Les deux niveaux lexique / syntaxe
Les grammaires, comme les expressions régulières, décrivent l'organisation de chaînes de caractères.Mais dans la pratique des grammaires, aussi bien en linguistique d'en informatique, ces caractères représentent en fait des classes de mots :
- en linguistique : article, préposition, adverbe et autres ;
- en informatique : nombre, identificateur, opérateur, etc.
-
De quoi parlent les grammaires
Par exemple, dans la grammaire context-free d'une classe d'expressions arithmétiques,
- tous les nombres jouent le même rôle (ils désignent
des
constantes) ;
- tous les identificateurs aussi (ils désignent des
variables) ;
- les différents opérateurs ne se distinguent que par
leur
arité (opérateurs binaires ou unaires),
et (le cas échéant) par leur priorité.
Du point de vue grammatical, les deux expressions
+ * 89 xy3 - / vvb 2 33
/ -123ubc3 * +xx789 77
L'écriture que nous avons adoptée précédemment est donc incohérente, à savoir
S -> +SSS -> *SSS -> vS -> i
Ce désordre ne fait que traduire un certain malaise...
Le présent exposé a pour but d'y mettre fin.
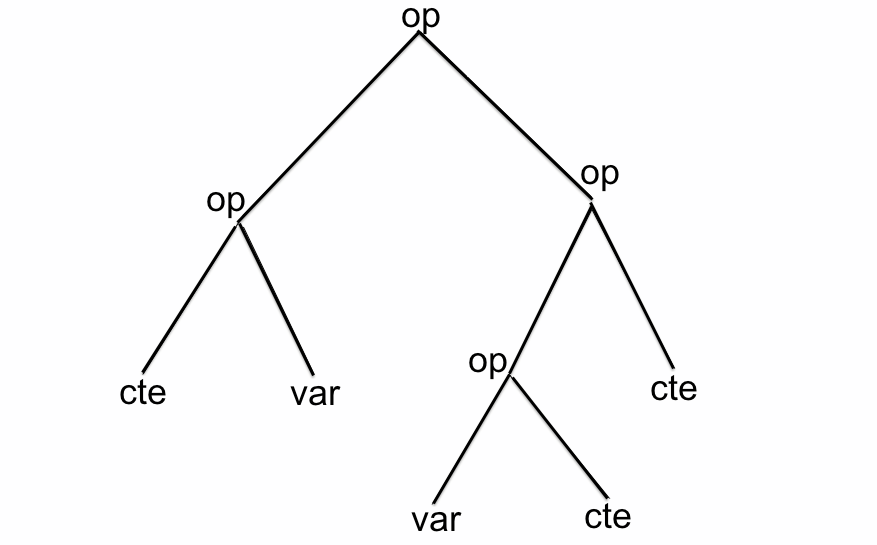
En vérité la grammaire en question doit s'écrire
S -> op S SS -> cteS -> var
La description exacte de ces trois classes est une autre affaire : c'est le travail de l'analyseur lexical, alias le lexeur.
Dans notre exemple, en appelantctela classe des nombres,varcelle des noms de variables, etopcelle des opérateurs (binaires),
le lexeur produira dans les deux cas la même séquence
op op cte var op op var cte cte
qui par rapport à la grammaire ci-dessus admet la dérivation gauche112311322.
D'une manière générale, pour effectuer une tâche de quelque intérêt, il faut placer avant le parseur une phase préliminaire d'analye lexicale,
qui va extraire de la chaîne de caractères donnée la séquence des classes lexicales sur laquelle travaille le parseur.
- tous les nombres jouent le même rôle (ils désignent
des
constantes) ;
-
La notion de lexème
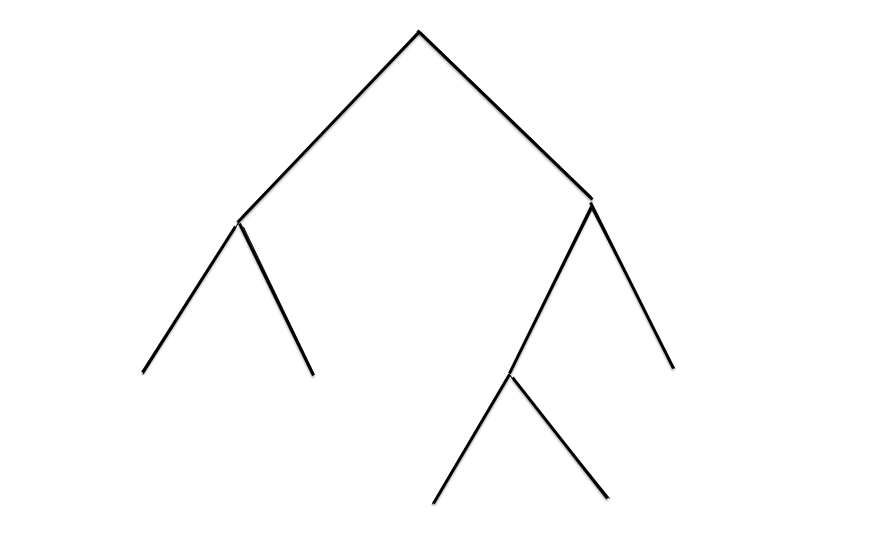
Suite de ntotre exemple : Si l'analyse syntaxique se contente de produire la dérivation gauche, ou même l'arbre qui lui est associé :
elle sera bien peu utile !
Ce dont nous avons besoin, c'est de l'arbre de l'expression avec les "vrais" opérateurs, les "vrais" nombres et les "vrais" noms de variables !
respectivement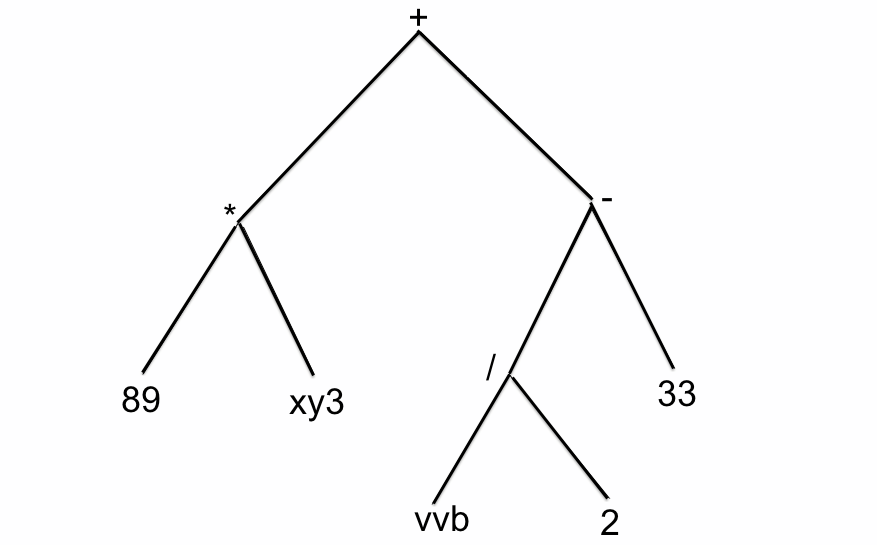 et
et 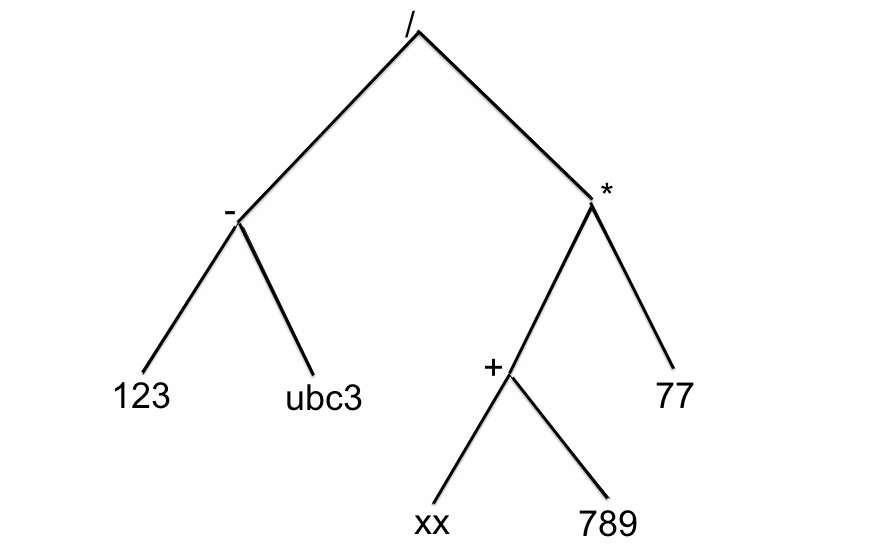
Pour les construire, il faudra bien que le parseur ait connaissance, en plus des classes lexicales, des chaînes de caractères elles-mêmes !
Nous appellerons lexème un objet en deux parties, une chaîne de caractères d'une part, et d'autre part la classe lexicale qui lui est associée.
La réalisation effective de cet objet dépend fortement du langage de programmation utilisé.
Le terme anglais correspondant est (lexical) token, qui a le sens très général de symbole.
La tâche du lexeur est de fournir au parseur la séquence des lexèmes déduite de la chaîne de caractères donnée.
-
Le paradigme et le syntagme
Notons la parenté du travail du lexeur avec ce que les linguistes appellent l'axe paradigmatique, tandis que celui du parseur rejoint l'axe syntagmatique.
À ce sujet, outre l'article paradigme de Wikipédia et diverses pages que vous proposera Google, voyez un passionnant article de Christian Vandendorpe sur l'évolution des concepts.
Le vocabulaire des informaticiens est moins sonore...
-
Distinction algorithmique
À la distinction fondamentale entre niveau lexical et niveau syntaxique vient s'ajouter une différence de nature algorithmique.
- Le niveau syntaxique est régi par une grammaire
context-free (faute de
mieux...),
- mais la plupart du temps, la mécanique du lexeur est
à
base
d'expressions régulières et d'automates finis.
Plus précisément,
- les différentes classes lexicales sont décrites par
des expressions régulières ;
- à chacune de ces expressions est associé un automate
fini ;
- lorsqu'un mot est accepté par un des automates, le lexeur lui associe la catégorie lexicale correspondante et construit un lexème.
- les différentes classes lexicales sont décrites par
des expressions régulières ;
En d'autres termes, la description des différentes catégories lexicales se fait au moyen d'expressions régulières, non à travers d'autres grammaires.
Ce choix a une conséquence gênante dans la pratique de la programmation : les commentaires ne peuvent pas être imbriqués.
En effet, le lexeur doit savoir séparer les chaînes correspondant aux différents lexèmes.
Cette stratégie (lexeur à exp. régulières / parseur associé à une grammaire context-free) a connu dès 1975 une réalisation historique avec le couple Lex / Yacc. Parmi d'innombables références, voici une page du cours Automates de 2010.
Dans ce cadre il va traiter le blanc, la tabulation et le saut de ligne comme des caractères séparateurs, et il va aussi considérer qu'un commentaire est un séparateur. Il devra donc disposer d'une expression régulière pour décrire les commentaires, ce qui impose une marque de début et une marque de fin et exclut la présence d'un commentaire à l'intérieur d'un commentaire.
Un programmeur ne pourra donc pas "mettre en commentaire"(en anglais comment out), pour la désactiver provisoirement, une portion de code qui contient déjà des commentaires... Dommage !
- Le niveau syntaxique est régi par une grammaire
context-free (faute de
mieux...),
Réalisation avec FOMA
L'emploi de transducteurs finis pour effectuer diverses opérations linguistiques a fait l'objet d'un grand nombe de réalisations logicielles, notamment de la part de Xerox (voyez la page Finite State Morphology). Le système FOMA s'inscrit dans cette lignée.Il est écrit en C, et on peut le mettre en œuvre depuis des programmes C++. Voyez le cours de M.-A. Moreaux pour les détails.
Nous n'en ferons ici qu'un usage extrêmement restreint !
-
Écriture d'un lexeur en FOMA : fichier
Ce fichier est un fichier-source qui sera compilé par les soins de FOMA en un fichiertoken.fomatoken.fstconsommable par C++.
Nous commentons l'exemple du lexeur des expressions polonaises :
comme en Shell et en Perl, les commentaires commencent par '#'
# token.fomadétail technique
#####################
clear stack #
#
#### espaces ####
echo >>> définition des espaces #
define SP "\u0020";
define TAB "\u0009";
#define NL "\u000a";
define ESPACE [ SP | TAB ]; #
#### chiffres
echo >>> définition des chiffres
define CHIFFRE ["0"|1|2|3|4|5|6|7|8|9]; #
#
#### caractères alphabétiques
echo >>> définition des caractères alphabétiques
define MIN [a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z] ;
define MAJ [A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z] ;
define LETTRE [ MIN | MAJ ];
#
####"regex"
# Chaque règle est placée entre crochets, reliée à la suivante par la conjonction '.o.' ;
# dans chaque règle, le symbole '@->' sépare l'exp. reg. définissant une classe lexicale du nom de cette classe, écrit entre les délimiteurs '%#'.
# Notez que tout caractère ASCII autre qu'une lettre ou un chiffre trouve un emploi dans la syntaxe de FOMA,
# et que c'est '%' qui joue ici le rôle du '\' que nous utilisons en Perl.
regex [ ESPACE @-> %#blanc%#... ]
.o. [ CHIFFRE+ @-> %#cte%#...]
.o. [ LETTRE+ @-> %#var%#...]
.o. [ [%- | %+ | %* | %/ ] @-> %#op%#...]
.o. [ %$ @-> %#eof%#...];
#
save stack token.fst
Autre exemple, le lexeur pour la grammaire de Louis Lecailliez : exemple illustratif
( ~ ( || xxx ( && ( ~ vvv ) yyy ) ) )
po op1 po op2 chn po op2 po op1 chn pf chn pf pf pf
-
Compilation de
token.fomaentoken.fst- lancer
foma
jfp$ foma
Foma, version 0.9.17alpha
Copyright © 2008-2012 Mans Hulden
This is free software; see the source code for copying conditions.
There is ABSOLUTELY NO WARRANTY; for details, type "help license"
Type "help" to list all commands available.
Type "help <topic>" or help "<operator>" for further help.
foma[0]:
- charger le fichier
token.fomapar la commandesource
foma[0]: source token.foma
Opening file 'token.foma'.
>>> définition des espaces
defined SP: 202 bytes. 2 states, 1 arc, 1 path.
defined TAB: 202 bytes. 2 states, 1 arc, 1 path.
defined ESPACE: 287 bytes. 2 states, 2 arcs, 2 paths.
>>> définition des chiffres
defined CHIFFRE: 623 bytes. 2 states, 10 arcs, 10 paths.
>>> définition des caractères alphabétiques
defined MIN: 1.3 kB. 2 states, 26 arcs, 26 paths.
defined MAJ: 1.3 kB. 2 states, 26 arcs, 26 paths.
defined LETTRE: 2.3 kB. 2 states, 52 arcs, 52 paths.
4.7 kB. 8 states, 162 arcs, Cyclic.
Writing to file token.fst.
foma[1]:
- et le tour est joué !
foma[1]: exit
jfp$
- lancer
-
Mise en œuvre en C++ (par M.-A. Moreaux)
- Une classe
lexemeet une classetexte.
- chaque instance de
lexemerépond à deux méthodes
string chLex()renvoie la sous-chaîne découpée dans la chaîne d'entrée ;
string classeLex()renvoie le nom de la classe lexicale.
- chaque instance de
texte
- est construite à partir d'une chaîne de
caractères
(la chaîne d'entrée du parseur)
- répond à une méthode
lexeme nextToken()qui renvoie le lexème suivant dans la chaîne de base,
sans possibilité de retour en arrière...
- est construite à partir d'une chaîne de
caractères
(la chaîne d'entrée du parseur)
- chaque instance de
- L'opération essentielle est la création d'un objet
texteà partir de la chaîne d'entrée.
C'est là que FOMA entre en jeu, au moyen du fichiertoken.fstqui est chargé et utilisé par le constructeur de la classetexte.
- Voyez la suite dans les pages consacrées aux parseurs
descendants
et ascendants.
- Une classe