Principe
Pour interroger la base au sujet d'un caractère répertorié dans le plan de base, connaissant son n° Unicode (en hexadécimal)il faut donner au navigateur une requête HTTP de la forme :
http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=lenumérohex[&useutf8=true]Le champ
useutf8 gouverne l'emploi d'UTF-8 vs
pdf pour illustrer certains des caractères qui apparaissent dans la pagep. ex. les variantes.
Exemple : 繼 =
U+7E7CEssayez !
http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=7E7C&useutf8=true
Mise en œuvre depuis le dictionnaire japonais en ligne WWWJDIC
- Accès au dictionnaire :
http://www.csse.monash.edu.au/~jwb/cgi-bin/wwwjdic.cgi?1C
Exemple : on demande le mot 日本語 (nihongo, la langue japonaise).
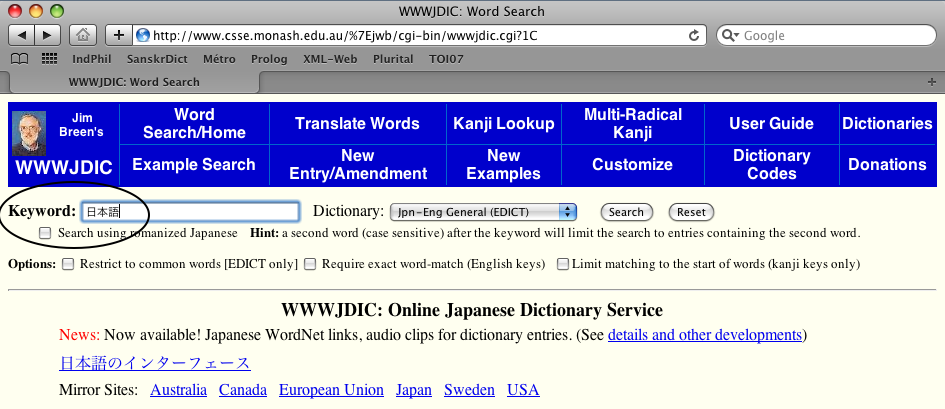
- Possibles acceptions du mot demandé : c'est la première
qui nous intéresse.
Un clic sur le boutonExamineva nous exhiber les trois kanjis qui la composent
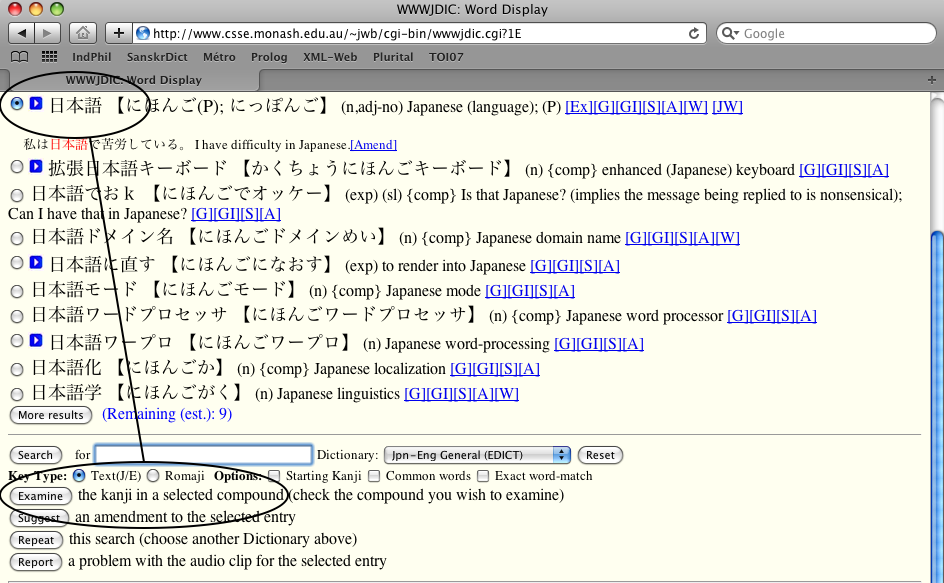
- Présentation des kanjis
avec leurs numéros dans divers catalogues, et notamment leur numéro Unicode qui porte un lien hypertexte vers la base Unihan.
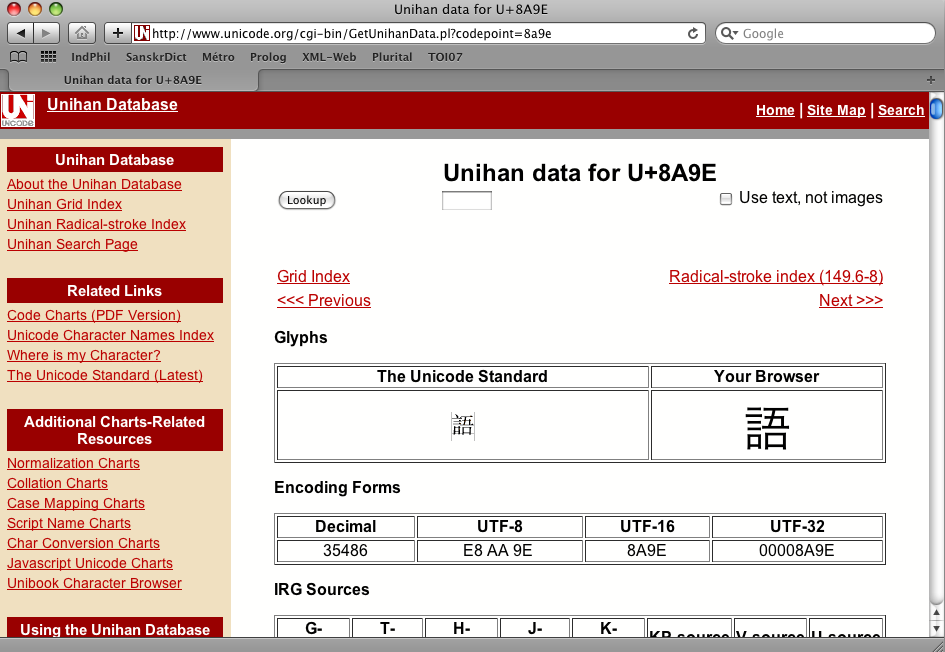
Nous choisissons le caractère 語 =U+8A9E

- Un clic sur ce lien appelle la page de la base Unihan.
Mise en œuvre pour le sino-vietnamien
-
Projet
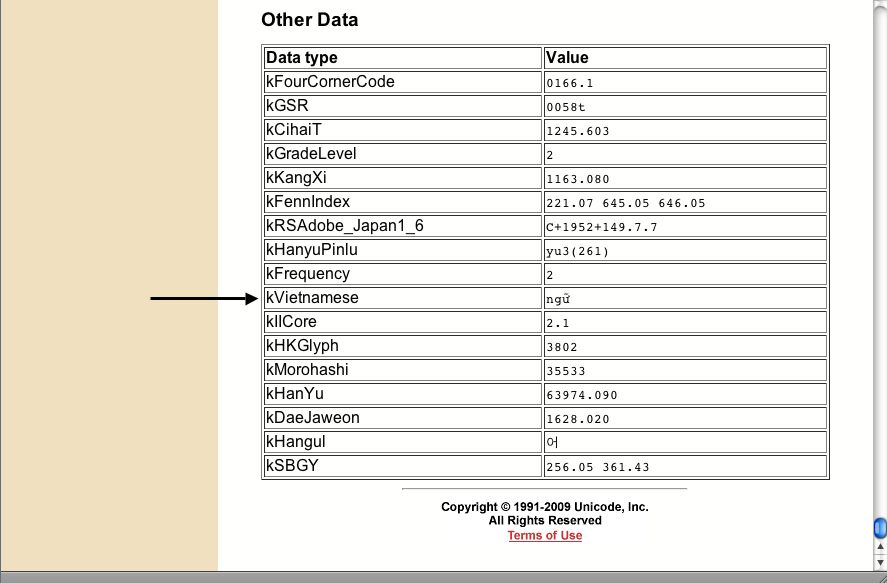
La prononciation sino-vietnamienne des caractères classiques (par opposition aux extensions nôm) est donnée par la base Unihan,
dans la section finale de chaque page, intituléeOther Data, sous l'indicateurkVietnamese.
Par exemple, pour le caractère 語 =U+8A9E, cette section nous informe qu'il se prononce ngữ (cf. 國 語 = quốc ngữ).
On désire exploiter cette information pour aider à la lecture de la littérature sino-vietnamienne.
L'idéal serait de coller dans une fenêtre un texte en caractères chinois et d'obtenir sa transcription sino-vietnamienne.
Pour l'instant, on procèdera caractère par caractère, comme indiqué ci-après.
-
Réalisation
Étant donné le caractère, on a son numéro Unicode, il est donc facile d'engendrer une requête à la base Unihan,
puis d'extraire du fichier l'information portée sous l'indicateurkVietnamese.
Comme ce processus est relativement lent,
mais que le nombre de caractères à examiner est faible par rapport à la mémoire dont disposent les machines modernes,
on enregistre chaque prononciation trouvée dans un fichier local,
de manière à répondre instantanément à une demande ultérieure visant le même caractère.
Voici l'outil que je vous propose, et voici un chantier où le pratiquer.