On ne transcode jamais assez...
Je reçois d'un organisme officiel une missive électronique (email) dans laquelle je relève des points d'interrogation qui me paraissent menaçants :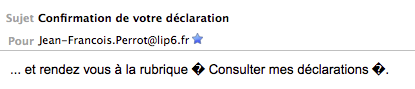
- À la seule lecture de ce fragment, quelles hypothèses
formulez-vous pour expliquer ces points d'interrogation incongrus ?
La présence de deux losanges noirs portant un point d'interrogation signale que deux octets ont été jugés indécodables par le logiciel de courrier. Comme il s'agit d'un seul octet à chaque fois, il est probable que ce logiciel ait attendu de l'UTF-8 et qu'il ait reçu un octet non-valable : en effet, si le logiciel avait attendu un code à 8 bits, soit il aurait proposé une interprétation pour ces octets, soit il les aurait passés sous silence (cas des octets inutilisés en Latin-1).
L'examen du code-source devrait confirmer ou infirmer cette hypothèse.
- J'extrais du code-source du message les informations que
voici :
To: Jean-Francois.Perrot@lip6.fr
Subject: =?UTF-8?Q?Confirmation_de_votre_d=C3=A9claration?=
Content-Type: text/html; charset=UTF-8
Content-Transfer-Encoding: quoted-printable
<table style=3D"font-family: Arial,Helvetica,sans-serif; font-size: 12px;" =
border=3D"0" cellpadding=3D"1" cellspacing=3D"1" width=3D"770"><tr><td>
et rendez vous à la rubrique =AB C=
onsulter mes déclarations =BB.<br>
</td></tr></table>
L'image affichée est-elle conforme aux indications du code-source ?
Nous savons à présent que
- le message est effectivement codé en UTF-8,
- et qu'il est transmis en quoted-printable.
é=C3A9).
Le corps du message est constitué d'une table HTML à une seule cellule qui contient un texte entièrement en ASCII.
N.B. Que ce contenu soit du HTML ne change rien aux questions de codage. Le "text/html" est restitué exactement comme le serait du "text/plain", d'abord par décodage du format quoted-printable pour obtenir une chaîne d'octets, ensuite par interprétation de ces octets conformément au charset pour donner un chaîne de caractères. Le texte HTML ainsi obtenu est enfin affiché par le mailer comme le ferait un navigateur. Obersvons au passage que toute la syntaxe HTML est exprimée en ASCII...
Dans ce texte, les lettres accentuées sont réalisées comme des entités HTML (àeté) et non pas via leurs octets en quoted-printable ( qui seraient=C3=A0et=C3=A9).
En revanche, on voit apparaître deux octets isolésABetBBqui ne sont pas des octets ASCII, et qui par conséquent ne sont pas de l'UTF-8 (puisque en UTF-8 les seuls codes d'un seul octet sont les codes ASCII) : ce sont eux qui ont été affichés comme les losanges noirs portant un point d'interrogation.
D'où viennent-ils ? Selon toute vraisemblance, d'une version initiale du texte codée en Latin-1, car dans cette table ces deux octetx codent les guillemets ouvrants et fermants, qui sont exactement ce qu'on attend dans le texte à la place de ces octets.
Lors du recodage en UTF-8, les lettres accentuées ont été converties en entités HTML, mais les guillemets sont restés...
Quant à la coupure surprenante dans "Consulter...", c'est seulement un saut de ligne arbitraire destiné à éviter des lignes trop longues.
Il fait partie de la mécanique du quoted-printable : voyez Wikipédia.
Donc en somme oui, l'image affichée est parfaitement conforme aux indications du code-source.
- le message est effectivement codé en UTF-8,
- À coup sûr, le messsage en question a été engendré par un
programme, et non rédigé par un employé aux écritures.
Quelle recommandation formuleriez-vous à l'intention des informaticiens responsables de ce programme, si votre expertise était sollicitée pour améliorer la qualité du service rendu ?
Je proposerais de choisir entre deux stratégies :
- Recoder le corps du message tout en UTF-8, sans entités,
en recodant tous les caractères non-ASCII : les guillemets deviennent
alors
C2ABetC2BB. - Recoder tout en ASCII, avec entités, en particulier
«et»pour les guillemets.
- Recoder le corps du message tout en UTF-8, sans entités,
en recodant tous les caractères non-ASCII : les guillemets deviennent
alors
Aller-retour
Je lis sur la page d'une estimable société savante :
- Quelles réflexions vous inspire ce libellé ?
A priori, il s'agit d'un fragment "Journée Epopée-2013 Programme" écrit en UTF-8, lu avec un logiciel attendant du Latin-1 :
les octetsC3A9codant en UTF-8 le "e accent aigu minuscule" sont en effet lus en Latin-1 comme "A tilde majuscule" et "copyright".
- La lecture du code-source (HTML) fait d'abord apparaître
l'en-tête
<html lang="fr-FR">
<head>
<meta charset="UTF-8" />
et pour le passage concerné :
<div class="entry-summary">
<p>Une journée d’étude sur l’épopée aura lieu le 28 novembre. Vous trouverez le programme ici : Journée Epopée-2013-Programme</p>
</div><!-- .entry-summary -->
Quelles nouvelles réflexions vous suggère cette information supplémentaire ?
Eh bien non ! La page est codée en UTF-8, et les séquences aberrantes "é" sont "en dur" dans le texte-source.
La transformation qui les a fait apparaître a donc eu lieu avant l'insertion du fragment dans la page.
Ce fragment devait porter un lien hypertexte qui a disparu dans l'affaire.
On note que l'apostrophe est réalisée par l'entité HTML "right single quotation mark", c'est-à-dire par le caractèreU+2019, et non par le caractère moins lointainU+02BC,MODIFIER LETTER APOSTROPHE. En Windows 1252, ce qui sert d'apostrophe, (octet92) est effectivement le "right single quotation mark". Mais pourquoi choisir une entité dans un texte en UTF-8 ?
Il faudrait un extrait plus abondant pour formuler une conjecture sur le procédé qui a engendré ce texte...
Une vieille histoire
Je reçois l'annonce d'une soutenance de thèse, dont voici un extrait où j'ai entouré quelques accidents :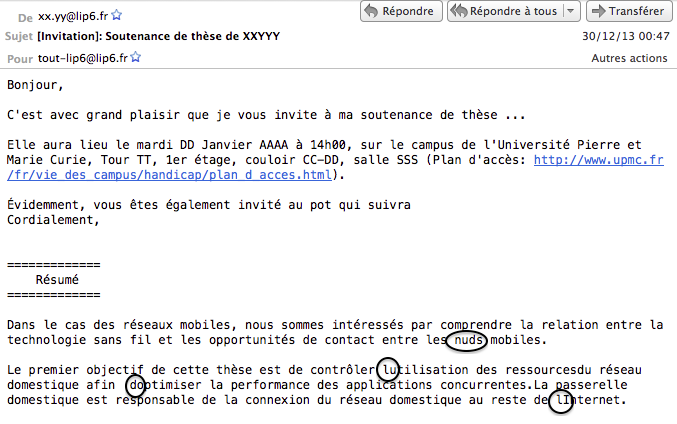
- Intrigué, je vais examiner le texte-source du message, dont
voici le début
Date: Mon, 30 Dec 2013 00:47:07 +0100
From: xx.yy@lip6.fr
To: tout-lip6@lip6.fr
Subject: [Invitation]: Soutenance de =?iso-8859-15?b?dGjoc2U=?= de XXYYY
Content-Type: text/plain;
charset=ISO-8859-15;
format="flowed"
Content-Disposition: inline
Content-Transfer-Encoding: 8bit
User-Agent: Internet Messaging Program (IMP) H3 (4.3.11)
Bonjour,
C'est avec grand plaisir que je vous invite ‡ ma soutenance de thËse
...
Elle aura lieu le mardi DD Janvier AAAA ‡ 14h00, sur le campus de
l'UniversitÈ Pierre et Marie Curie, Tour TT, 1er Ètage, couloir CC-DD,
salle SSS (Plan d'accËs:
http://www.upmc.fr/fr/vie_des_campus/handicap/plan_d_acces.html).
…videmment, vous Ítes Ègalement invitÈ au pot qui suivra
Cordialement,
Je suis surpris... Et vous ?
La surprise provient de l'écart entre ce que montre l'image et ce qu'on lit dans le code-source.
Bien sûr, on ne s'attend pas à deux paysages identiques, mais normalement on trouve dans le code-source des indications de codage qui permettent de le comprendre.
Or ici, que voyons-nous ?
- Le texte est en iso-8859-15, alias Latin-9,
une variante de Latin-1 qui
possède la ligature "e dans l'o".
C'est dit une première fois dans le champ "Subject", où on trouve un fragment codé=?iso-8859-15?b?dGjoc2U=?=,
d'où on conclut que la chaînedGjoc2Udoit être l'écriture en Base64 des octets74 68 E8 73 65(=thèseen Latin-9 comme en Latin-1) - on le vérifie facilement.
Et c'est réaffirmé par l'indication ultérieurecharset=ISO-8859-15;.
Fort bien,
- Il est transmis avec
Content-Transfer-Encoding: 8bit, c'est-à-dire que les octets sont tous transmis tels quels.
Effectivement, le nombre de caractères dans la partie "contenu" du texte-source est identique au nombre de caractères lus dans la plage correspondante de l'image.
(S'il avait été transmis en quoted-printable, chaque lettre accentuée de l'image aurait correspondu, au contraire, à trois caractères dans le texte-source.)
Seulement, les caractères du code-source qui correspondent aux lettres accentuées de l'image sont bizarres !
- Nous en déduisons que le code-source a été lu par un
logiciel qui attendait un codage autre que Latin-9. Lequel ?
- comme tous les octets sont interprétés (aucun de ces
losanges noirs portant un point d'interrogation que nous avons vus à la
question 1), c'est un code à 8bits ;
- puisque le e accent aigu minuscule est lu
comme un e accent grave majuscule, c'est très probablement
MacRoman ;
en effet, Latin-9 ne diffère de Latin-1 que sur quelques caractères, qui ne figurent pas dans notre extrait ;
les observations faites en cours (et en TD) sur l'apparence de Latin-1 lu en MacRoman restent valables (une vieille histoire !).
- comme d'usage, nous confirmons le diagnostic avec la
série de correspondances :
Latin-1
octet
MacRoman
à
E0
‡
è
E8
Ë é
E9
È É
C9
…
ê
EA
Í
Il n'y avait donc pas lieu d'être surpris... surtout de la part d'un utilisateur de Macintosh !
- comme tous les octets sont interprétés (aucun de ces
losanges noirs portant un point d'interrogation que nous avons vus à la
question 1), c'est un code à 8bits ;
- Le texte est en iso-8859-15, alias Latin-9,
une variante de Latin-1 qui
possède la ligature "e dans l'o".
- Suite du texte-source :
=============
RÈsumÈ
=============
Dans le cas des rÈseaux mobiles, nous sommes intÈressÈs par comprendre la
relation entre la technologie sans fil et les opportunitÈs de contact
entre les núuds mobiles.
Le premier objectif de cette thËse est de contrÙler líutilisation des ressources
du rÈseau domestique afin díoptimiser la performance des applications concurrentes.
La passerelle domestique est responsable de la connexion du rÈseau
domestique au reste de líInternet.
Cette fois, j'ai compris... Et vous ?
Au fait, que restait-il à comprendre ? Ah, oui ! les "accidents" entourés en noir sur l'image.
Ces accidents sont tous des disparitions : du "e dans l'o" pour la première, de l'apostrophe pour les trois autres.
Or, dans le texte-source, les caractères correspondants sont bien présents :úpour la première etípour les autres.
En MacRoman, les octets en jeu sont9Cet92, qui codent bien le "e dans l'o" et l'apostrophe... en Windows 1252 !
Mais dans tous les codes normalisés ISO-8859, ils appartiennent à la plage "inutilisée", ce qui explique leur disparition pure et simple à l'affichage.
Nous avons donc affaire à un texte qui a été à l'origine codé en Windows 1252, et qui s'est trouvé, à la légère, inséré dans un courrier en Latin-9.
Employer Latin-9 au lieu de Latin-1 est déjà un progrès vers une meilleure orthographe du français, mais si on part de Windows 1252 cela ne dispense pas d'un recodage ! L'octet9Caurait dû devenirBD(e dans l'o). L'apostrophe en revanche ne se trouve pas plus en Latin-9 qu'en Latin-1 : il faut donc revenir au "quote" (ASCII27). Voyez les commentaires sur Wikipedia.
Errare humanum est
En faisant des essais avec un de mes programmes, j'obtiens des résultats qui me paraissent significatifs.D'après mon programme, les trois chaînes d'octets suivantes :
61 6c 65 72 74 65 72 20 6c 65 20 6d 6f 64 e9 72 61 74 65 75 7275 6e 65 20 70 72 6f 74 68 e8 73 65 20 65 6e 20 70 6c 61 74 69 73 71 75 6527 4e 61 76 41 63 74 75 27 2c 20 27 50 72 e9 63 e9 64 65 6e 74 27 5d 29 3b
se lisent en Latin-1
alerter le modérateurune prothèse en platisque(sic)'NavActu', 'Précédent']);
et en UTF-8 (les caractères chinois sont grossis 3 fois)
alerter le mod象teurune proth粥 en platisque'NavActu', 'Pr褩dent']);
Joli, n'est-ce pas ? Mais... est-ce bien raisonnable ?
L'interprétation en Latin-1 est correcte, les
seuls octets non-ASCII
étant
L'interprétation en UTF-8 est plausible : chaque octet
Mais... il s'agissait alors du codage Shift-JIS, et non d'UTF-8. Or, dans le cas présent, aucun des trois triplets d'octets en cause n'est un triplet UTF-8 !
En effet, chacun d'entre eux contient en deuxième position un octet ASCII (respectivement
aucun des octets composant un code UTF-8 à plusieurs octets (c'est à dire, non-ASCII) ne commence par 0.
Il nous faut bien admettre que le programme se trompe, et que le prétendu résultat est faux !
D'ailleurs, la vérification est facile pour quiconque sait identifier les sinogrammes en question (le kanji 象 est d'usage courant en japonais) :
Note pour les curieux :
Le phénomène n'est pas dû à une erreur algorithmique, mais à l'absence de vérification que les données sont correctes.
Le programme calcule le n° Unicode à partir de la chaîne binaire "aveuglément", en se basant sur le premier octet et sans s'assurer que les octets suivants sont conformes.
D'où ce résultat plausible mais faux !
Voici le code (JavaScript) :
e9 (= 'é') et e8 (='è').L'interprétation en UTF-8 est plausible : chaque octet
e8
ou e9
est pris pour le début d'un triplet codant un caractère chinois. Chaque
caractère chinois remplace alors les 3 caractères Latin-1 commençant
par 'é' ou par 'è', à savoir :éra->e9 72 61-> 象,
èse->e8 73 65-> 粥,écé->e9 63 e9-> 褩.
Mais... il s'agissait alors du codage Shift-JIS, et non d'UTF-8. Or, dans le cas présent, aucun des trois triplets d'octets en cause n'est un triplet UTF-8 !
En effet, chacun d'entre eux contient en deuxième position un octet ASCII (respectivement
72, 73, et 63),
ce qui est contraire au principe
d'UTF-8 :aucun des octets composant un code UTF-8 à plusieurs octets (c'est à dire, non-ASCII) ne commence par 0.
Il nous faut bien admettre que le programme se trompe, et que le prétendu résultat est faux !
D'ailleurs, la vérification est facile pour quiconque sait identifier les sinogrammes en question (le kanji 象 est d'usage courant en japonais) :
- 象 =
U+8C61-->E8 B1 A1 - 粥 =
U+7CA5-->E7 B2 A5 - 褩 =
U+8929-->E8 A4 A9
Note pour les curieux :
Le phénomène n'est pas dû à une erreur algorithmique, mais à l'absence de vérification que les données sont correctes.
Le programme calcule le n° Unicode à partir de la chaîne binaire "aveuglément", en se basant sur le premier octet et sans s'assurer que les octets suivants sont conformes.
D'où ce résultat plausible mais faux !
Voici le code (JavaScript) :
// Interprétation en utf-8 d'une chaîne binaire
function utf8(chb) {
var res = "";
for ( var i=0; i<chb.length; i+=8 ) {
var val = parseInt(chb.substr(i,
8), 2); // 1er octet
if( val < 128 ){ // ASCII
res +=
String.fromCharCode(val);
}else if( val >= 240 ){ // 4
octets
contr1 =
(val-240) * 262144;
i += 8;
// 2ème octet
var val2
= parseInt(chb.substr(i, 8), 2);
contr2 = (val2-128) * 4096;
i += 8; // 3ème octet
var val3 = parseInt(chb.substr(i, 8), 2);
contr3 = (val3-128) * 64;
i += 8; // 4ème octet
var val4 = parseInt(chb.substr(i, 8), 2);
contr4 = val4-128;
res += String.fromCharCode(contr1+contr2+contr3+contr4);
}else if( val >= 224 ){
// 3 octets
contr1 = (val-224) * 4096;
i += 8; // 2ème octet
var val2 = parseInt(chb.substr(i, 8), 2);
contr2 = (val2-128) * 64;
i += 8; // 3ème octet
var val3 = parseInt(chb.substr(i, 8), 2);
contr3 = val3-128;
res += String.fromCharCode(contr1+contr2+contr3);
}else{ // 2 octets
contr1 = (val-192) * 64;
i += 8; // 2ème octet
var val2 = parseInt(chb.substr(i, 8), 2);
contr2 = val2-128;
res += String.fromCharCode(contr1+contr2);
}
}//for
return res;
}// utf8