En pays lointain
Comme je sais bien peu de japonais, je traduis ligne à ligne une page web que je veux exploiter.
Je clique sur le lien entouré de rouge et j'obtiens le désolant spectacle que voici :

- [très facile] Quel est le codage des caractères
de ma page franco-japonaise ?
N'oubliez pas de justifier votre réponse !
Cette page contient des caractères chinois et des lettres accentuées, c'est donc très probablement de l'UTF-8.
En effet, les systèmes de codage autres qu'Unicode qui accommodent les caractères chinois ne connaissent en général que l'ASCII 7 bits en dehors desdits caractères. C'est en particulier vrai pour Shift-JIS. Et comme il s'agit d'une page Web, la réalisation d'Unicode est UTF-8 et non UTF-16 (encore moins UTF-32 !).
- [facile] Que se passe-t-il ? Un virus ? Que puis-je
faire ?
Un virus n'est jamais exclu ! Mais en l'occurrence il s'agit vraisemblablement d'une page qui ne mentionne pas le codage qu'elle utilise, ledit codage n'étant pas celui que le navigateur emploie par défaut. Cete situation a été abondamment illustrée dans le cours et dans les examens de années précédentes...
Le remède et d'essayer un autre codage dans le menu ad hoc du navigateur, comme illustré ici.
En pratique, un ou deux essais suffisent.
Mais on peut essayer de prédire le résultat...
- [moins facile] Donnez un diagnostic précis et assuré,
en
analysant les particularités du résultat ci-dessus, notamment que, dans
chaque ligne, les octets de rang impair sont
presque tous "incompris" et marqués par cet horrible point
d'interrogation dans un losange noir (en comptant le rang à
partir
de 1).
Prenons la première ligne : jusqu'au rang 14, on observe une alternance de
- au rangs impairs, des points d'interrogation
- aux rangs pairs, des caractères ASCII ou des points d'interrogation.

01 03 05 07 09 11 13 15 17 19 21 23
Au rang 16 apparaît un caractère inconnu du commun des mortels, certainement pas ASCII
(c'estU+050E,CYRILLIC CAPITAL LETTER KOMI TJE).
Même observation pour la ligne 2, où apparaît au rang 8 un caractère non-ASCII
(le signe diacritiqueU+030F COMBINING DOUBLE GRAVE ACCENT) :

1 3 5 7 9
idem pour toutes les autres lignes. Qu'en déduire ?
Chaque point d'interrogation correspond à un octet que le navigateur n'a pas su interpréter, donc à un octet non-ASCII.
Nous avons donc affaire à un codage où les octets de rang impair sont systématiquement non-ASCII,
et où les octets de rang pair sont ASCII ou non.
Ceci suggère un codage sur deux octets, et comme nous sommes en contexte japonais, au codage Shift-JIS
qui présente justement cette particularité, comme expliqué dans le cours n°3.
L'autre codage japonais présenté en cours, ISO-2022-JP, est exclu.
Pour être complet, il faudrait exclure aussi la possibilité du codage EUC-JP, ce qui sort du cadre d'un examen sans accès au réseau.
Mais auparavant, il faut expliquer l'apparition de caractères non-ASCII comme 'Ԏ' dans la première ligne,
la présence d'octets ASCII apparemment de rang impair comme 'W' et 'j' dans la même ligne,
et les comptages de 21 et de 11 pour les deux lignes examinées, qui viennent contredire notre hypothèse d'un codage sur deux octets.
- au rangs impairs, des points d'interrogation
- [encore moins facile] Expliquez les irrégularités
observées :
- comment se fait-il que certaines lignes aient un nombre
impair de signes ?
- que vient faire ce carré blanc désigné par la flèche
oblique ?
Mais ne cherchez pas d'explication au crochet ouvrant qui apparaît au début de l'avant-avant-dernière ligne,
sa présence n'est pas due à l'interprétation des octets, elle résulte d'un artefact de l'affichage dans une table de largeur fixe.
L'apparition de caractères exotiques s'explique de la même manière que l'irruption de caractères chinois dans un texte en français, illustré dans le cours n° 3. Le hasard fait qu'une séquence d'octets Shift-JIS est identique à une séquence d'octets du code adopté par le navigateur - avec probablement des séquences de 2 octets, mais qui pourraient être plus longues.
Dès lors, le navigateur affiche le caractère correspondant sans se poser de question... et du coup, le décompte des octets et faussé, puisqu'au moins 2 octets sont visualisés comme un seul caractère ! Ceci explique à la fois la présence de caractères ASCII à des rangs apparemment impairs (mais qui sont en fait de rang pair) et les valeurs impaires de 21 et 11 des comptages de nos deux lignes.
Vérification complète
(URL de la page japonaise, pour vos propres expérimentations :http://www.j-texts.com/sheet/h7bu.html)
Les octets de la première ligne en Shift-JIS (le titre affiché reproduit l'intitulé du lien...) :
俳 諧 七 部 集 ( 芭 蕉 七 部 集 ) 946FE67E8EB595948F578169946D8FD48EB595948F57816A? o
? ~
? ?
? ?
? W
? i
? m
? Ԏ ?? ?
? ?
? j
On voit en effet apparaître à la frontière entre les kanjis 蕉 et 七 le coupleD48E, qui se trouve être le code UTF-8 de
U+050E,CYRILLIC CAPITAL LETTER KOMI TJE.
Le codage employé par défaut par notre navigateur est donc UTF-8.
Quant au carré blanc indiqué par la flèche verte, à la différence du losange noir il signale une séquence d'octets reconnue comme un caractère valable, mais pour lequel aucune police n'est disponible sur la machine concernée. Il apparaît immédiatement à droite d'une lettre latine accentuée (difficile à lire) due au même phénomène que ci-dessus, qui "consomme" 2 octets. Avant lui ne se voient que des points d'interrogation et des ASCII, et deux octets après lui se montre l'ASCII 'B' qui est nécessairement de rang pair. Par conséquent, la séquence d'octets correspondant au carré blanc doit être de longueur paire, à savoir 2 ou 4. Impossible d'en dire plus à ce stade.
Allons voir !
( 自 己 解 凍 式 。 81698EA98CC889F093808EAE8142? i
? ?
? ȉ 𓀎 ?
? B
À la frontière entre les kanjis 己 et 解 apparaît le couple d'octetsC889, qui est le code UTF-8 de
U+0209 LATIN SMALL LETTER I WITH DOUBLE GRAVE(que j'ai grossi pour qu'on le reconnaisse),
et après lui les quatre octetsF093808E, code UTF-8 du caractèreU+1300E.
Ce dernier se trouve dans le bloc des hiéroglyphes égyptiens, catalogués par Unicode 5.2.
Effectivement, il n'y a pas de police pour ce bloc sur ma machine !
- comment se fait-il que certaines lignes aient un nombre
impair de signes ?
Pour Sherlock Holmes
Une étudiante de M2 m'a apporté un jour le billet ci-contre, en me disant "c'est curieux". En effet ! Je le soumets à votre sagacité. Qu'en pensez-vous ? Pour vous mettre sur la voie... notez que le caractère pointé par la flèche est un caractère graphique, aujourd'hui sorti de l'usage.
U+222B.) |
 |
ainsi qu'un '
Ç' majuscule là où on attendrait le signe '€'.Dans quels systèmes de codage a-t-on utilisé des caractères graphiques en même temps que des lettres grecques ?
Un seul est exposé dans le cours, la Code Page CP437. Voyons...
Dans cette page,
- θ correspond à l'octet
E9, il apparaît à la place de e accent aigu ;
- Ω correspond à l'octet
EA, il apparaît à la place de e accent circonflexe ; Çcorrespond à l'octet80, il apparaît à la place de€;- le caractère graphique correspond à l'octet
F4, il apparaît à la place de o accent circonflexe.
- e accent aigu =
E9;
- e accent circonflexe =
EA; €=80;- o accent circonflexe =
F4.
mais à laquelle on a envoyé un fichier codé en Windows-1252.
Élémentaire, mon cher Watson !
Hameçonnage
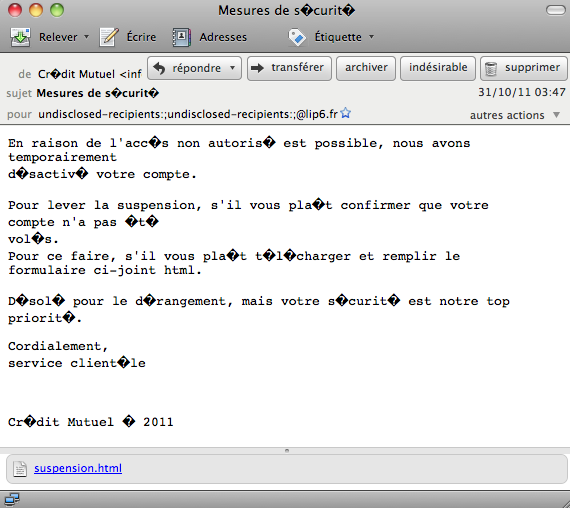
Quel superbe exemple de phishing !
- Pour comprendre les causes de cet affichage étrange,
j'examine le code-source du message.
En voici un extrait, où les mentions significatives sont encadrées :
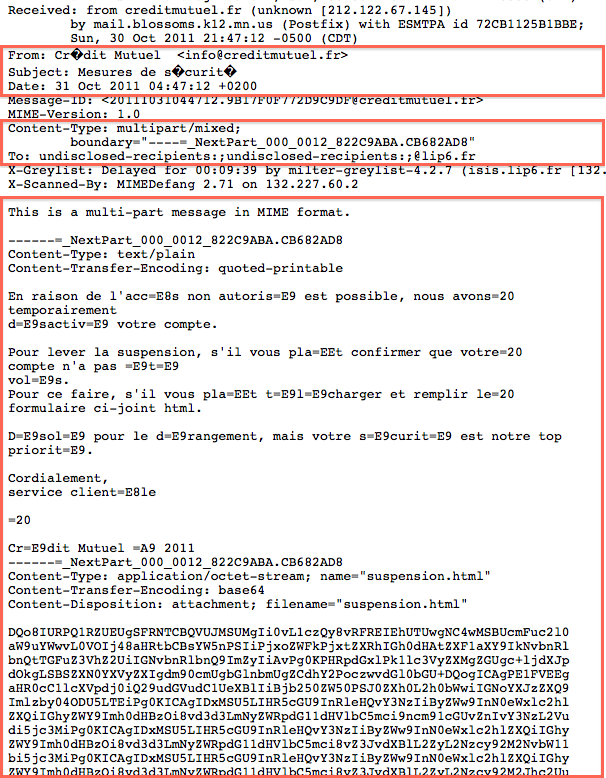
Cet extrait vous suffit-il pour expliquer l'affichage du message ?
Oui, bien sûr !
Décrivons d'abord ce qui demande explication dans cet affichage.
Comme on sait, il ya deux parties dans un message transmis par SMTP, qui ne suivent pas les mêmes lois : les en-têtes et le corps du message. Dans la visualisation que donne le logiciel de courrier (ce n'est pas un navigateur !) ces deux parties sont séparées par une ligne horizontale. Dans ces deux parties on voit de très vilains losanges noirs portant des points d'interrogation blancs, à la place de caractères non-décodés. C'est la présence de ces losanges noirs dont il faut rendre compte.
Pour les en-têtes, l'origine des losanges noirs se trouve au début de l'extrait du code-source, dans les champsFrometSubject:
on y voit les mêmes losanges noirs, qui dénotent des caractères non-ASCII alors que (quitte à être explicitement codés comme décrit au cours n°3) les contenus de ces champs doivent être en ASCII 7 bits.
Pour le corps du message c'est tout différent. Aucun losange noir dans le code-source !
Notons d'abord que seule nous intéresse la partie contenue entre les deux lignes séparatrices
------=_NextPart_000_0012_822C9ABA.CB682AD8
car ce qui suit représente le fichier attaché "suspension.html" qui ne nous pose aucun problème de visualisation.
Cette partie est responsable du texte affiché dans la fenêtre principale. Elle spécifie le mode de transmission (Transfer-Encoding),
en l'occurrence le mode quoted-printable, mais pas le codage des caractères du fichier (charset) !
Du coup le corps du message est dûment codé en ASCII, mais le logiciel ne sait pas comment interpréter le quoted-printable,
il utilise donc son codage par défaut, qui n'est pas celui du message, d'où les losanges noirs.
Comme d'usage, les caractères ASCII sont décodés correctement, tous les autres sont caviardés.
On peut aller plus loin, et juger que ce codage par défaut est probablement UTF-8, en tout cas pas un codage à 8 bits comme MacRoman : dans ce dernier cas, il aurait interprété à sa manière le quoted-printable, par exemple 'È' pour l'octetE9.
Quant au codage d'origine, il est facile à déceler au vu de la traduction en quoted-printable : c'est Latin-1 ou Windows-1252. - En relisant plus attentivement le code-source, je tombe sur
cette indication bizarre :

Comment l'interpréter ?
Vu les interprétations fantaisistes que j'ai dû lire, il n'est pas inutile de traduire :
EN-TÊTE INCORRECT, contenant des données en 8 bits non codées (caractère E9 en hexadécimal)
Cet avis concerne non le corps du message, mais l'en-têteFrom, qui en bonne règle devrait être entièrement en ASCII,
et au besoin codé en ASCII.
Ici, il contient un e accent aigu qui a été dûment caviardé.
On nous dit en plus que ce caractère non-ASCII était codé par l'octetE9: cela est même dit deux fois,
- par
char E9 hex - par
Cr\351dit, où le e accent aigu est donné en octal :0351=233=0xE9.
Au passage, on note que le logiciel Amavis aurait dû signaler que l'en-têteSubjectégalement violait la règle.
Peut-être s'est-il abstenu parce qu'il s'agissait du même e accent aigu ?
Enfin, le fait que ce diagnostic soit posé par un logiciel censé traquer les virus ne signifie nullement qu'un virus ait été détecté !
- par
- Je sauvegarde le code-source en question dans un fichier
ExMail.txt, et lorsque je veux ouvrir ce fichier avec mon éditeur favori, ce dernier proteste :
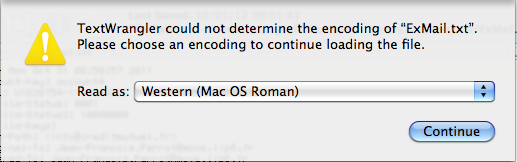
Quel codage dois-je choisir ?
N'oubliez pas d'expliquer les raisons de votre choix !
Avant de résoudre le problème, prenons-en l'exacte mesure : ce qui embarrasse TextWrangler ici, ce n'est pas les lettres accentuées du corps du message, puisqu'elles sont codées en ASCII quoted-printable, mais les 3 e accent aigu des en-têtes
FrometSubject, qui eux se manifestent par 3 octetsE9. Tout les reste du fichier est en ASCII (y compris l'attachement donné en base64).
Le choix est donc entre Latin-1 et Windows-1252, il est sans conséquence...