Exemple
On prend comme fil conducteur la réalisation d'un tout petit programme
- qui prend comme donnée un fichier de texte en UTF-8
- et qui le transforme en un fichier HTML en ASCII pur
- où tous les caractères non-ASCII sont écrits sous forme d'entités HTML
- et où de surcroît les caractères appartenant aux plans supplémentaires sont en gras.
Kieu.txt),
où il s'agit de distinguer les caractères nôm des caractère chinois classiques - motivation issue du cours n° 4 :
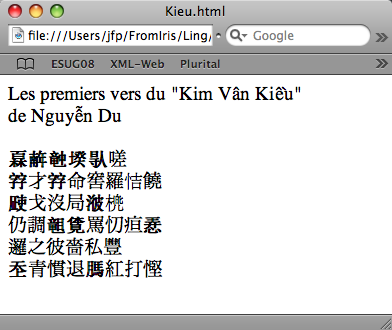
Les premiers vers du "Kim Vân Kiều"
de Nguyễn Du
𤾓𢆥𥪝𡎝𠊛嗟
𡦂才𡦂命窖羅恄饒
𣦆戈沒局𣷭橷
仍調𥉩𧡊罵忉疸𢚸
邏之彼嗇私豐
𡗶青慣退𦟐紅打慳et voici le résultat de la transformation (fichier
Kieu.html)
Les premiers vers du "Kim Vân
Kiều"
<br />
de Nguyễn Du
<br />
<br />
<b>𤾓</b><b>𢆥</b><b>𥪝</b><b>𡎝</b><b>𠊛</b>嗟
<br />
<b>𡦂</b>才<b>𡦂</b>命窖羅恄饒
<br />
<b>𣦆</b>戈沒局<b>𣷭</b>橷
<br />
仍調<b>𥉩</b><b>𧡊</b>罵忉疸<b>𢚸</b>
<br />
邏之彼嗇私豐
<br />
<b>𡗶</b>青慣退<b>𦟐</b>紅打慳
<br />et son interprétation par Safari :
Généralités
Programmer cette transformation demande
- de contrôler le codage des caractères du fichier d'entrée
- de lire ledit fichier ligne à ligne
- de trouver dans chaque ligne la séquence des numéros Unicode
- le reste va de soi (en principe, car nous verrons que la réaité est un peu plus compliquée...).
Afin de faciliter la comparaison, nos quatre réalisations suivront strictement le même patron, sans chercher une meilleure adaptation à chaque langage.
- Le cœur du programme est une fonction nommée
trans,
- qui prend comme argument un tableau de chaînes (en Unicode)
- qui renvoie comme résultat le tableau des chaînes
codées en ASCII, avec les éventuelles balises
<b>.
- Cette fonction est lancée par une autre fonction
extrans
- qui reçoit deux noms de fichiers, pour l'entrée et pour la sortie,
- qui lit le fichier d'entrée (en UTF-8) et convertit
son
contenu en un tableau de chaînes nommé
tab - qui appelle
trans(tab)avec comme résultat un tableau de chaînesres - et enfin transcrit le tableau
resdans le fichier de sortie.
Réalisation en Perl
Perl considère que les éléments d'une chaîne sont des caractères (et non pas des octets).
Il obtient le n° Unicode d'un caractère par la fonction
ord.Pour accéder aux différents caractères qui composent une chaîne, il convient de la transformer au préalable en un tableau par un appel à
split
sur séparateur vide : my @tabcar = split(//, $ligne);.Le transfert du contenu (lignes) d'un fichier de nom
$fichIn
dans un tableau @tab se fait par la séquenceopen(ENTREE, "<$fichIn");
@tab = <ENTREE>;Moyennant quoi notre programme s'écrit (fichier
utf8ToHTML.pl)use strict;
use warnings;
use open ':utf8';
sub trans (\@){ # arg. tableau de lignes , renvoie un tableau de lignes
my ($tablignes) = @_ ;
my @rtab;
my $k = 0;
foreach my $ligne ( @$tablignes ){
my @tabcar = split(//, $ligne);
my $rligne = "";
foreach my $car ( @tabcar ){
my $nb = ord($car); # décimal
if( $nb < 128 ){ # ASCII
$rligne .= $car;
}elsif( $nb < 65536 ){ # BMP
$rligne .= "&#".$nb.";";
}else{ # Plan supplémentaire
$rligne .= "<b>&#".$nb.";</b>";
}
}
$rtab[$k] = $rligne."<br />\n";
$k++;
}
return @rtab;
} # trans
sub extrans($$){ # arg 2 noms de fichier
my ($fichIn, $fichOut) = @_ ;
open(ENTREE, "<:utf8", $fichIn); # UTF-8
open(SORTIE, ">$fichOut"); # ASCII
my @tab = <ENTREE>;
my @res = trans(@tab);
foreach my $lgn ( @res ){
print(SORTIE "$lgn");
}
} # extrans
extrans($ARGV[0], $ARGV[1]); # en ligne de commande
L'exécution de ce programmme par
jfp% perl utf8ToHTML.pl Kieu.txt Kieu.html
donne exactement le résultat attendu.
Réalisation en PHP-5
Nous passerons de Perl à PHP-5 en deux temps :
- d'abord les questions de syntaxe, superficielles mais incontournables
- ensuite les questions de fond
.
ord qui
donne le n° d'un caractère, mais contrairement à Perl il sait accéder
au caractère de rang i dans une chaîne par
une notation indexée (avec accolades) : $car = $ligne{$i};.Le transfert du contenu (lignes) d'un fichier de nom
$fichIn
dans un tableau $tab se fait en une seule
instruction
$tab = file($fichIn);Moyennant quoi notre programme Perl se traduit "mécaniquement" en PHP comme suit (fichier
utf8ToHTML.php)
:<?php
function trans ($tablignes){ // arg. tableau de lignes , renvoie un tableau de lignes
$k = 0;
$rtab = array();
foreach ( $tablignes as $ligne ){
$rligne = "";
for( $i=0; $i<strlen($ligne); $i++ ){
$car = $ligne{$i};
$nb = ord($car); // décimal
if( $nb < 128 ){ // ASCII
$rligne .= $car;
}else{
if( $nb < 65536 ){ // BMP
$rligne .= "&#".$nb.";";
}else{ // Plan supplémentaire
$rligne .= "<b>&#".$nb.";</b>";
}
}
}
$rtab[$k] = $rligne."<br />\n";
$k++;
}
return $rtab;
} // trans
function extrans($fichIn, $fichOut){ // arg 2 noms de fichier
$SORTIE = fopen($fichOut, "w");
$tab = file($fichIn);
$res = trans($tab);
foreach( $res as $lgn ){
fputs($SORTIE, $lgn);
}
} // extrans
extrans($argv[1], $argv[2]);
?>
L'exécution par
jfp% php utf8ToHTML.php Kieu.txt Kieu.html
s'effectue sans erreur, mais... elle ne donne pas exactement le résultat attendu.
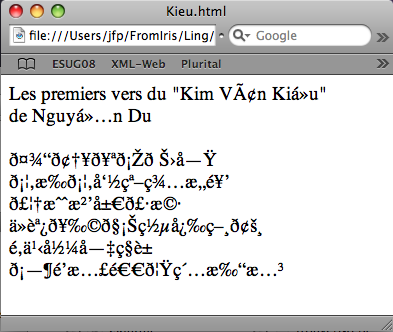
Les premiers vers du "Kim
Vân
Kiều"
<br />
de Nguyá»…n Du
<br />
<br />
𤾓𢆥𥪝𡎝𠊛嗟
<br />
𡦂才𡦂命窖羅恄饒
<br />
𣦆戈沒局𣷭橷
<br />
仍調𥉩𧡊罵忉疸𢚸
<br />
邏之彼嗇私豐
<br />
𡗶青慣退𦟐紅打慳
<br />Que s'est-il passé ?
Tout bonnement que PHP-5 considère encore que les éléments d'une chaîne sont des octets, et non des caractères multi-octets.
Vu sous un autre angle, on dira que PHP utilise le codage ISO-8859-1 (Latin-1) pour ses chaînes de caractères.
(La mention de la version 5 est importante, ce point de vue archaïque doit changer avec PHP-6).
Tous les traitements de chaînes reposent donc sur l'équivalence 1 octet = 1 caractère.
Notamment, la fonction
ord renvoie la valeur
entière de l'octet, celle que nous avons manipulée en C, entre 0 et 255.Dans notre programme, nos subtiles questions sur la sortie du BMP sont donc restées lettre morte :
bon exemple de programme parfaitement correct du point de vue syntaxique, mais complètement idiot quant à la sémantique...
Si on ne souhaite que de transmettre la chaîne, cette manière de faire est sans importance :
une chaîne en UTF-8, par exemple, sera transmise octet par octet sans inconvénient.
Le texte codé en ASCII ci-dessus illustre parfaitement ce phénomène.
Si au contraire on demande à PHP de calculer sur la chaîne (par exemple, la renverser par la fonction
strrev())il faut absolument se ramener à l'équivalence octets-caractères.
Pour ce faire PHP propose le couple de fonctions
utf8_decode
/ utf8_encode.utf8_decode(une chaîne en UTF-8) renvoie la chaîne traduite en Latin-1utf8_encode(une chaîne en Latin-1) renvoie la chaîne traduite en UTF-8.
Que faire ? Adapter à PHP la technique de décodage des octets que nous avons mise au point en C.
Les mêmes causes engendrant les mêmes effets, nous sommes sûrs d'obtenir le résultat désiré !
(nouveau fichier
utf8ToHTML.php)
<?php
function entites( $chn ) {
// traduction en PHP du programme C du Cours6 , cf Plurital/Cours6/TransC/LirUTF8.html
$res = "";
$k = strlen($chn); // nombre d'octets
for( $i = 0; $i < $k; $i++ ){
$val = ord($chn{$i});
if( $val<128 ){ //ASCII
$res .= $chn{$i};
}else{
if( $val >= 240 ){ // 4 octets
$contr1 = ($val-240) * 262144;
$contr2 = (ord($chn{++$i})-128) * 4096;
$contr3 = (ord($chn{++$i})-128) * 64;
$contr4 = ord($chn{++$i})-128;
$res .= "<b>&#".($contr1+$contr2+$contr3+$contr4).";</b>"; // en gras
}else{
if( $val >= 224 ){ // 3 octets
$contr1 = ($val-224) * 4096;
$contr2 = (ord($chn{++$i})-128) * 64;
$contr3 = ord($chn{++$i})-128;
$res .= "&#".($contr1+$contr2+$contr3).";"; // en maigre
}else{ // 2 octets
$contr1 = ($val-192) * 64;
$contr2 = ord($chn{++$i})-128;
$res .= "&#".($contr1+$contr2).";"; // en maigre
}
}
}
}
return $res;
}// function entites
function trans ($tablignes){ // arg. tableau de lignes , renvoie un tableau de lignes
$k = 0;
$rtab = array();
foreach ( $tablignes as $ligne ){
$rligne = entites($ligne);
$rtab[$k] = $rligne."<br />\n";
$k++;
}
return $rtab;
} // trans
........ extrans et ligne de commande comme ci-dessus ..............
?>
Réalisation en JavaScript
En JavaScript il n'y a plus de fonction
ord,
mais un couple de méthodes de l'objet String
permettant d'obtenir - le caractère de rang i :
maChaine.charAt(i) - le numéro Unicode du caractère de rang i :
maChaine.charCodeAt(i)
textarea,et non pas en ligne de commande avec deux fichiers.
La fonction de lancement
extrans va donc être
assez différente de celle que nous avons vue en Perl et en PHP : - le texte d'entrée sera déposé (par copier-coller) dans
une
textarea, assortie d'uninput buttonpour lancer le JavaScript.
Ce texte sera converti en un tableau de lignes parsplit("\n").
- pour examiner le texte transformé, codé en ASCII, on
créera
une nouvelle fenêtre HTML par
window.open(),
dans laquelle on enverra les lignes pardocument.write().
On pourra ainsi à la fois observer l'affichage par le navigateur et examiner le texte-résultat en demandant le texte-source de cette fenêtre à Firefox (Safari refuse de le dévoiler).
(fichier
utf8ToHTML.js)function trans(tablignes){ // renvoie le tableau des lignes recodées
var nblignes = tablignes.length;
var rtab = new Array(nblignes);
for( var j = 0; j<nblignes; j++ ){ //boucle sur le tableau des lignes
var ligne = tablignes[j];
var rligne = "";
for ( var i = 0; i<ligne.length; i++ ) {
var nb = ligne.charCodeAt(i);
if( nb < 128 ){ // ASCII
rligne += ligne.charAt(i);
}else if( nb < 65536 ){ //BMP
rligne += "&#"+nb+";";
}else{ // Plan supplémentaire
rligne += "<b>&#"+nb+";</b>";
}
}
rtab[j] = rligne+"<br />\n";
}//for
return rtab;
}//trans
function extrans (txt) { // adaptée à un élément de formulaire "textarea"
var lignes = txt.split("\n"); //le tableau des lignes
var rlignes = trans(lignes);
var fenRes = window.open("");
for( var j = 0; j<rlignes.length; j++ ){
fenRes.document.write(rlignes[j]);
}
fenRes.document.close();
}//extrans
La page Web assurant la mise en scène peut se réduire à (fichier
utf8ToHTML.html):[notez, dans le formulaire, l'attribut
accept-charset="utf-8",
qui garantit que le texte est bien transmis en UTF-8 ;en revanche, inutile de prendre des précautions dans la fenêtre-résultat, puisqu'on lui envoie de l'ASCII !]
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Distinguer les plans supplémentaires</title>
<script type="text/javascript" src="utf8ToHTML.js"></script>
</head>
<body>
<p> Donnez votre texte en UTF-8,<br /> puis cliquez sur "go"</p>
<form action="" accept-charset="utf-8">
<p> <textarea name="donn" rows="10" cols="20"></textarea> </p>
<p> <input type="button" value="go" onclick="extrans(donn.value);"> </p>
</form>
</body>
</html>
Voyez :
 --------->
--------->
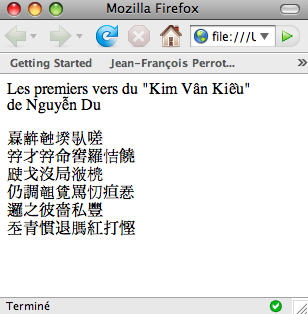
Voila qui est superbe.... mais les caractères gras ne ressortent pas très nettement.
Voyons le code-source produit :
Les premiers vers du "Kim Vân Kiều"<br />
de Nguyễn Du<br />
<br />
����������嗟<br />
��才��命窖羅恄饒<br />
��戈沒局��橷<br />
仍調����罵忉疸��<br />
邏之彼嗇私豐<br />
��青慣退��紅打慳<br />
<br />
Mais c'est pas du tout ça !
Que s'est-il passé ?
Eh bien, si on lit attentivement la documentation sur JavaScript, on voit (parfois) mentionné que
maChaine.charCodeAt(i) renvoie un
entier sur 16 bits ! Nous en éprouvons ici les
conséquences ...En effet, quand on sort du BMP, le numéro Unicode vu comme un entier ne peut plus se loger dans 16 bits.
Un conflit se produit alors entre
- la position de principe, pour qui la taille de l'entier
est
sans importance,
par exemple, les entités HTML restent valables :
- Le caractère gotique 𐌰, U+10330, est fidèlement désigné par l'entité 𐌰 : 𐌰
- Le caractère nôm 𤾓, U+024F93, est fidèlement
désigné
par l'entité 𤾓
: 𤾓
- la réalité de nombreuses implémentations pour
lesquelles
l'unité de compte est de 16 bits.
ainsi, en JavaScript, sans que ce soit documenté, les méthodes de l'"objet" String- la fonction charCodeAt(i)
renvoie
un entier sur 16 bits
- la fonction length() renvoie
le
nombre de blocs de 16
bits et non pas le nombre de caractères
- la fonction charCodeAt(i)
renvoie
un entier sur 16 bits
chaque numéro Unicode qui dépasse FFFF est assorti de sa représentation comme un couple de nombres sur 16 bits
- le premier appartenant à la plage U+D800 à U+DBFF (demi-zone haute d’indirection)
- le second appartenant à la plage U+DC00 à U+DFFF (demi-zone basse d’indirection)
- Le caractère gotique 𐌰, U+10330 = (D800+DF30)
est aussi fidèlement désigné par la séquence de deux entités �� : 𐌰 - Le caractère nôm 𤾓, U+024F93 = (D853+DF93),
est aussi fidèlement désigné par la séquence de deux entités �� : 𤾓
Cette remarque permet d'interpréter complètement le résultat précédent, et de rectifier notre programme.
Nous voyons en effet que le test "
if( nb < 65536 )"
est rendu inopérant par la restriction à 16 bits, et qu'il faut donc le remplacer par :
if( nb>=0xD800
&& nb<=0xDBFF ){ //DHI, 1er composant plan
supplémentaire
rligne +=
"<b>&#"+nb+";&#"+ligne.charCodeAt(++i)+";</b>";
//
en gras
}else{ // BMP
rligne += "&#"+nb+";"; // en maigre
}Moyennant quoi tout rentre dans l'ordre.
Réalisation en Java
Pour rester le plus près possible du cadre adopté pour les trois précédents langages, notre conception en Java restera fort peu "objet".Nous écrirons une classe
Utf8ToHTML qui
n'aura point d'instance. La fonction
trans aura le statut de
méthode de classe (static), et la
fonction de lancement extrans sera remplacée
par la méthode exécutable main. Les tableaux
non typés des autres langages seront ici des instances de java.util.Vector<String>.Java insiste beaucoup sur le fait que les éléments des chaînes sont des caractères, accessibles par
maChaine.charAt(i)comme en JavaScript, qui renvoie une valeur de typechar(voir ci-après)maChaine.codePointAt(i)[au lieu demaChaine.charCodeAt(i)en JavaScript], qui renvoie le numéro Unicode comme un entier.
BufferedReader entree =
new BufferedReader (
new
InputStreamReader(new FileInputStream (args[0]), "UTF-8") );du
BufferedReader qui, par lecture ligne à
ligne via entree.readLine() va servir de base
à la confection du tableau des lignes du texte initial.(fichier
Utf8ToHTML.java)import java.io.BufferedReader;
import java.io.PrintWriter;
import java.io.InputStreamReader;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.Vector;
class Utf8ToHTML {
public static Vector<String> trans (Vector<String> tablignes) throws Exception{
int nblignes = tablignes.size();
Vector<String> rtab = new Vector<String>(nblignes);
for( String ligne : tablignes ){
String rligne = "";
for( int i = 0; i< ligne.length(); i++ ){
int nb = ligne.codePointAt(i);
if( nb < 128 ){ // ASCII
rligne += ligne.charAt(i);
}else{
if( nb < 65536 ){ // BMP
rligne += "&#"+nb+";";
}else{ // Plan supplémentaire
rligne += "<b>&#"+nb+";</b>";
}
}
}
rtab.addElement(rligne+"<br />\n");
}
return rtab;
} // trans
public static void main(String[]args) throws Exception{
BufferedReader entree =
new BufferedReader (
new InputStreamReader(new FileInputStream (args[0]), "UTF-8") );
PrintWriter sortie =
new PrintWriter(new FileOutputStream (args[1])); // ASCII
Vector<String> lignes = new Vector<String>();
String ligne = entree.readLine();
do {
lignes.addElement(ligne);
ligne = entree.readLine();
}while ( ligne != null );
Vector<String> rlignes = trans(lignes);
for( String rligne : rlignes ){
sortie.print(rligne);
}
sortie.close();
}// main
}// Utf8ToHTML
Essayons :
jfp% java Utf8ToHTML Kieu.txt KieuJ.html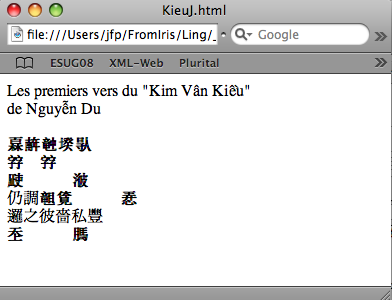 Vous avez dit bizarre
?
Vous avez dit bizarre
?Voyons le code engendré :
Les premiers vers du "Kim Vân
Kiều"<br />
de Nguyễn Du<br />
<br />
<b>𤾓</b>�<b>𢆥</b>�<b>𥪝</b>�<b>𡎝</b>�<b>𠊛</b>�嗟<br
/>
<b>𡦂</b>�才<b>𡦂</b>�命窖羅恄饒<br
/>
<b>𣦆</b>�戈沒局<b>𣷭</b>�橷<br
/>
仍調<b>𥉩</b>�<b>𧡊</b>�罵忉疸<b>𢚸</b>�<br
/>
邏之彼嗇私豐<br
/>
<b>𡗶</b>�青慣退<b>𦟐</b>�紅打慳<br
/>
<br />Curiouser and curiouser, comme aurait dit Alice !
Le fond du problème est évidemment que Java, comme JavaScript, considère que ses caractères ne doivent pas dépasser 16 bits.
C'est dit explicitement dans la JavaDoc de la classe
java.lang.String
:A
String represents a string in
the
UTF-16 format in which supplementary characters [scil.
ceux des plans supplémentarires] are represented by surrogate
pairs [...]. Index values refer to char code units, so a supplementary character uses two positions in a String.
On voit ici apparaître une distinction subtile entre character et char code unit, qui est détaillée dans la JavaDoc de la classe
java.lang.Character.
Il en ressort que le type de base
char est
limité 16 bits, et que les caractères des plans
supplémentaires sont représentés par des couples de charsuivant le format UTF-16 (d'où l'appellation char code unit qui se réfère au codage UTF-16).
Comme les constantes de la forme
'\ulenumérohex'
sont des constantes de type char, il s'ensuit
qu'une écriture comme '\u024F93' est
incorrecte.Mais cette limitation n'affecte que la collection des valeurs du type
char
(et par conséquent la collection des instances de la classe Character),
elle n'empêche pas de manipuler tous les caractères Unicode à partir de leur numéro donné comme un entier.
Par exemple, la classe
Character
définit une méthode statique charCount
permettant de savoir si un caractère donné par son numéro (int
codePoint) est représenté par un ou deux
char en UTF-16,
ainsi qu'une méthode statique toCodePoint
donnant le n° du caractère représenté par deux surrogates...Notamment, comme le résultat de
maChaine.codePointAt(i)
est un entier et non un char, il ne faut pas
être surpris qu'elle renvoie le numéro Unicode correct même s'il dépasse 16 bits, comme l'expérience le montre. Mais il ne faut pas non plus s'étonner qu'en pareil cas la demande
maChaine.codePointAt(i+1) renvoie non pas le n° Unicode du caractère suivant, mais bel et bien l'entier correspondant aux 16 bits du second surrogate (de la demi-zone basse d'indirection),
comme on le vérifie en confrontant le résultat ci-dessus avec ce que JavaScript nous a produit précédemment.
Quant à l'affichage observé, l'entité HTML correspondant à un surrogate (p. ex.
�) n'est pas
interprétée par le navigateur, et de plus, lorsqu'elle précède une entité valable, comme à la fin de la première ligne :
�嗟,l'interprétation de cette dernière est inhibée - d'où les lacunes observées dans l'image.
Mais que faire pour résoudre notre petit problème ?
Il suffit d'éliminer les entités parasites en incrémentant le compteur lorsqu'on constate que l'on sort du BMP :
if( nb
< 65536 ){ //
BMP
rligne += "&#"+nb+";";
}else{ // Plan supplémentaire
rligne
+= "<b>&#"+nb+";</b>";
i++;
// sauter le DBI
}Et tout rentre dans l'ordre !
On peut faire plus chic, en remplaçant le test "
nb <
65536" qui demande explication par "Character.isSupplementaryCodePoint(nb)"
if( Character.isSupplementaryCodePoint(nb)
){ // Plan supplémentaire
rligne += "<b>&#"+nb+";</b>";
i++;
// sauter le DBI
}else{ // BMP
rligne += "&#"+nb+";";
}Si vous trouvez que cette solution simple ressemble plus à un patch qu'à une construction rationnelle, je vous propose de demander systématiquement le
charAt(i),et de lui lui poser la question
isHighSurrogate
(nouveau fichier Utf8ToHTML.java): for( int i = 0; i< ligne.length(); i++ ){
char carlu = ligne.charAt(i);
if( (int) carlu < 128 ){ // ASCII
rligne += ligne.carlu;
}else{
if( Character.isHighSurrogate(carlu)
char carsuiv = ligne.charAt(++i);
int nb = Character.toCodePoint(carlu, carsuiv);
rligne += "<b>&#"+nb+";</b>";
}else{ // BMP
rligne += "&#"+(int) carlu+";";
}
}
}
Conclusion
Les langages de programmation ont suivi le mouvement !L'attachement à l'équation caractère = octet reste bien présent chez PHP (en attendant la version 6),
et JavaScript ne l'a abandonnée que pour en adopter une autre : caractère = 2 octets,
qui, si elle est moins mutilante, pose des problèmes encore en discussion autour du standard ECMAScript.
Perl et Java en revanche traitent la question à fond, chacun à sa manière.
Encore ne nous sommes-nous préoccupés ici que des seuls numéros Unicode !
Pour que la comparaison soit complète, il faut aussi examiner comment les langages de progammation permettent de parler des caractères,
quels sont les prédicats disponibles pour ce faire, quelles fonctions leurs sont applicables, etc.
Comme on l'a vu au cours 5, la voie d'accès principale est celle des classes de caractères utilisables dans les expressions régulières,
pour Perl comme pour Java.
Java, armé du concept de classe, y ajoute une nomenclature attachée aux classes
java.lang.Character
et java.lang.Character.UnicodeBlock.Il y a de quoi faire !