Une collaboration difficile
Dans le cadre d'un travail en commun sur un texte d'éloge académique, je reçois d'un de mes chers collègues un fichier-texte (provenant d'un document en Microsoft Word) dont voici un fragment :
- Ce texte est manifestement corrompu. Pouvez-vous en
déterminer la cause ?
Oui, la substitution d'un e accent grave majuscule à un e accent aigu minuscule est l'indice d'un codage original en Latin-1 ou en Windows-1252 lu par un logiciel qui attend du MacRoman.
Plus précisément, toutes les irrégularités observées sont expliquées par la table de correspondance :
Octet Windows Mac E8èËE9éÈF4ôÙE0àÍEAê‡
Toutes... sauf l'étrange carré dans "Kei?M Gijuku Daigaku..." que nous laisserons inexpliqué.
Les 5 correspondances énumérées ci-dessus suffisent pour conclure que nous sommes dans la situation classique d'un fichier écrit sur un PC et lu sur un Mac !
- Le contenu du fichier analysé par un éditeur hexadécimal
montre que le mal est profond. En voici un bref extrait :

Quel est le système de codage du fichier ?
[N.B. le caractère '‡' alias "DOUBLE DAGGER" porte le n°0x2021dans le catalogue Unicode.]
Voila qui est étrange... Les caractères sont séparés par des blancs ! D'où cela peut-il provenir ?
En tout cas, le codage est bien clair, c'est de l'UTF-8. En effet tous les caractères non-ASCII sont codés sur 2 octets, de la formeC3 XY, sauf le "DOUBLE DAGGER" qui en prend 3 :E2 80 A1.
Il est facile de décoder ces octets :
C3=1 1 0 0 0 0 1 1est bien le premier octet d'un code UTF-8 de 2 octets.
C3 88=1 1 0 0 0 0 1 1 1 0 0 0 1 0 0 0code l'octet1 10 0 1 0 0 0=C8qui est le n° Unicode deÈ
(puisque pour la plage Latin-1 le n° Unicode est aussi l'octet représentant le caractère dans le codage Latin-1).
De même
C3 99=1 1 0 0 0 0 1 1 1 0 0 1 1 0 0 1code l'octet1 10 1 1 0 0 1=D9qui est le n° Unicode deÙ.Enfin,
E2 80 A1 = 1 1 1 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 0 0 1sur 3 octets code
0 0 1 00 0 0 0 0 01 0 0 0 0 1=2021qui est bien le n° Unicode du "DOUBLE DAGGER" donné dans l'énoncé.
Le mal est en effet profond, car après la mauvaise lecture "Mac" du fichier d'origine "PC", les caractères mal lus ont été recodés en UTF-8. La correspondance entre octets a ainsi disparu.
- Comme le document complet comporte plusieurs pages, il faut
trouver un procédé "automatique" pour le restaurer.
Puis-je espérer me tirer d'affaire avec un éditeur de texte seulement capable de changer le codage du fichier ?
Hélas non ! Les caractères fautifs étant codés sans ambiguïté en UTF-8 dans le fichier, un changement de codage aura pour seul effet de les recoder sans les modifier en tant que caractères. Le fichier recodé sera tout aussi illisible que l'actuel.
- Je m'aperçois que mon éditeur hexadécimal est capable de
sauvegarder son contenu d'octets dans un fichier-texte en lui
appliquant un codage décidé par l'utilisateur. Youpiie ! Je suis
sauvé !
Pourquoi et comment ?
En imposant un codage, l'éditeur hexadécimal transforme des octets en caractères. Il suffit d'avoir les bons octets et de leur imposer le bon codage. On va procéder comme suit :
- Le fichier donné, qui est en UTF-8 comme nous venons
de le voir, sera recodé par l'éditeur de textes en MacRoman.
Appelons fichier "Mac" le résultat de ce recodage : ses octets sont ceux du fichier "PC" d'origine.
- On ouvre le fichier "Mac" avec l'éditeur hexadécimal
et on lui impose le codage Latin-1.
On a gagné !
- Le fichier donné, qui est en UTF-8 comme nous venons
de le voir, sera recodé par l'éditeur de textes en MacRoman.
Une expérience vietnamienne
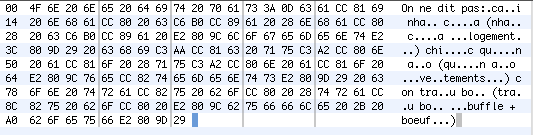
On trouve dans un texte en pdf sur la grammaire du vietnamienhttp://ressources-cla.univ-fcomte.fr/gerflint/Mekong1/nguyen_lan_trung.pdfle passage suivant :

|
 |



From Russia with Love
Voici une partie de l'en-tête d'un message qui est arrivé dans ma boîte aux lettres :From: =?koi8-r?Q?=E0=D2=C9=CA_=ED=C9=D2=CF=CE=C5=CE=CB=CF?=
<tallman@inbox.ru>
To: esug-list@lists.esug.org
Subject:
=?koi8-r?Q?Re[2]=3A_[Esug-list]_GSoC_idea=3A_GLORP_&_Magritte_integration?=
On vous demande de traduire les champs "
From" et "Subject"
de cet en-tête.Pour vous aider, voici un extrait de la page
http://fr.wikipedia.org/wiki/KOI8-R
| x0 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cx | ю | а | б | ц | д | е | ф | г | х | и | й | к | л | м | н | о |
| Dx | п | я | р | с | т | у | ж | в | ь | ы | з | ш | э | щ | ч | ъ |
| Ex | Ю | А | Б | Ц | Д | Е | Ф | Г | Х | И | Й | К | Л | М | Н | О |
| Fx | П | Я | Р | С | Т | У | Ж | В | Ь | Ы | З | Ш | Э | Щ | Ч | Ъ |
On sait que les en-têtes des messages véhiculés par SMTP doivent être
en ASCII 7 bits. Les libellés comme ceux des champs
Ici, la mention
La traduction du champ "
Юрий_Мироненко.
Celle du champ "
On observe également que le soulignement "
Le cours n° 3 se borne à évoquer l'apparition de "=3D" puisque 0x3D est le code de "=" en Windows, mais il ne dit rien de "
Une enquête supplémentaire [
La traduction correcte du champ "
et celle du champ "
sachant que le codage était rendu nécessaire par la présence du deux-points après "
From:
et
Subject: ci-dessus ont pour but de communiquer en ASCII des
contenus codés dans d'autres systèmes (cf. Cours n° 3).Ici, la mention
=?koi8-r? annonce que le contenu est codé
en Код Обмена Информацией, 8 бит, et la mention ?Q?
déclare que le transport se fait avec la convention quoted-printable.
Dans ce système, les octets non-ASCII sont donnés en hexadécimal,
chacun étant préfixé par le signe "=".La traduction du champ "
From" se fait donc mécaniquement
grâce à la page de code obligeamment fournie dans l'énoncé :Юрий_Мироненко.
Celle du champ "
Subject" conduit à s'interroger : son
contenu est entièrement en ASCII, pourquoi donc a-t-il été codé ?On observe également que le soulignement "
_"qui apparaît
dans la traduction précédente n'est pas très esthétique.Le cours n° 3 se borne à évoquer l'apparition de "=3D" puisque 0x3D est le code de "=" en Windows, mais il ne dit rien de "
=3A"
ni du soulignement...Une enquête supplémentaire [
http://www.commentcamarche.net/contents/base/quoted-printable.php3]
nous apprend que, en quoted-printable,- le caractère espace (ASCII
20), le caractère deux-points (ASCII3A) et quelques autres sont considérés comme spéciaux, et sont codés explicitement. - l'espace est codé par le soulignement (d'où il suit que le
soulignement lui-même doit être codé
=5F)
- le deux-points est codé
=3A, etc.
La traduction correcte du champ "
From" est donc Юрий
Мироненко avec un espace, et celle du champ "
Subject" :Re[2]: [Esug-list] GSoC idea: GLORP & Magritte integrationsachant que le codage était rendu nécessaire par la présence du deux-points après "
Re[2]" et après "idea".