. De
plus, le caractère non-linéaire des problèmes considérés ainsi que la
nécessité d’obtenir quelques garanties sur la qualité des résultats
des calculs font du Calcul Formel un outil privilégié. Les enjeux sont
donc multiples : développement d’algorithmes exacts, maîtrise de leur
complexité, développement de logiciels efficaces en pratique et
identification des spécifications utiles aux utilisateurs. Ces travaux
s’appuient sur des idées géométriques récentes aboutissant à des
algorithmes efficaces en pratique et une bonne maîtrise de la
complexité.
À votre avis, d'où proviennent les entités "fi"
et autres ?
Que faudrait-il faire pour éviter leur apparition ?
N.B. Le mot entité et pris ici au sens de HTML et de XML, c'est-à-dire de
chaîne de caractères faisant l'objet d'une interprétation particulière.