Un problème étrange
Je reçois d'une étudiante japonaise un message troublant : en lisant une des pages Web du cours, à l'adressehttp://pagesperso-systeme.lip6.fr/Jean-Francois.Perrot/inalco/cours07/Cours1/InterpNum/InterpNum.htmlelle voit apparaître des caractères chinois incongrus.
"Les caractères accentués sont souvent modifiés, mais ici, par exemple "
interprétation" est devenue "interpr
騁ation": non seulement "
é", "t"
aussi a disparu... Pourquoi ?"En effet, voici le spectacle insolite qui s'offre à ses yeux :
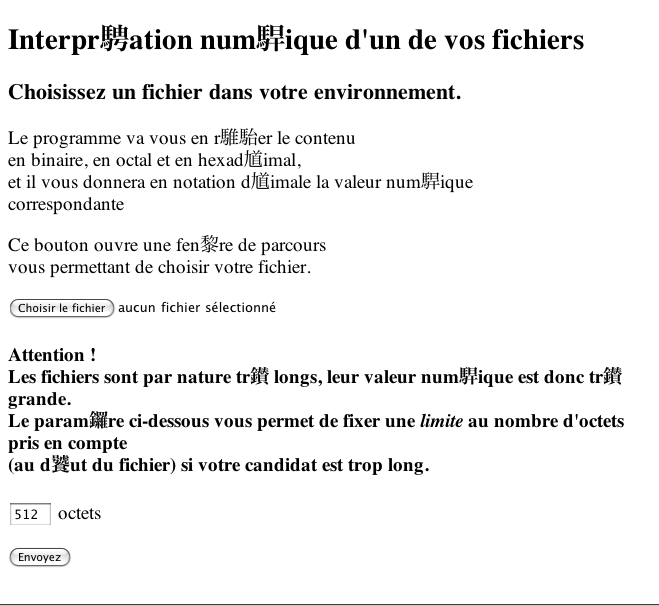
C'est sans doute que le navigateur attendait un certain codage pour le fichier et qu'il en a trouvé un autre...
sans avoir été prévenu !
Quel codage attendait-il et lequel a-t-il trouvé ?
Un premier indice pour vous mettre sur la piste :
Le système de codage Shift-JIS, très prisé des Japonais et souvent employé pour leurs pages Web,représente les caractères chinois sur deux octets.
voici les codes des caractères qui apparaissent ci-dessus :
- 騁
e974 - 駻
e972 - 騅
e976 - 駘
e96c - 馗
e963 - 黎
ea74 - 鑚
e873 - 鑼
e874 - 饕
e962
reste à le vérifier.
Enfin (faut-il vous le rappeler ?)
l'octet "e9" (resp. "e8",
"ea") code "é" (resp.
"è", "ê") en
Latin-1...et par conséquent (relisons au besoin notre code ASCII), en Latin-1
"
ét" s'écrit "e974", "ér"
s'écrit "e972", "év"
s'écrit "e976", etc,et "
èt" s'écrit "e874",
et "êt" s'écrit "ea74".Le doute n'est plus permis, l'effet observé est bien celui d'un navigateur réglé sur Shift-JIS et lisant par inadvertance du Latin-1.
Il est très facile de le reproduire ! Prenez votre navigateur favori, calez son codage par défaut sur Shift-JIS (voyez le corrigé de janvier)
et allez lire un fichier en français au hasard sur le réseau - la plupart d'entre eux sont en Latin-1 et ne le mentionnent pas,
de sorte que vous avez de grandes chances d'observer un spectacle analogue.
- Quel est le codage des caractères de
la page Web en
question ? Pourquoi ?
Latin-1, comme expliqué ci-dessus.
- Que se serait-il passé (avec le même
réglage du navigateur) si ce codage
avait été différent
?
Toute la question est celle de l'ambiguïté des octets. En général, une séquence d'octets écrite pour un certain codage
n'est pas interprétable dans un autre codage, elle est simplement erronée et donne lieu à des points d'interrogation.
Dans les codages à 8bits, les octets individuels sont souvent réinterprétables (comme dans le classique conflit
entre Latin-1 et MacRoman), ce qui donne lieu à des mots absurdes mais pas vraiment spectaculaires
(cf. l'exemple donné dans l'examen de janvier).
L'originalité de l'exemple présent est de tomber sur des séquences réinterprétables de deux octets,
et que cette réinterprétation fasse apparaître des caractères chinois compliqués, qui se détachent de manière saisissante
sur le fond du texte en ASCII.
Mais pour l'essentiel le phénomène n'a rien de nouveau !
La réponse à la question est donc : "Il se serait passé la même chose,
mais très probablement on aurait eu des points d'interrogation banals à la place de ces magnifiques caractères chinois !"
C'est par exemple ce que l'on voit si on code le fichier en MacRoman au lieu de Latin-1...
- Que faut-il faire pour éviter cette
surprise à nos amis
japonais ?
Toujours indiquer le codage dans le fichier !
En plaçant dans l'en-tête du fichier (au début de la balise<head>)
<meta http-equiv="content-type" content="text/html; charset= le-codage-choisi " />
comme il est dit au cours n° 4.
En général cette indication figure dans le fichier d'entrée du site.
Mais souvent elle disparaît des fichiers-annexes...
Il faut donc être vigilant, et ne créer de fichiers qu'avec un éditeur HTML
qui va systématiquement inscrire le codage dans l'en-tête.
Problème de transmission
Pour envoyer une référence à un ami indianiste, je suis amené à écrire dans un mél :"
Le texte en devanâgarî se trouve sur Wikisource :
http://wikisource.org/wiki/उपनिषद््."Mais mon mailer refuse d'afficher les caractères indiens et les remplace tous par des points d'interrogation :
"http://wikisource.org/wiki/???????".Inquiet au sujet du comportement possible du mailer de mon correspondant, je cherche une autre manière d'envoyer ma référence,
et sur la page de Wikisource elle-même je trouve "
retrieved
fromhttp://wikisource.org/wiki/%E0%A4%89%E0%A4%AA%E0%A4%A8%E0%A4%BF%E0%A4%B7%E0%A4%A6%E0%A5%8D"J'essaie cette URL, ça marche ! Et elle, je suis sûr de pouvoir l'envoyer sans crainte de malentendu...
Pourquoi les deux écritures "
http://wikisource.org/wiki/उपनिषद््"
et"
http://wikisource.org/wiki/%E0%A4%89%E0%A4%AA%E0%A4%A8%E0%A4%BF%E0%A4%B7%E0%A4%A6%E0%A5%8D"sont-elles équivalentes ?
Remarquons d'abord que la seconde forme énumère exactement les octets de la représentation en UTF-8
de 7 caractères indiens (cette représentation a été traitée en détail au cours n° 4) :
%E0%A4%89%E0%A4%AA%E0%A4%A8%E0%A4%BF%E0%A4%B7%E0%A4%A6%E0%A5%8De0a489, e0a4aa, e0a4a8,
e0a4bf, e0a4b7, e0a4a6, e0a48d.
Nous faisons l'hypothèse (facile à vérifier) que ces 7 caractères sont ceux du mot "
उपनिषद््".Dès lors, sous réserve que l'URL de la 1ère forme soit codée en UTF-8, la séquence d'octets qui part sur le réseau
est la même dans les deux cas ! Il n'est pas étonnant que le résultat soit identique...
Encodage inconnu
J'extrais le passage suivant d'un message envoyé par une liste de diffusion :La principale nouveaut� est la d�couverte
du
r�le central que joue la notion
math�matique
de complexit�, qui semble spontan�ment
mesur�e
par les �tres humains. Une situation
appara�t
comme pertinente d�s lors qu'elle est
moins
"complexe" que pr�vu.Voyez-vous une raison possible à cette anomalie ?
Je cherche à redonner à ce texte une forme acceptable en essayant de le sauvegarder dans un codage autre qu'UTF-8,
mais mon éditeur refuse cette opération. Quelle peut être la cause de ce refus ?
En général, quand on demande à recoder un fichier, l'éditeur affiche la liste des codages possibles.
En l'occurrence, avec TextEdit cette liste ne contient qu'UTF-8, UTF-16 et des codages chinois.
Tout simplement parce que, selon TextEdit, le fichier contient des octets qui ne sont compatibles qu'avec ces codages.
Notons qu'un autre éditeur peut avoir un autre jugement : TextWrangler accepte de recoder le fichier sans restriction,
en Latin-1 comme en MacRoman, mais dans les deux cas il produit un octet "
1A" qui ne figure dans aucun de ces jeux de caractères...Il y a donc bien un problème dans ce fichier !
Pour en avoir le cœur net, j'examine le texte avec hexdump :
00000000 4c 61 20 70 72 69 6e 63 69 70 61 6c 65 20 6e 6f |La principale no|
00000010 75 76 65 61 75 74 ef bf bd 20 65 73 74 20 6c 61 |uveaut� est la|
00000020 20 64 ef bf bd 63 6f 75 76 65 72 74 65 20 64 75 | d�couverte du|
00000030 20 0d 20 20 20 20 72 ef bf bd 6c 65 20 63 65 6e | . r�le cen|
00000040 74 72 61 6c 20 71 75 65 20 6a 6f 75 65 20 6c 61 |tral que joue la|
00000050 20 6e 6f 74 69 6f 6e 20 6d 61 74 68 ef bf bd 6d | notion math�m|
00000060 61 74 69 71 75 65 0d 20 20 20 20 64 65 20 63 6f |atique. de co|
00000070 6d 70 6c 65 78 69 74 ef bf bd 2c 20 71 75 69 20 |mplexit�, qui |
00000080 73 65 6d 62 6c 65 20 73 70 6f 6e 74 61 6e ef bf |semble spontan?|
00000090 bd 6d 65 6e 74 20 6d 65 73 75 72 ef bf bd 65 0d |?ment mesur�e.|
000000a0 20 20 20 20 70 61 72 20 6c 65 73 20 ef bf bd 74 | par les �t|
000000b0 72 65 73 20 68 75 6d 61 69 6e 73 2e 20 55 6e 65 |res humains. Une|
000000c0 20 73 69 74 75 61 74 69 6f 6e 20 61 70 70 61 72 | situation appar|
000000d0 61 ef bf bd 74 20 0d 20 20 20 20 63 6f 6d 6d 65 |a�t . comme|
000000e0 20 70 65 72 74 69 6e 65 6e 74 65 20 64 ef bf bd | pertinente d�|
000000f0 73 20 6c 6f 72 73 20 71 75 27 65 6c 6c 65 20 65 |s lors qu'elle e|
00000100 73 74 20 6d 6f 69 6e 73 0d 20 20 20 20 22 63 6f |st moins. "co|
00000110 6d 70 6c 65 78 65 22 20 71 75 65 20 70 72 ef bf |mplexe" que pr?|
00000120 bd 76 75 2e |?vu.|
00000124
Ai-je quelque espoir de retrouver le texte original ?
Hélas non ! Car notre outil fidèle nous révèle la présence de triplets d'octets "
ef bf bd", à raison d'un pour chaque point d'interrogation affiché.
D'une part ces triplets représentent en UTF-8 le caractère Unicode n°
xFFFD, qui symbolise l'erreur(à telle enseigne que les éditeurs refusent de le recoder, d'où les comportements bizarres évoqués précédemment).
D'autre part, sa présence montre que le fichier était corrompu avant son envoi :
ce n'est pas le processus de transmission qui a pu le faire apparaître, mais un traitement préalable,
au niveau de la liste de diffusion.
En tout état de cause, l'information sur les différentes lettres accentuées qui se trouvaient dans le texte original
est perdue, puisque les caractères correspondants ont tous été remplacés par ce "super point d'interrogation"
qu'est
U+FFFD.