Que se passe-t-il ?
En demandant à mon navigateur favori
http://www.sainet.or.jp/%7Eeshibuya/hp.htmlj'obtiens une page Web où je lis notamment ceci :

Je clique sur le premier lien Classic Text et j'obtiens....
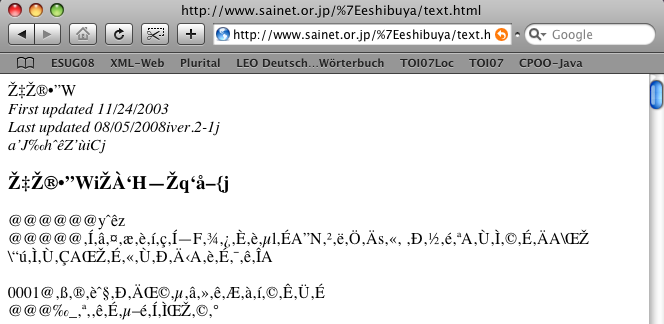
Nous pouvons tout de suite tirer deux conclusions de ce spectacle :
- Le fichier HTML ne
porte pas d'indication sur le codage des caractères qu'il emploie
(sans quoi cette indication aurait été mise à profit par le navigateur ) - Ce codage n'est pas
celui que le navigateur attend par défaut.
Cette image ne nous apporte aucune information supplémentaire, si ce n'est que le codage attendu par mon navigateur Firefox
n'est pas celui du navigateur précédent (Safari). Nos conclusions demeurent inchangées.
Attention ! Il s'agit ici des exemplaires de Firefox et de Safari
- présents sur mon ordinateur au moment où j'ai effectué les essais décrits dans l'énoncé de l'examen,
- et avec les réglages
que je leur avais donnés à l'époque, notamment en matière de codage
par défaut,
N'allez pas déduire de ce qui précède que Firefox et Safari attendent toujours, par défaut, les mêmes codages
(respectivement UTF-8 et Latin-1, comme on va le voir) !
À l'aide !
Seul remède applicable : essayer de trouver le codage du texte parmi ceux que propose le navigateur.
Si on ne le trouve pas chez Safari, essayer aussi avec Firefox !
Tout ce que nous en savons, c'est que ce codage est probablement un codage japonais.
Voyons ce que propose Safari :
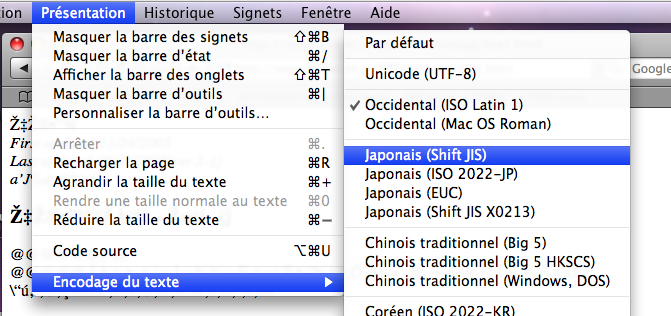
Cette image nous montre
- Que mon Safari attendait du Latin-1 (et non de l'UTF-8).
- Qu'il est capable de
traiter quatre codages japonais différents !
Essayons le premier....
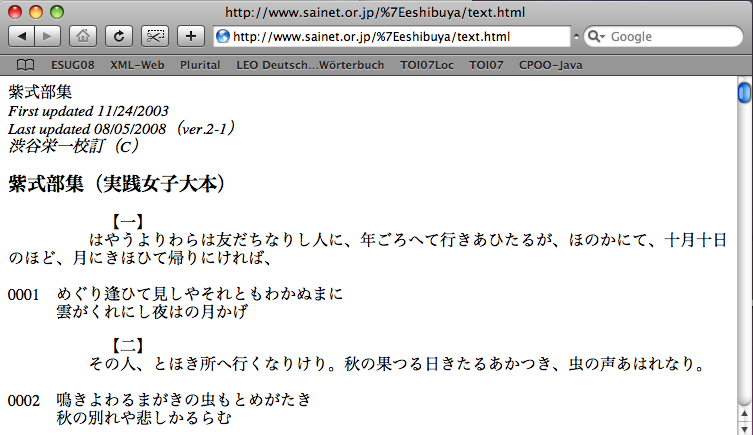
Ça marche ! Le texte était donc codé en Shift JIS (cf. cours n° 3)
Enfin, ça ne marche pas tout à fait : les japonisants voient bien qu'il s'agit ici du texte du recueil de poésises de Murasaki Shikibu
(紫式部集
Murasaki Shikibu Shû) et non pas, comme
annoncé, celui de son journal (紫式部日記 Murasaki
Shikibu Nikki).Mais ceci est une autre histoire...
Pour compléter la démonstration, vérifions que le codage attendu par mon Firefox n'est pas Latin-1 :
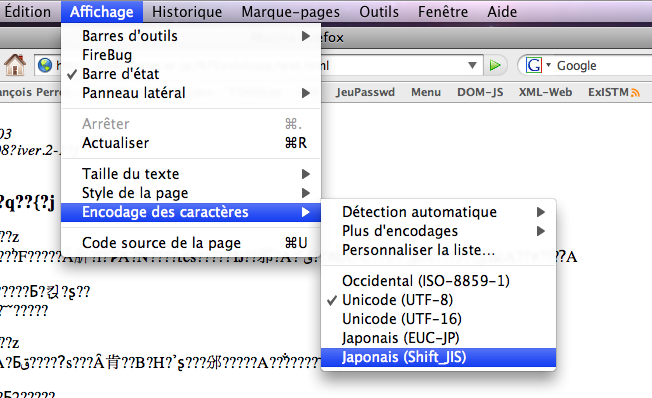
En effet, il attendait de l'UTF-8.
Lui aussi sait traiter le Shift-JIS... et lui aussi, bien sûr, nous révèle le recueil de poèmes et non pas le journal !
Un document Word
reçu par courrier électronique refusant de s'afficher dans mon mailer (sous MacOS 10.5), je ne peux l'ouvrir qu'en "texte seul"et voici ce que j'obtiens :
X & Y
ont le plaisir de vous inviter au cocktail annuel de líEDITE
de Paris
le 15 dÈcembre 2008 de 17 heures ‡ 20 heures
Caves du b‚timent Esclangon
(niveau Jussieu, entrÈe piÈtons par la rue Jussieu ‡ líangle de la rue
Jussieu et de la rue Cuvier)
UniversitÈ Pierre et Marie Curie
4, place Jussieu, Paris 5eQu'en concluez-vous sur les jeux de caractères en usage à l'émission et à la réception du message ?
Votre diagnostic doit expliquer toutes les anomalies observées !
Les anomalies en question sont au nombre de quatre
íau lieu de l'apostropheÈau lieu deé‡au lieu deà‚au lieu deâ
avec en plus l'apostrophe : il faut ici rappeler que la réalisation courante de l'apostrophe comme un simple "quote"
(comme c'est le cas dans le présent texte, par exemple) est une licence incompatible avec une typographie soignée.
L'apostrophe véritable ne figure pas dans le code ASCII !
Quant à l'espèce de virgule, n° 4, ce n'est évidemment pas une vraie virgule (ASCII 2C), mais une sorte de guillemet simple "fermant en bas",
appelée guillemet-virgule inférieur par Wikipédia.
Ces anomalies sont vraisemblablement imputables à des octets supérieurs à 127, interprétés différemment à l'émission et à la réception.
Comme il s'agit d'un texte produit par Microsoft Word et lu sur un Macintosh, on soupçonne qu'à l'émission on écrivait du Latin-1
(ou du Windows 1252) et qu'à la réception on attendait du MacRoman.
Pour démontrer cette hypothèse, il faut vérifier que dans les quatre cas l'octet correspondant au caractère anormal en MacRoman
est bien celui du caractère normal en Latin-1 (ou en Windows 1252).
íau lieu de l'apostrophe: 92- comme cet octet n'est pas utilisé par Latin-1, c'est de Windows 1252 qu'il s'agit.Èau lieu deé : E9‡au lieu deà : E0‚au lieu deâ : E2
Quod erat demonstrandum.
Un programme Perl
d'allure innocente (TxtOut.pl) lit le
fichier suivant [Ex.txt]Luc
12
Marie-Hélène 15
Joël
13
Françoise
09et produit comme résultat sur la sortie standard de ma machine (MacOS 10.5) : [
Res.txt]Luc 12
Marie-H?l?ne 15
Jo?l 13
Fran?oise 09Bon, ce programme a l'air de reproduire sa donnée en modifiant la mise en page (les notes ne sont plus alignées),
et en changeant au passage le codage des caractères : les lettres accentuées ne sont plus reconnues.
On va donc mener l'enquête dans cette direction.
Déçu, j'interroge hexdump sur la donnée d'abord :
00000000 4c 75 63 20 09 09 31
32 0a 4d 61 72 69 65 2d 48 |Luc ..12.Marie-H|
00000010 c3 a9 6c c3 a8 6e 65 09 31 35 0a 4a 6f c3
ab 6c |élène.15.Joël|
00000020 09 09 31 33 0a 46 72 61 6e c3 a7 6f 69 73
65 09 |..13.Françoise.|
00000030
30 39
0a
|09.|
00000033C'est clair, le fichier est codé en UTF-8 (
é = c3a9, è =
c3a8, ë
= c3
ab, ç = c3
a7).L'alignement des notes est réalisé par des tabulations (ASCII
09)
: parfois deux, parfois une seule.Nos pouvons en conclure que le système d'exploitation sur lequel cette expérience a été réalisée
(ou plutôt, l'utilitaire qui gère la sortie sur écran) accepte UTF-8 comme codage des caractères.
Même hexdump consent à afficher les caractères accentués !
sur le résultat ensuite :
00000000 4c 75 63 20 20 31 32
0a 4d 61 72 69 65 2d 48 e9 |Luc
12.Marie-H?|
00000010 6c e8 6e 65 20 20 31 35 0a 4a 6f eb 6c 20
20 31 |l?ne 15.Jo?l 1|
00000020 33 0a 46 72 61 6e e7 6f 69 73 65 20 20 30
39 0a |3.Fran?oise 09.|
00000030C'est non moins clair : la sortie est codée en Latin-1 (
é = e9,
è = e8, ë
= eb, ç = e7),
et les tabulations sont remplacées par deux espaces (ASCII
20).L'utilitaire d'affichage, qui se satisfaisait d'UTF-8, en revanche, n'accepte pas Latin-1 et il nous envoie
des points d'interrogation, que ce soit en sortie directe ou via hexdump.
C'est grave, docteur ?
Le tout est de savoir quel est le but poursuivi.
S'il s'agissait de traduire de l'UTF-8 en Latin-1 en remplaçant les tabs par des espaces, c'est gagné !
Si on voulait rester en UTF-8, alors il faut veiller à ce que Perl "sorte" avec le bon codage,
et ne pas se fier à son codage par défaut comme c'est probablement le cas dans le présent programme.
Ça ne doit pas être bien difficile...
Pouvez-vous m'expliquer pourquoi
ce qui dans un fichier de courrier en format source se lit :From:
=?ISO-2022-JP?B?GyRCPzkbKEIgGyRCTTNIfjtSGyhC?=<quelqun@quelquepart.org>
Reply-To: =?ISO-2022-JP?B?GyRCPzkbKEIgGyRCTTNIfjtSGyhC?=<quelqun@quelquepart.org>s'affiche dans la fenêtre de lecture de mon mailer :
De: 森由美子 <quelqun@quelquepart.org>
Réponse à: 森由美子 <quelqun@quelquepart.org>Il faut distinguer deux ordres de causes, la générale et la particulière.
- La cause générale est
naturellement l'obligation faite
aux en-têtes de mail d'être écrites en ASCII pur (voir cours
n° 3).
Pour transmettre des noms écrits en caractères chinois (ici, un nom japonais) il faut donc les coder en ASCII.
Le dispositif d'affichage du mailer-destinataire se charge de décoder et d'afficher le nom correctement,
de même qu'il traduit "From" par "De" et "Reply-To" par "Réponse à".
- La cause particulière
vise le procédé de codage
employé. Ici, on observe que la chaîne ASCII
=?ISO-2022-JP?B?GyRCPzkbKEIgGyRCTTNIfjtSGyhC?=
est décodée en quatre caractères 森由美子.
- La mention
?ISO-2022-JP?signale que ces caractères ont été au départ codés en ISO-2022-JP,
qui est sans doute une variante du système général ISO-2022 aperçu au cours n° 3 [vérification].
- Que signifie
B? je subodore que c'est 'B' comme 'Base64'... (voir encore le cours n° 3)
On trouve dans des contextes semblables 'Q' signifiant visiblement 'quoted-printable'.
- En effet, la chaîne
'
GyRCPzkbKEIgGyRCTTNIfjtSGyhC' ne contient que des lettres du codage en base64.
Mais l'hypothèse que la chaîne 'GyRCPzkbKEIgGyRCTTNIfjtSGyhC' code '森由美子' en base 64 se heurte à des considérations arithmétiques.
Cette chaîne a pour longueur 28, elle code donc un message de 28x6 = 168 bits, c'est-à-dire 21 octets.
Or, si nos quatre caractères sont codés en ISO-2022-JP sur 2 octets chacun, le message ne compte que 8 octets, nous sommes donc loin du compte !
Voyons ce qu'il en est en codant effectivement la chaîne '森由美子' en ISO-2022-JP grâce à un éditeur de textes adéquat,
(lien vers ce fichierjp2022.txt: le faire apparaître correctement dans votre navigateur est en soi un bon exercice !)
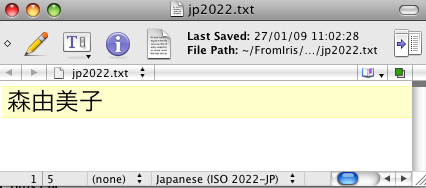
et en interrogeant le résultat par hexdump :
jfp% hexdump -C jp2022.txt
00000000 1b 24 42 3f 39 4d 33 48 7e 3b 52 1b 28 42 |.$B?9M3H~;R.(B|
0000000e
jfp%
14 octets ! et non pas 8... Pourquoi ? Décodons :
1b 24 42 3f 39 4d 33 48 7e 3b 52 1b 28 42
ESC $ B森 由 美 子ESC ( B
Wikipedia nous apprend ceci:
ISO-2022-JP. A widely used encoding for Japanese. Starts in ASCII and includes the following escape sequences
- ESC ( B to switch to ASCII (1 byte per character)
- ...........
- ESC $ B to switch
to JIS X 0208-1983 (2 bytes per character)
Nous en déduisons que la séquence 'ESC $ B' opère le passage de l'ASCII à un codage sur 2 octets,
et que la réciproque 'ESC ( B' opère le retour à l'ASCII.
Nos 14 octets sont donc parfaitement expliqués par le mode opératoire du codage ISO-2022-JP.
Bon, mais nous avions dit 21 octets ! Nous n'y sommes pas encore...
Voici un outil qui décode une chaîne en base64 et affiche les octets sans chercher à les interpréter.
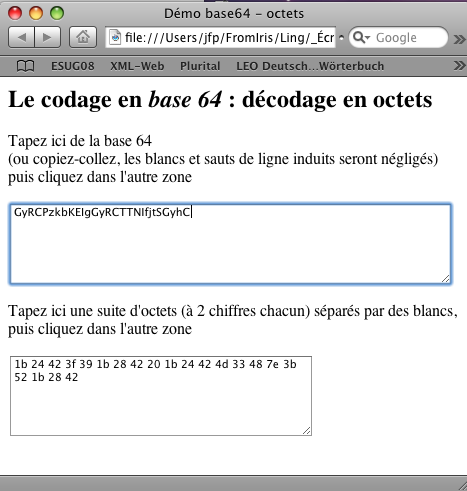
21 octets ! Décodons :
1b 24 42 3f 39 1b 28 42 20 1b 24 42 4d 33 48 7e 3b 52 1b 28 42
ESC $ B森ESC (BESC $ B由 美 子ESC ( B
Il y a donc dans le message un retour à l'ASCII pour insérer un espace après le premier caractère !
Lequel espace disparaît à l'affichage...
C'est peut-être que, dans '森由美子', '森' est le nom de famille et '由美子' le nom personnel.
Il est donc logique que ces deux parties soient distinguées dans le message.
Mais l'usage, au Japon, est de ne pas marquer de séparation entre le nom de famille (qui vient en premier)
et le nom personnel (qui vient en second) :
en n'affichant pas l'espace, le mailer ne fait que s'y conformer !
Felix qui potuit rerum cognoscere causas !
Mais je dois dire que je n'ai pas encore trouvé d'autre exemple d'espace interstitiel dans ce genre de situation.
- La mention