Cours n° 22, 12 avril 2012
Analyse ascendante
- Algorithme à
pile shift-reduce
- L'algorithme
d'analyse procède par une suite d'actions de
deux sortes
- Idée de
réduction / action
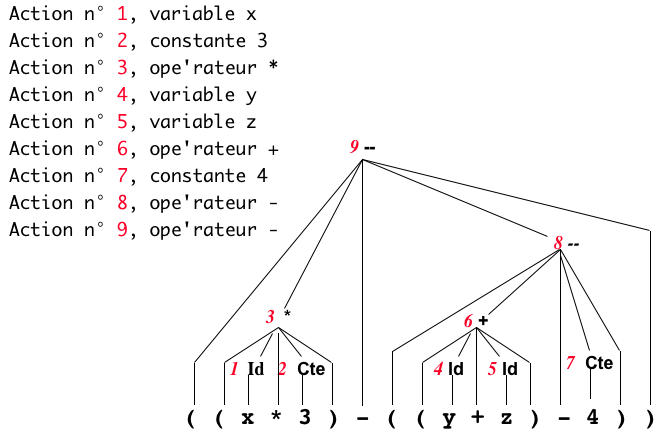
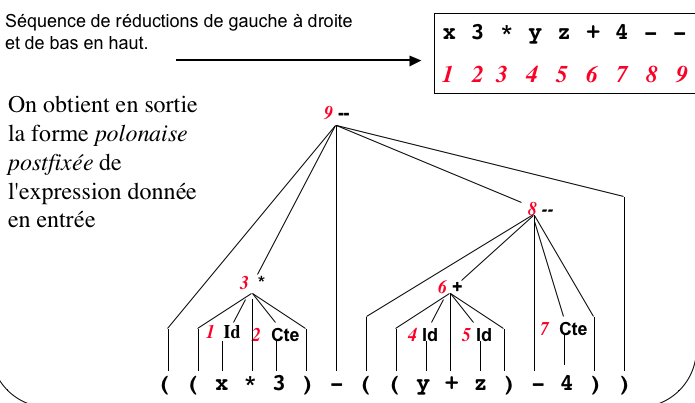
- Application
n°1 : traduction en postfixée
- Application
n° 2 : calcul de la profondeur de l'arbre
- Application
n° 3 : évaluation d'une exp. compl.
parenthésée
- Application
n° 4 : Construction d'un arbre syntaxique
- La
construction d'un arbre syntaxique est une forme
d'évaluation "symbolique".
- Actions
en vue de la construction de l'arbre syntaxique
- Réalisation
élémentaire de l'analyse ascendante en C++
- Le cadre
général
- Analyse
conforme à la théorie
- Génération
de l'arbre d'expression
- Notation
complètement parenthésée
- Analyse
conforme à la théorie
- Génération
de l'arbre d'expression
- Notation
polonaise préfixée
- Notation
à précédences (2
niveaux)
- Principe
- Construction de l'arbre
-
"
shift" (empiler
un lexème)
"reduce"
(trouver une partie droite de règle en sommet de pile et la
réduire = la remplacer par le non-terminal correspondant)
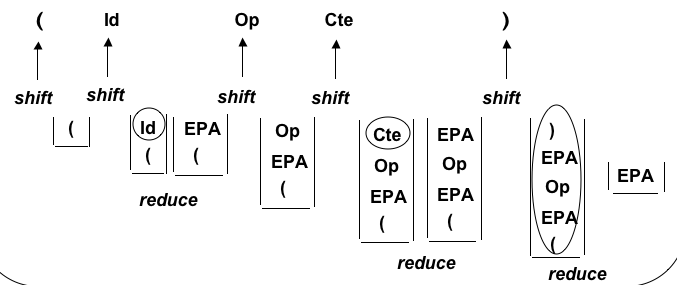
Mouvements de la pile
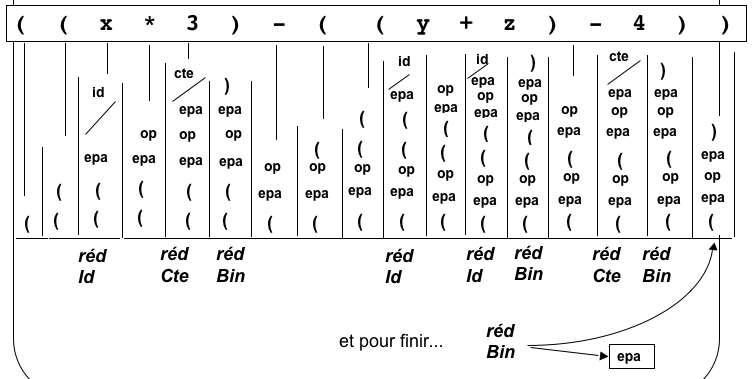
-
On considère la séquence des réductions au cours du déroulement de
l'algorithme shift-reduce.
À chaque réduction on associe une action
(dans le contexte où la
réduction a lieu),
et on s'intéresse au résultat produit par la
séquence d'actions
parallèle à la séquence des réductions.
-
Que
faut-il faire pour que la séquence d'actions pilotée par le processus
shift/reduce effectue la traduction en notation polonaise postfixée ?
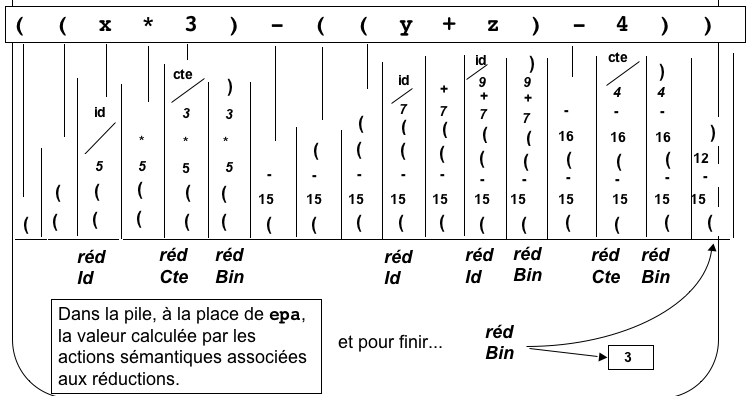
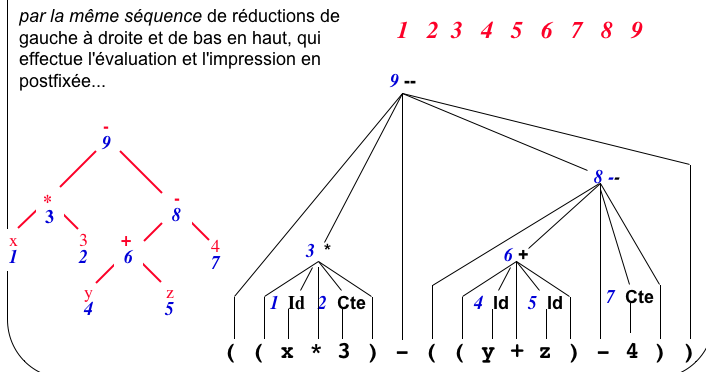
- lorsqu'on réduit Id, on écrit l'identificateur en
question
- lorsqu'on réduit Cte, on écrit la constante en question
- lorsqu'on réduit Bin, on écrit l'opérateur trouvé dans
la
pile.
et ça marche !
Question : peut-on traduire de la même manière en préfixée
? NON !!!
-
Réductions / actions utilisant la pile
- lorsqu'on réduit Id, on empile la profondeur 0
- lorsqu'on réduit Cte, on empile la profondeur
0
- lorsqu'on réduit Bin,
- on trouve dans la pile les profondeurs des deux
sous-arbres droit
(en-dessus),
soit pd et gauche (en-dessous), soit pg,
- et on empile la profondeur totale qui vaut 1+
max(pg,
pd)
À la fin du calcul, la profondeur de l'arbre tout entier est seule dans
la pile.
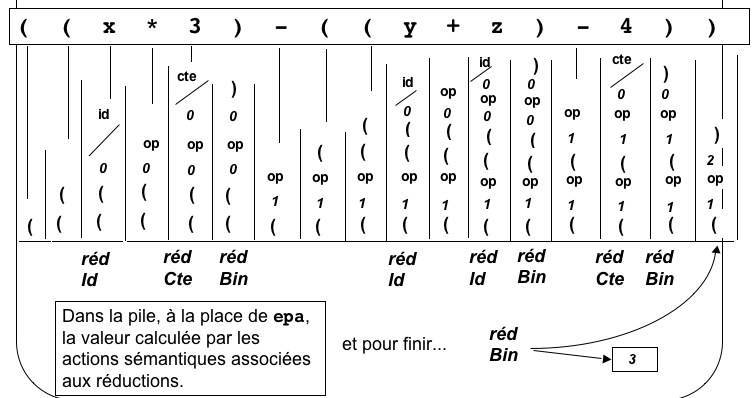
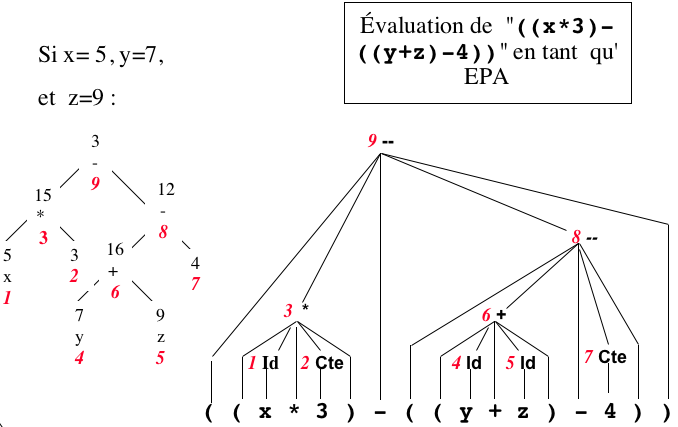
-
Processus d'évaluation par réductions / actions
- lorsqu'on réduit Id, on empile la valeur de la
variable
- lorsqu'on réduit Cte, on empile la valeur de la
constante
- lorsqu'on réduit Bin,
- on trouve dans la pile les valeurs des deux
sous-arbres
- droit (en-dessus), soit vd
- et gauche (en-dessous), soit vg,
- on trouve dans la pile entre les deux
valeurs l'opérateur op
- et on empile la valeur totale qui est op(vg,
vd)
À la fin du calcul, la valeur de l'arbre tout entier est seule dans la
pile.
-
-
Au lieu d'opérer dans le domaine des entiers, on calcule dans un
domaine d'arbres
(pour nos expériences en C++, ces arbres seront des instances de la
classe ArbExp : fichiers ArbExp.h
et ArbExp.cpp).
- pour une constante ou une variable, on
crée une feuille, par le constructeur unaire
ArbExp(char).
[On fait l'hypothèse simplificatrice que le nom de la variable et la
valeur de la constante sont adéquatement
représentées par un seul caractère, lettre ou chiffre.
Cette restriction sera levée plus tard par le recours à l'analyse
lexicale.]
- pour une opération binaire, on dispose de
l'opérateur op (caractère) et des deux
sous-arbres ag (à gauche) et ad
(à droite)
(dans notre algorithme, ils sont logés dans la pile),
on crée le sous-arbre correspondant par le constructeur ternaire ArbExp(op,
ag, ad).
-
d'une exp. compl. parenthésée : tout - à-fait analogues à celles de
l'évalution
- lorsqu'on réduit Id, on empile
ArbExp(nom)
- lorsqu'on réduit Cte, on empile
ArbExp(val)
- lorsqu'on réduit Bin,
- on trouve dans la pile les deux sous-arbres
droit
(en-dessus), soit
ad et
gauche (en-dessous), soit ag,
- on trouve dans la pile entre les deux
sous-arbres l'opérateur
op
- et on empile l'arbre construit
ArbExp(op,
ag, ad)
À la fin du calcul, l'arbre tout entier est seul dans
la pile.
-
Tous les analyseurs que nous allons voir ont exactement la même
structure.
Nous nous tenons à une programmation qui reflète fidèlement le discours
théorique.
La classe pile que nous employons est la même
que celle
que nous avons mise en œuvre dans l'analyse descendante.
-
Le processus est piloté par la pile (en C++, c'est une pile de caractères,
de type
char,
ce qui nous oblige à choisir des symboles non-terminaux
monogrammes).
Il prend la forme d'une boucle while qui
- à chaque itération effectue une des deux opérations shift
ou reduce
en fonction du symbole qui se trouve au sommet de la pile.
Le choix de l'action est réalisé par un switch
opérant sur le symbole en sommet de pile
char sp = p->top();
switch( sp ){....}
- prend fin lorsque le mot d'entrée a été entièrement
lu.
Pour permettre les dernière réductions qui ont lieu après avoir lu le
dernier caractère
on ajoute au mot à analyser un marqueur final en présence
duquel se feront les dernières réductions.
C'est lorsqu'un ultime shift se produira que le
test de fin de boucle
sera déclenché.
Bien évidemment, cette réalisation court le risque
de boucler indéfiniment,
il faudra être vigilant !
La structure du programme est donc :
- Initialisations
string lu; // le
mot à analyser
getline(cin, lu); // lecture du mot à
analyser
pile* p = new pile(); // vide
lu = lu+'$'; // marqueur final
int k = lu.length();
int i = 1; // indice de lecture du mot
d'entrée
p->push(lu[0]); // le premier
caractère dans la pile
- Boucle
while(
i < k ){
char
carlu = lu[i];
//
Visualiser le processus
cout
<< carlu << " -- ";
p->show();
char
sp = p->top();
switch(
sp ){
case '(' :......
...............
................
} //
switch( p->top() )
}// while
- Vérifications finales
À
la fin de
la lecture la pile doit contenir l'axiome seulement, mais comme
on a empilé en plus le marqueur '$'
il faut en tenir compte dans la vérification
p->pop();
// du marqueur final
if( p->top() != 'S' ){ // en supposant que l'axiome
est 'S', à modifier le cas échéant !
cout
<< "Erreur dans la pile finale : " << endl;
p->show();
cout
<< endl;
return 1;
}
p->pop(); // de l'axiome
if( !p->empty() ){
cout
<< "Erreur : pas fini"<< endl;
return 1;
}
// et si tout va bien...
cout << "OK"
<< endl;
return 0;
Ceci posé, il ne reste plus qu'à écrire le switch( sp )
traduisant les différentes gramamaires que nous avons vues.
C'est ce que nous allons faire ci-après.
-
Comme dans l'analyse descendante, pour construire l'arbre il nous faut
une classe
ArbExp (fichiers ArbExp.h
et ArbExp.cpp)
et une seconde pile propre à contenir des arbres (et non plus des
caractères),
qui nous est fournie par la classe pilArb
(fichiers pilArb.h
et pilArb.cpp).
Il serait possible de construire un type complexe accommodant les deux,
mais cette construction est ici sans intérêt
(elle intervient au contraire dans la génération automatique par le
logiciel Yacc, que nous verrons plus tard).
On notera ici que c'est la pile de caractères qui pilote le processus,
la
pile d'arbres lui étant strictement asservie.
Les phases d'initialisation et de vérification deviennent :
- Initialisation
string lu;
getline(cin, lu); // la chaîne à analyser
pile* p = new pile(); // vide
pilArb* pA = new pilArb();
// vide
// Auxiliaires pour construire l'arbre
ArbExp* arbg; // pour le sous-arbre
gauche
ArbExp* arbd; // id. droit
char oparb; // le symbole
opérateur
lu = lu+'$'; // marqueur final, commode
pour piloter la boucle
int k = lu.length();
int i = 1;
p->push(lu[0]);
- Vérification finale
// À la fin de
la
lecture la pile doit contenir l'axiome seulement
p->pop(); // du marqueur final
if(
p->top() != 'S' ){
cout
<< "Erreur dans la pile finale : " << endl;
p->show();
cout
<< endl;
return 1;
}
p->pop();
if( !p->empty() ){
cout
<< "Erreur : pas fini"<< endl;
return 1;
}
// et si tout va bien...
ArbExp* res =
pA->top();
res->printPref();
cout << endl;
res->printPost();
cout << endl
<< "OK" << endl;
return 0;
Ici aussi, il ne reste plus qu'à écrire le switch( sp )
...
-
À comparer avec l'analyseur descendant pour la
même grammaire
Grammaire : la même que pour l'analyse descendante.
S -> (S O S)S -> vS-> iO -> +O -> *
Les symboles dans la pile sont ceux de la grammaire.
La stratégie shift/reduce est
limpide : la donnée du symbole en sommet de pile suffit
- pour décider entre shift et reduce,
- et dans le second cas pour savoir quelle règle on doit
réduire.
Notez que shift comporte l'incrémentation de
l'indice i, essentielle pour assurer la
terminaison de la boucle while !
-
fichier
acp1.cpp
switch( sp ){
case '(' :
case 'S' :
case 'O' : { // shift
p->push(carlu);
i++;
// fondamental !!!
break;
} // case '(' 'S' 'O'
case '+' :
case '*' : { // reduce O -> op
p->pop();
p->push('O');
break;
}
case 'x' :
case 'y' :
case 'z' :
case '1' :
case '2' :
case '3' : { // reduce S -> term
p->pop();
p->push('S');
break;
}
case ')' : { // reduce S -> (SOS)
p->pop(); // de ')'
if(
p->top() != 'S' ){
cout << "Erreur dans la pile '(' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'S'
if( p->top() != 'O' ){
cout << "Erreur dans la pile 'S' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'O'
if( p->top() != 'S' ){
cout << "Erreur dans la pile 'O' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'S'
if( p->top() != '(' ){
cout << "Erreur dans la pile 'S' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de '('
p->push('S');
break;
} // case ')'
default : { cout << "Erreur symbole inconnu : "
<< sp << endl;
return 1;
}
} //
switch( p->top() )
Exécution :
jfp% ./a.out
((x+y)*((x+(y*(z+2)))*(y+3)))
( -- (
x -- ( (
+ -- x ( (
+ -- S ( (
y -- + S ( (
y -- O S ( (
) -- y O S ( (
) -- S O S ( (
* -- ) S O S ( (
* -- S (
( -- * S (
( -- O S (
( -- ( O S (
x -- ( ( O S (
+ -- x ( ( O S (
+ -- S ( ( O S (
( -- + S ( ( O S (
( -- O S ( ( O S (
y -- ( O S ( ( O S (
* -- y ( O S ( ( O S (
* -- S ( O S ( ( O S (
( -- * S ( O S ( ( O S (
( -- O S ( O S ( ( O S (
z -- ( O S ( O S ( ( O S (
+ -- z ( O S ( O S ( ( O S (
+ -- S ( O S ( O S ( ( O S (
2 -- + S ( O S ( O S ( ( O S (
2 -- O S ( O S ( O S ( ( O S (
) -- 2 O S ( O S ( O S ( ( O S (
) -- S O S ( O S ( O S ( ( O S (
) -- ) S O S ( O S ( O S ( ( O S (
) -- S O S ( O S ( ( O S (
) -- ) S O S ( O S ( ( O S (
) -- S O S ( ( O S (
* -- ) S O S ( ( O S (
* -- S ( O S (
( -- * S ( O S (
( -- O S ( O S (
y -- ( O S ( O S (
+ -- y ( O S ( O S (
+ -- S ( O S ( O S (
3 -- + S ( O S ( O S (
3 -- O S ( O S ( O S (
) -- 3 O S ( O S ( O S (
) -- S O S ( O S ( O S (
) -- ) S O S ( O S ( O S (
) -- S O S ( O S (
) -- ) S O S ( O S (
) -- S O S (
$ -- ) S O S (
$ -- S
OK
-
La gestion de la pile de caractères est presqu'identique à celle du
programme précédent.
Le seul changement vient de la nécessité de loger l'opérateur lors de
la construction de l'arbre.
Cet opérateur étant un caractère il ne peut pas habiter dans la pile
des arbres (ce qui serait sa place "logique").
On va donc l'héberger dans la pile de contrôle, à la place du
non-terminal 'O'.
Ce qui revient à dire que nous reprenons la grammaire
du cours 19...
fichier acp1Arb.cpp
switch( sp ){
case '(' :
case '+' :
case '*' :
case 'S' : { // shift
p->push(carlu);
i++;
break;
} // case '(' 'S' [ 'O' ne figure plus
dans la pile ]
case 'x' :
case 'y' :
case 'z' :
case '1' :
case '2' :
case '3' : { // reduce S -> term
p->pop();
p->push('S');
pA->push(new
ArbExp(sp)); // feuille
break;
}
case ')' : { // reduce S -> (SOS)
p->pop(); // de ')'
if(
p->top() != 'S' ){
cout << "Erreur dans la pile '(' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'S'
arbd
= pA->top(); // le sous-arbre
DROIT en premier
pA->pop();
if( p->top() != '+' && p->top() != '*' ){
cout << "Erreur dans la pile 'S' : " <<
p->top() << endl;
return 1;
}
oparb
= p->top(); // l'opérateur pris
dans la pile
p->pop(); // de 'O'
if( p->top() != 'S' ){
cout << "Erreur dans la pile 'O' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'S'
arbg
= pA->top(); //
le sous-arbre GAUCHE en second
pA->pop();
if( p->top() != '(' ){
cout << "Erreur dans la pile 'S' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de '('
p->push('S');
pA->push(new
ArbExp(oparb, arbg, arbd)); // l'arbre construit
break;
} // case ')'
default : { cout << "Erreur symbole inconnu : "
<< sp << endl;
return 1;
}
} //
switch( p->top() )
Exécution :
jfp% ./a.out
((x+y)*((x+(y*(z+2)))*(y+3)))
( -- (
x -- ( (
+ -- x ( (
+ -- S ( (
y -- + S ( (
) -- y + S ( (
) -- S + S ( (
* -- ) S + S ( (
* -- S (
( -- * S (
( -- ( * S (
x -- ( ( * S (
+ -- x ( ( * S (
+ -- S ( ( * S (
( -- + S ( ( * S (
y -- ( + S ( ( * S (
* -- y ( + S ( ( * S (
* -- S ( + S ( ( * S (
( -- * S ( + S ( ( * S (
z -- ( * S ( + S ( ( * S (
+ -- z ( * S ( + S ( ( * S (
+ -- S ( * S ( + S ( ( * S (
2 -- + S ( * S ( + S ( ( * S (
) -- 2 + S ( * S ( + S ( ( * S (
) -- S + S ( * S ( + S ( ( * S (
) -- ) S + S ( * S ( + S ( ( * S (
) -- S * S ( + S ( ( * S (
) -- ) S * S ( + S ( ( * S (
) -- S + S ( ( * S (
* -- ) S + S ( ( * S (
* -- S ( * S (
( -- * S ( * S (
y -- ( * S ( * S (
+ -- y ( * S ( * S (
+ -- S ( * S ( * S (
3 -- + S ( * S ( * S (
) -- 3 + S ( * S ( * S (
) -- S + S ( * S ( * S (
) -- ) S + S ( * S ( * S (
) -- S * S ( * S (
) -- ) S * S ( * S (
) -- S * S (
$ -- ) S * S (
$ -- S
*+xy*+x*y+z2+y3
xy+xyz2+*+y3+**
OK
- Exercice : traiter de même la notation polonaise postfixée.
-
À comparer avec l'analyseur descendant pour la
même grammaire.
On doit distinguer deux états pour le non-terminal S
- soit il est empilé au-dessus d'un opérateur,
c'est-à-dire en position d'opérande gauche
et en ce cas il déclenche une action shift
- soit au-dessus d'un autre
S,
donc en position
d'opérande droit
et il déclenche alors une réduction. On le désignera par T
dans cette
situation.
Moyennant quoi nous sommes ramenés à la même situation que pour la
grammaire CP
à savoir que la donnée du symbole en sommet de pile suffit
- pour décider entre shift et reduce,
- et dans le second cas pour savoir quelle règle on doit
réduire.
fichier apref1.cpp
switch(
sp ){
case '+' :
case '*' :
case 'S' : { // shift
p->push(carlu);
i++;
break;
} // case '+' '*' 'S'
case 'x' :
case 'y' :
case 'z' :
case '1' :
case '2' :
case '3' : { // reduce S -> term
p->pop();
if(
p->top() == 'S' ){
p->push('T');
}else{
p->push('S');
}
break;
}
case 'T' : { // reduce S -> opSS
p->pop(); // de 'T'
if(
p->top() != 'S' ){
cout << "Erreur dans la pile 'T' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'S'
if( p->top() != '+' && p->top() != '*' ){
cout << "Erreur dans la pile 'S' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de l'opérateur
if(
p->top() == 'S' ){
p->push('T');
}else{
p->push('S');
}
break;
} // case 'T'
default : { cout << "Erreur symbole inconnu : "
<< sp << endl;
return 1;
}
} //
switch( p->top() )
}// while
Exécution :
jfp% ./a.out
*+xy*+x*y+z2+y3
+ -- *
x -- + *
y -- x + *
y -- S + *
* -- y S + *
* -- T S + *
* -- S *
+ -- * S *
x -- + * S *
* -- x + * S *
* -- S + * S *
y -- * S + * S *
+ -- y * S + * S *
+ -- S * S + * S *
z -- + S * S + * S *
2 -- z + S * S + * S *
2 -- S + S * S + * S *
+ -- 2 S + S * S + * S *
+ -- T S + S * S + * S *
+ -- T S * S + * S *
+ -- T S + * S *
+ -- S * S *
y -- + S * S *
3 -- y + S * S *
3 -- S + S * S *
$ -- 3 S + S * S *
$ -- T S + S * S *
$ -- T S * S *
$ -- T S *
$ -- S
OK
La construction de l'arbre d'expression vous est proposée en exercice.
-
Grammaire :
E -> E+TE -> T T -> T*FT -> F F -> vF -> i F -> (E)
-
Cette fois, la stratégie shift/reduce
est plus compliquée.
- D'une part il nous faut distinguer
deux états pour
T
et pour F (idée que nous avons déjà vue pour
la polonaise préfixée) :
- lorsque
T se trouve
empilé au-dessus de l'opérateur '+', il doit
déclencher la réduction E -> E+T
sinon il déclenche la réduction E -> T
;
- lorsque
F se trouve
empilé au-dessus de l'opérateur '*', il doit
déclencher la réduction T -> T*F
sinon il déclenche la réduction T -> F
.
Nous écrirons donc 'D' pour
'T'
au-dessus de '+', et ''G'
pour 'F' au-dessus de '*'.
- D'autre part,
T
(ou D) en sommet de pile provoque
tantôt une réduction, tantôt un shift :
- lorsque le prochain caractère à
traiter est
l'opérateur '
*', c'est shift,
car cet opérateur ne peut être là que par application de la règle T ->
T*F, il faut donc continuer à lire !
- dans tous les autres cas, reduce,
la règle à réduire étant univoquement déterminée gâce à la distinction
entre T et D.
fichier aprec2.cpp
switch( sp ){
case '(' :
case '+' :
case '*' :
case 'E' : { // shift dans tous les cas
p->push(carlu);
i++;
break;
} // case 'S' '+' '*'
case 'T' : { // shift ou reduce selon
carlu
if( carlu
== '*' ){ // shift
p->push(carlu);
i++;
}else{ //
reduce E -> T
p->pop(); // de 'T'
p->push('E');
}
break;
}
case 'D' : { // shift ou reduce selon
carlu
if( carlu
== '*' ){ // shift
p->push(carlu);
i++;
}else{ //
reduce E -> E+T
p->pop(); // de 'T'
if( p->top() != '+' ){
cout << "Erreur dans la
pile 'D' : " << p->top() << endl;
return 1;
}
p->pop(); // de '+'
if( p->top() != 'E' ){
cout << "Erreur dans la
pile '+' : " << p->top() << endl;
return 1;
}
// on laisse E en place
}
break;
} // case 'D'
case 'F' : { // reduce T -> F
p->pop();
if(
p->empty() || p->top() == '(' ){
p->push('T');
}else{ //
'+'
p->push('D');
}
break;
}// case 'F'
case 'G' : { // reduce T -> T*F
p->pop(); // de 'G'
if(
p->top() != '*' ){
cout << "Erreur dans la pile 'V' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de '*'
if(
p->top() != 'T' && p->top() != 'D'){
cout << "Erreur dans la pile '*' : " <<
p->top() << endl;
return 1;
}
// on
laisse T en place
break;
} //case 'G'
case 'x' :
case 'y' :
case 'z' :
case '1' :
case '2' :
case '3' : { // reduce F -> term
p->pop();
if(
p->empty() || p->top() == '(' || p->top() == '+' ){
p->push('F');
}else{ //
'*'
p->push('G');
}
break;
}
case ')' : { // reduce F -> (E)
p->pop(); // de ')'
if(
p->top() != 'E' ){
cout << "Erreur dans la pile '(' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'E'
if( p->top() != '(' ){
cout << "Erreur dans la pile 'E' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de ')'
if(
p->empty() || p->top() == '(' || p->top() == '+' ){
p->push('F');
}else{ //
'*'
p->push('G');
}
break;
} // case ')'
default : { cout << "Erreur symbole inconnu : "
<< sp << endl;
return 1;
}
} //
switch( p->top() )
Exécution
x+y*((z+3+x*y)+z)*2*z
+ -- x
+ -- F
+ -- T
+ -- E
y -- + E
* -- y + E
* -- F + E
* -- D + E
( -- * D + E
( -- ( * D + E
z -- ( ( * D + E
+ -- z ( ( * D + E
+ -- F ( ( * D + E
+ -- T ( ( * D + E
+ -- E ( ( * D + E
3 -- + E ( ( * D + E
+ -- 3 + E ( ( * D + E
+ -- F + E ( ( * D + E
+ -- D + E ( ( * D + E
+ -- E ( ( * D + E
x -- + E ( ( * D + E
* -- x + E ( ( * D + E
* -- F + E ( ( * D + E
* -- D + E ( ( * D + E
y -- * D + E ( ( * D + E
) -- y * D + E ( ( * D + E
) -- G * D + E ( ( * D + E
) -- D + E ( ( * D + E
) -- E ( ( * D + E
+ -- ) E ( ( * D + E
+ -- F ( * D + E
+ -- T ( * D + E
+ -- E ( * D + E
z -- + E ( * D + E
) -- z + E ( * D + E
) -- F + E ( * D + E
) -- D + E ( * D + E
) -- E ( * D + E
* -- ) E ( * D + E
* -- G * D + E
* -- D + E
2 -- * D + E
* -- 2 * D + E
* -- G * D + E
* -- D + E
z -- * D + E
$ -- z * D + E
$ -- G * D + E
$ -- D + E
$ -- E
OK
-
Elle présente l'intérêt d'une
simplification notable par rapport à
l'arbre de dérivation,
comme on l'a vu abondamment dans les cours précédents.
Cette simplification se traduit tout bonnement par des réductions dans
la pile qui ne produisent rien
dans la construction de l'arbre : les règles E
-> T, T -> F,
F -> (E).
Cette circonstance agréable est due à la compatibilité entre le
parcours ascendant
et la construction vue comme une évaluation symbolique.
Voici la chose (fichier aprec2Arb.cpp)
:
switch( sp ){
case '(' :
case '+' :
case '*' :
case 'E' : { // shift dans tous les cas
if( carlu
!= '$' ){
p->push(carlu);
}
i++;
break;
} // case '(' 'E' '+' '*'
case 'T' : { // shift ou reduce selon
carlu
if( carlu
== '*' ){ // shift
p->push(carlu);
i++;
}else{ //
reduce E -> T : on ne construit rien
p->pop(); // de 'T'
p->push('E');
}
break;
}
case 'D' : { // shift ou reduce selon
carlu
if( carlu
== '*' ){ // shift
p->push(carlu);
i++;
}else{ //
reduce E -> E+T : on construit
p->pop(); // de 'T'
arbd = pA->top();
pA->pop();
if( p->top() != '+' ){
cout << "Erreur dans la
pile 'D' : " << p->top() << endl;
return 1;
}
p->pop(); // de '+'
if( p->top() != 'E' ){
cout << "Erreur dans la
pile '+' : " << p->top() << endl;
return 1;
}
// on laisse E en place
arbg = pA->top();
pA->pop();
pA->push(new ArbExp('+', arbg,
arbd));
}
break;
} // case 'D'
case 'F' : { // reduce T -> F :
on ne construit rien
p->pop();
if(
p->empty() || p->top() == '(' ){
p->push('T');
}else{ //
'+'
p->push('D');
}
break;
}// case 'F'
case 'G' : { // reduce T -> T*F :
on construit
p->pop(); // de 'G'
arbd =
pA->top();
pA->pop();
if(
p->top() != '*' ){
cout << "Erreur dans la pile 'V' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de '*'
if(
p->top() != 'T' && p->top() != 'D'){
cout << "Erreur dans la pile '*' : " <<
p->top() << endl;
return 1;
}
// on
laisse T en place
arbg =
pA->top();
pA->pop();
pA->push(new ArbExp('*', arbg, arbd));
break;
} //case 'G'
case 'x' :
case 'y' :
case 'z' :
case '1' :
case '2' :
case '3' : { // reduce F -> term
p->pop();
if(
p->empty() || p->top() == '(' || p->top() == '+' ){
p->push('F');
}else{ //
'*'
p->push('G');
}
pA->push(new ArbExp(sp));
break;
}
case ')' : { // reduce F -> (E) :
on ne construit rien
p->pop(); // de ')'
if(
p->top() != 'E' ){
cout << "Erreur dans la pile '(' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de 'E'
if( p->top() != '(' ){
cout << "Erreur dans la pile 'E' : " <<
p->top() << endl;
return 1;
}
p->pop(); // de ')'
if(
p->empty() || p->top() == '(' || p->top() == '+' ){
p->push('F');
}else{ //
'*'
p->push('G');
}
break;
} // case ')'
default : { cout <<
"Erreur symbole inconnu : " << sp << endl;
return 1;
}
} //
switch( p->top() )
Exécution :
x+y*((z+3+x*y)+z)*2*z
mêmes mouvements de pile....
et
+x***y+++z3*xyz2z
xyz3+xy*+z+*2*z*+
OK