Cryptographie
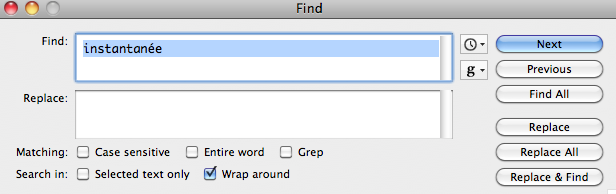
Lorsqu'un éditeur de textes ouvre un fichier en se trompant d'encodage, le résultat peut être surprenant.- Quand vous lisez (attention ! les '
Ã' sont desLATIN CAPITAL LETTER A WITH TILDE) :
Ça, c'était mon frère René (à gauche, près de la fenêtre) et ça c'était ma sœur Iñès.
que concluez-vous sur
- le codage original du fichier
- le réglage de l'éditeur
L'allure générale du texte montre que de lettres accentuées du français sont remplacées par des digrammes bizarres. Cette situation est caractéristique d'un texte codé en utf-8 et lu avec un codage des caractères sur un seul octet. Nous faisons donc l'hypothèse codage original en utf-8, cette hypothèse devant être validée par la découverte du codage sur 8 bits employé par l'éditeur et par la vérification de la correspondance octet par octet.
- Selon notre hypothèse, le 'e accent aigu' était
représenté dans le fichier par les octets
C3A9(utf-8) - Dans le codage de l'éditeur, l'octet
C3code le caractèreLATIN CAPITAL LETTER A WITH TILDE;
parmi les deux systèmes sur 8 bits en usage courant (Windows1252/Latin-1 et MacRoman), c'est le premier qui a cette propriété.
- Pour confirmer notre trouvaille, voyons le second octet :
A9doit donner le caractère "copyright", c'est bien le cas. - Voyons les autres digrammes :
- 'e accent grave' =
C3A8en utf-8, devient "A tilde + tréma" en Windows1252/Latin-1 - 'e accent circonflexe' =
C3AAen utf-8, devient "A tilde +FEMININE ORDINAL INDICATOR"
- 'a accent grave' =
C3A0en utf-8, devient "A tilde + espace insécable" ce qui explique l'espacement dans "(Ã gauche," - 'c cédille' minuscule =
C3A7, majuscule =C387, deviennent respectivement "A tilde + paragraphe"DOUBLE DAGGER", mais ce dernier n'existe qu'en Windows1252, il est exclu de la normalisation en Latin-1 : le codage d'origine était donc Windows1252. - 'n tilde' =
C3B1devient "A tilde + plus-ou-moins" en Windows1252/Latin1 - enfin 'o-e mêlés' =
C593devient "angström +LEFT DOUBLE QUOTATION MARK", en Windows1252 seulement.
- 'e accent grave' =
- Notre théorie utf-8/Windows1252 explique ainsi de manière
satisfaisante tous les phénomènes observés,
nous la tenons donc pour validée par l'expérience.
- le codage original du fichier
Ça, c'était mon frère René (à gauche,
près de la fenêtre) et ça c'était ma sœur Iñès.que concluez-vous ?
Il s'agit probablement du même fichier, lu avec
un autre
codage sur 8 bits. Nous suivons la même démarche qu'à la question
précédente : avec quel système l'octet
C3 correspond-il
au signe "racine carrée" ? Dans la table MacRoman ! Il ne nous reste
plus qu'à vérifier les correspondances dans
cette table :
-
A9-> 'copyright', -
A8-> 'marque enregistrée', -
AA->'marque déposée', -
A0->'DAGGER', -
A7->'eszett' allemand (ß, pas un β bêta grec), -
87->'a accent aigu', -
B1->'plus-ou-moins', comme précédemment ! - et enfin
C593-> "ALMOST EQUAL TO+ i accent grave".
Ãa, c'était mon frère René (Ã
gauche, près de la fenêtre) et ça c'était ma sÅur Iñès.et avec cette autre ?
Ãa, c'était mon frÚre René (Ã
gauche, prÚs de la fenêtre) et ça c'était ma sÅur IñÚs.N.B. Les caractères de contrôle ne sont pas traités de la même manière par OpenOffice et par les navigateurs : l'un en marque la place par un symbole spécial, les autres n'écrivent rien du tout. Reportez-vous donc à l'énoncé en pdf pour bien comprendre cette question !
On voit que les caractères propres à Windows1252
(le
Dans le premier cas, cette disparition est la seule différence avec la situation de la question 1. Nous avons donc affaire à un éditeur qui lit en Latin-1.
Dans le second cas, il y a en plus le tréma remplacé par
DOUBLE
DAGGER et le LEFT DOUBLE QUOTATION MARK) sont
remplacés ici par des caractères de contrôle. Dans le premier cas, cette disparition est la seule différence avec la situation de la question 1. Nous avons donc affaire à un éditeur qui lit en Latin-1.
Dans le second cas, il y a en plus le tréma remplacé par
LATIN
SMALL LETTER S WITH CARON. Il s'agit très probablement d'un de
codes ISO-8859, mais lequel ? D'après les exemples donnés dans le cours
n°3, ce pourrait être ISO-8859-2, mais dans cette table la lettre en
question est codée par l'octet B8 et non par A8.
Il s'agit en fait du code ISO-8859-15, alias Latin-9, le seul avec
lequel on peut écrire le français correctement...L'idée est de sauvegarder le texte avec un codage sur 8 bits qui utilise tous les octets au-delà de 128, de transmettre le message ainsi codé dans son codage 8 bits, puis d'ouvrir le fichier transmis en UTF-8.
- Pourquoi cette restriction sur le choix du codage ?
Se limiter à des systèmes d'écriture non-latins a pour but d'éliminer tout caractère ASCII, afin d'assurer l'opacité du message crypté. Il est alors naturel d'adopter UTF-8. Pour le cryptage, on est obligé d'utiliser un codage sur 8 bits où tous les octets sont employés sous peine de voir l'éditeur refuser la conversion de certains messages :
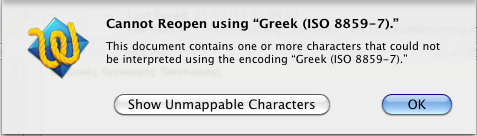
Il n'y a que deux tels systèmes en usage courant, Windows1252 et MacRoman.
Il faut noter que le but que nous poursuivons ici n'est pas conforme au cahiser des charges ordinaire d'un éditeur de textes. Nous sommes donc à la merci de comportements difficiles à prévoir : par exemple, l'éditeur va-t-il afficher des "caractères de contrôle", comme en 3. ci-dessus, ou bien refuser tout net l'affichage ? Le choix d'un codage où tous les octets sont employés réduit le risque de refus pour cause de unmappable characters.
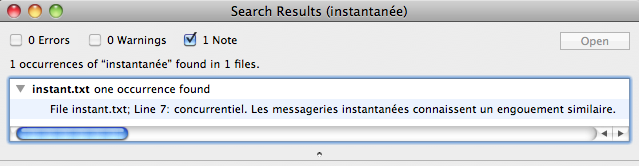
- Voici un exemple de message codé
Ελληνικός Οργανισμός Τυποποίησης
Comment faire pour le déchiffrer ?
Si nous savions avec quel codage 8 bits ce message a été écrit, le déchiffrage serait immédiat : il suffirait de sauvegarder le message dans un fichier avec le même codage, puis d'ouvrir ce fichier avec un éditeur lisant par défaut en UTF-8.
Expliquons ce point, en appelant X le codage 8 bits choisi pour le cryptage.
- Les octets de la rédaction initiale en UTF-8 ont été
fidèlement conservés par la conversion en codage X : à chaque octet a
été associé le caractère correspondant selon X.
Tous ces octets sont au-delà de 128 (propriété essentielle d'UTF-8 hors de la zone ASCII). Ce caractère existe bien (pas de refus d l'éditeur) en raison de l'hypothèse que X utilise tous les octets au-delà de 128,
- Le tout a été transmis, sans doute à travers un recodage
en quotetd-printable ou en base64, peu importe car le
système de courrier garantit la restitution du texte dans son codage
d'origine X.
- La sauvegarde dans un fichier F avec le codage X
conserve les octets.
- Le fichier F contient donc exactement la même séquence
d'octets que le message initial lors de sa rédaction en UTF-8. Rien
dans son contenu ne différencie F d'un fichier en UTF-8 "natif".
- L'éditeur de textes lisant les octets l'un après l'autre
et leur appliquant (par défaut) l'algorithme UTF-8 retrouve donc les
caractères d'origine et reproduit le messsage.
Par exemple, si je vous dis que le message suivant est codé en Windows1252 :
Ελληνικός
vous lui associez immédiatement la séquence d'octets
CE95CEBBCEBBCEB7CEBDCEB9CEBACF8CCF82
qui aux yeux de n'importe quel lecteur qui attend de l'UTF-8 se déchiffre comme
Ελληνικός
Mais voila, je ne vous ai pas dit comment était codé le message de l'examen !
Pour le trouver, il faut raisonner un peu.
- On sait que le message est en utf-8, mais on
ignore avec quel système
d'écriture (arabe, grec, chinois...).
- On sait aussi qu'à l'intérieur d'un même bloc Unicode, la plupart des codes UTF-8 ont la même longueur (2, 3 ou 4) et commencent par le même octet ou par des octets voisins - les ponctuations pouvant causer du désordre. En effet, sur un code à deux octets, on a (au plus) 26 = 64 caractères qui partagent le même octet initial dans leur code utf-8, donc 128 dont les octets initiaux diffèrent d'au plus 1, etc.
- Ici, on observe que tous les octets de rang impair sont
représentés
soit par '
Œ' majuscule, soit par 'œ' minuscule. - Nous avons donc très probablement affaire à des codes
UTF-8 de deux
octets, déguisés dans un code sur 8 bits X où les deux lettres en
question ( '
Œ' majuscule et 'œ' minuscule) sont associées à deux octets "proches". En Windows1252, nos deux compères sont codés par8Cet9Crespectivement, soit une différence de 16, tandis qu'en MacRoman les octets sontCEetCF=CE+1. La cause est donc entendue, il s'agit de MacRoman.
Dès lors il suffit de lire la table MacRoman pour reconstituer les octets... ou tout simplement, si on dispose du fichier codé en MacRoman, de l'ouvrir avec un éditeur hexadécimal :
jfp% hexdump -C msg.mac
00000000 ce 95 ce bb ce bb ce b7 ce bd ce b9 ce ba cf 8c |................|
00000010 cf 82 20 ce 9f cf 81 ce b3 ce b1 ce bd ce b9 cf |.. .............|
00000020 83 ce bc cf 8c cf 82 20 ce a4 cf 85 cf 80 ce bf |....... ........|
00000030 cf 80 ce bf ce af ce b7 cf 83 ce b7 cf 82 |..............|
0000003e
et si on le lit avec un outil qui s'attend à trouver de l'utf-8, on voit apparaître
Ελληνικός Οργανισμός Τυποποίησης
C'était donc du grec ! Traduction : Organisation hellénique de normalisation.
Pièce à conviction : Le message tel que l'affiche Thunderbird et l'essentiel du texte-source montrant son habit de voyage.
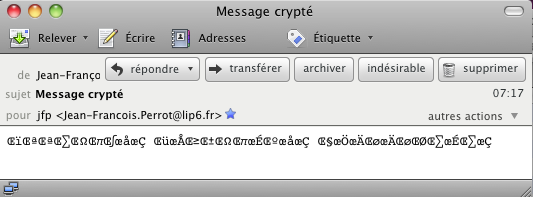


NB. Faites l'expérience vous-même ! Attention, pour passer d'une lecture à l'autre des mêmes octets, donc du même fichier sur le disque, utilisez la fonction "Reopen using encoding..." de votre éditeur. En effet, la sauvegarde dans un autre codage - si elle est possible - va conserver les caractères et changer les octets !
- Les octets de la rédaction initiale en UTF-8 ont été
fidèlement conservés par la conversion en codage X : à chaque octet a
été associé le caractère correspondant selon X.