Trois axes principaux
Le standard Unicode met en exergue 10 principes, dont l'exégèse ne manque pas d'intérêt
(Desgraupes, chap. 1, Haralambous, chap. 2).
De notre point de vue d'utilisateurs, je retiens les trois points suivants :
Universalité
- Tous les systèmes d'écriture textuelle du monde (pas tous les répertoires de signes).
- Convergence avec la norme ISO/IEC 10646.
- Négociation permanente avec les instances réglementaires,
mais le consortium reste fermement entre des mains américaines...
Abandon de l'équation un caractère = un octet
- Un total de 1 114 112 caractères potentiels (= 17 × 65.536, 17 plans de 216 places chacun)
En hexadécimal, de 0x000000 à 0x10FFFF.
(Donc en principe 3 octets, mais les ordinateurs ne raisonnent que par puissances de 2)
- Pour la pratique courante le premier plan suffit ! BMP = Basic Multilingual Plane
C'est heureux, car la plupart des langages de programmation qui fondent sur Unicode leur notion de caractère,
à commencer par Java, se limitent à 16 bits - ce qui correspond à l'intention initiale !
- Plusieurs formats de représentation en machine employant de 1 à 4 octets.
- Un total de 1 114 112 caractères potentiels (= 17 × 65.536, 17 plans de 216 places chacun)
Une véritable élaboration théorique du concept de caractère
- Un catalogue de caractères qui est une base de données accessible en ligne.
- Chaque caractère y est identifié par son numéro (en décimal ou en hexa -
Desgraupes préfère employer le terme anglais code-point),
et aussi par son nom (en anglais et en petites capitales) :
p. ex. n° 304 = x0130 LATIN CAPITAL LETTER I WITH DOT ABOVE
- Ces données sont exploitées par des algorithmes complètement spécifiés dans la norme.
- Un catalogue de caractères qui est une base de données accessible en ligne.
Organisation du catalogue Unicode
-
Chacun des 17 plans est divisé (de manière normative) en blocs
correspondant chacun à une unité culturelle.
Pour chacun de ces blocs, le site d'Alan Wood propose une page contenant diverses informations
ainsi que la liste des caractères du bloc avec leur nom officiel.
Cette page permet de savoir immédiatement si votre navigateur dispose d'une police représentant
un caractère donné, et si nécessaire elle vous aide à trouver une telle police sur le réseau.
On observe au passage que si chaque bloc est installé dans une certaine plage de numéros,
il est rare que tous les numéros de la plage soient effectivement attribués.
En tirant un nombre au hasard entre 0 et 1 114 111, on a donc des chances non-négligeables de tomber
sur un numéro non attribué, comme on pourra le vérifier avec l'outil expérimental présenté ci-après.
-
Nous nous limiterons ici au BMP (Basic Multilingual Plane - en français PMB plan de base multilingue ? ).
Cet ensemble correspond grosso modo au projet initial d'Unicode,
qui était de coder tous les caractères du monde avec deux octets.
Ses 65536 places possibles sont réparties (à titre indicatif) en 8 zones, qui sont
- General Scripts Area : de 0x0000 à 0x1FFF : 8 192 places
Tout sauf les caractères chinois et leurs dérivés
- Symbols Area : de 0x2000 à 0x2FFF : 4096 places
Symboles variés (ponctuation, flèches, mathématiques)
- CJKV Ideographs Area : de 0x3000 à 0x3FFF : 4 096 places
Signes de ponctuation, syllabaires japonais, clefs pour les dictionnaires
mais pas les caractères chinois eux-mêmes !
- CJK Unified Ideographs Area : de 0x4000 à 0x9FFF : 24 576 places
La masse imposante des idéogrammes chinois.
- Asian Scripts Area : de 0xA000 à 0xD7FF : 14 336 places
L'écriture Yi (minorité chinoise) et le syllabaire coréen Hangul.
- Surrogates Area : de 0xD800 à 0xDFFF : 2 048 places
Usage technique réservé au codage UTF-16. Ne représente aucun caractère.
- Private Use Area : de 0xE000 à 0xF8FF : 6 400 places
Utilisable ad libitum par les applications informatiques.
Ne fera jamais l'objet d'une normalisation.
- Compatibility & Specials Area : de 0xF900 à 0xFFFF : 1 792 places
fourre-tout dû au besoin de rester compatible avec les systèmes préexistants
(tout ce qui a été codé doit pouvoir se coder en Unicode).
- General Scripts Area : de 0x0000 à 0x1FFF : 8 192 places
-
Voici un coup d'œil d'ensemble, suivant la classification des blocs proposée par Alan Wood.
Exercice : repérer dans cette énumération les blocs qui n'appartiennent pas au BMP.
La page de Wikipédia http://fr.wikipedia.org/wiki/Table_des_caractères_Unicode
fournit un accès systématique par plages de numéros, avec explications.
- On a souvent besoin de parcourir l'espace Unicode en y repérant les jeux de caractères
disponibles sur son ordinateur. Plus précisément, étant donné une plage de caractères Unicode,
il est utile de savoir quelles polices sont disponibles sur sa machine.
(Au lieu de chercher, pour chaque police, quelles plages elle recouvre, comme on le fait
sous Windows en examinant la Table des caractères, ou (bien mieux) avec TrueType Explorer.)
Par exemple, étant donné un texte utilisant plusieurs jeux de caractères comme celui-ci,
êtes-vous en mesure de varier les polices pour obtenir une belle présentation ?
C'est ce que permet de faire la palette de caractères sur Mac OS X (cf. cours n° 2),
d'une manière un peu détournée (il faut aller chercher les variantes de police).
Le logiciel UnicodeChecker de Earthlingsoft fournit un outil parfait pour cela.
Promenade dans le BMP
Nous proposons ci-après une sélection de sujets qui nous intéressent particulièrement.Pour chacun d'entre eux, nous renvoyons aux pages d'Alan Wood qui traitent les différents blocs concernés.
Si vous constatez que votre machine ne possède pas de police pouvant afficher les caractères en question,
empressez-vous d'y remédier, en suivant les conseils d'Alan Wood !
Avant d'entamer notre périple, notons qu'il n'y a pas encore grand'chose à voir dans les plans supérieurs.
Même un alphabet rare comme le glagolitique a trouvé place dans le plan de base (0x2C00 - 0x2C5F).
Le seul exemple que je puisse vous proposer est le gotique (0x10330 – 0x1034F).
La police MPH 2B Damase vous permettra (gratuitement) de visualiser ces deux alphabets - et quelques autres.
Malheureusement, il n'y a pas beaucoup de ressources dont la mise en œuvre nécessite cet équipement :
les textes en gotique sont publiés dans une transcription romanisée (rien d'étonnant puisque le gotique est une langue germanique)
y compris la Bible de Wulfila chez Titus et le commentaire Skeireins, de sorte que
le seul exemple d'emploi de gotique Unicode que je connaisse est une démo de notre Wikipédia nationale !
Quant au glagolitique, je n'ai rien trouvé - je suis preneur de toute référence !
L'alphabet latin et ses extensions
- Latin de base = ASCII
- Supplément Latin-1 = ISO-8859-1
- Latin étendu A = la plupart des caractères des langues européennes
- Latin étendu B (nécessaire pour le roumain, par exemple)
- L'alphabet phonétique international (IPA) est clairement dérivé de l'alphabet latin.
Ces cinq premiers blocs sont consécutifs, allant de 0 à 687 (0x0000 à 0x02AF).
Le suivant en revanche est "nettement plus loin", de 7680 à 7935 (0x1E00 – 0x1EFF).
- Extensions supplémentaires (en général, symboles utilisés dans les notations phonétiques
et dans les transcriptions savantes, p. ex. ḫ pour le خ arabe)
- Latin de base = ASCII
-
L'alphabet grec, ancien et moderne, et ses dérivés
- Le grec moderne ayant adopté le système d'accentuation monotonique
est plus simple à écrire que le grec ancien dont les trois accents, les deux esprits
et le iota souscrit posent de redoutables problèmes typographiques.
Aussi la plage du grec ancien est-elle située "plus loin" que celle du grec moderne,
elle suit le bloc Latin Extended Additional que nous venons de voir.
[La documentation en ligne relative à l'alphabet grec est surabondante.
Sur la différence entre les notations monotonique et polytonique (sujet sensible qui
se rattache historiquement à la querelle de la langue), voir l'article de Wikipédia en anglais.
Pour un exemple d'écriture monotonique, voyez Wikipédia en grec : Ελληνική γλώσσα
On trouve sur le réseau plusieurs sites qui proposent des collections plus ou moins complètes
de textes grecs anciens en Unicode polytonique. Mon préféré est la
Bibliotheca Augustana.]
- L'alphabet cyrillique vient juste après le grec moderne dans le catalogue Unicode.
Il est suivi d'un supplément de 16 caractères déclarés "pour la langue Komi".
[Une recherche rapide montre qu'il s'agit d'une langue ouralo-altaïque plus connue en français
sous le nom de zyriène, et que les caractères en question relèvent de l'alphabet Molodtsov,
qui (selon Wikipedia) a été en usage entre 1920 et 1930.
Comme quoi Unicode a bien vocation à enregistrer tous les systèmes d'écriture
présents et passés !]
- L'alphabet arménien (qui vient immédiatement après le cyrillique) et l'alphabet géorgien
(qui n'arrive qu'après les écritures indiennes) sont tous deux dérivés du grec.
Ils sont géographiquement voisins mais ils notent des langues profondément différentes.
Illustration du géorgien.
[Je peux vous en dire plus sur le système graphique de l'arménien, avec quelques exemples
et liens utiles.
Le cas du géorgien est plus simple, mais il pose tout de même quelques questions intéressantes.]
- Le grec moderne ayant adopté le système d'accentuation monotonique
Les alphabets notant des langues sémitiques : arabe, hébreu et éthiopien
- L'alphabet arabe s'écrit de droite à gauche, bien que les caractères apparaissent de droite à gauche
dans le fichier, grâce à l'algorithme bidirectionnel dont nous reparlerons au cours suivant.
Il maintient dans sa forme imprimée les formes cursives des manuscrits (exemple).
Ces formes ne sont pas enregistrées comme caractères, au prix d'un travail demandé au logiciel de visualisation,
dont nous reparlerons également.
Le bloc Unicode correspondant contient de nombreux caractères supplémentaires qui servent
à écrire le persan, l'ourdou, le panjabi, le sindhi qui sont des langues indo-européennes.
- L'alphabet hébreu s'écrit aussi de droite à gauche, mais ses lettres sont bien séparées.
Cinq lettres prennent une forme différente en position finale.
D'une manière diamétralement opposée au traitement de l'arabe,
ces formes finales sont enregistrées comme des caractères Unicode à part entière
(comme c'était déjà le cas dans les tables à 8 bits : le faible nombre de formes à enregistrer explique cette différence).
Le bloc hébreu contient aussi les lettres doubles propres au yiddish, les signes de ponctuation,
ainsi que les signes vocaliques et les accents nécessaires à l'impression du texte massorétique de la Bible.
Exemple d'hébreu moderne sans voyelles, exemple de texte biblique.
- Le syllabaire éthiopien
s'écrit de gauche à droite !
Outre l'amharique, langue nationale de l'Éthiopie (exemple), il sert à noter le guèze,
langue religieuse (longtemps enseignée à l'École Pratique des Hautes Études, à Paris,
par Maxime Rodinson), et le tigrigna, langue nationale de l'Érythrée (exemple).
Le bloc éthiopien est complété par un supplément, qui le suit immédiatement,
et par une extension située nettement "plus loin" dans le BMP, ajoutés dans la version 4.1 d'Unicode.
[On peut être surpris de ne trouver pas moins de cinq (5) pages en écriture éthiopienne
parmi les quelque cinquante traductions publiées pour What is Unicode ? (état du 23/11/06):
en dehors de l'amharique et du tigrigna déjà cités, on voit en effet
le blin, le sebatbeit et le xamtanga, ces deux derniers demandant
des caractères supplémentaires ajoutés avec la version Unicode 4.1
- je le sais parce que mon ordinateur ne possède pas les polices nécessaires ! -
Le blin est une langue couchitique parlée en Érythrée, encore peu écrite, mais activement défendue
par des groupes d'émigrés vivant en Scandinavie.
Le xamtanga est une autre langue couchitique parlée en Éthiopie par 150 000 personnes.
Le sebatbeit, ou sebat bet gurage appartient au groupe gurage, qui fait partie du domaine sémitique.
Il est plus connu des linguistes sous le nom de chaha.]
- L'alphabet arabe s'écrit de droite à gauche, bien que les caractères apparaissent de droite à gauche
-
Les écritures indiennes
Elles dérivent toutes d'une source commune, l'écriture brahmi,
y compris les écritures qui notent les langues dravidiennes.
Comme cette dernière, ce sont des écritures syllabiques avec une voyelle implicite a,
et elles notent l'absence de voyelle par des procédés de ligature
qui compliquent singulièrement leur emploi (nous en reparlerons).
- La plus célèbre est la devanâgari (divine et urbaine), qui est employée
par le hindi, le marathi, le népalais.
Le sanscrit, qui s'est autrefois écrit dans toutes les écritures indiennes,
est aujourd'hui imprimé exclusivement en nâgari.
- Voici, à titre d'échantillon, deux écritures qui sont très proches de la devanâgari,
la gujarâti (qui est en somme une devanâgari dont on a supprimé le trait horizontal),
et la gurmukhi (une des écritures du panjabi, celle des Sikhs).
- A contrario, l'écriture tamoule a des formes et des ligatures qui l'éloignent nettement
de la devanâgari. Illustration.
L'écriture télougou, plus arrondie, a beaucoup de charme - à condition d'avoir une police adéquate !
- La plus célèbre est la devanâgari (divine et urbaine), qui est employée
-
Le cas du japonais
Les trois systèmes qui composent l'écriture japonaise (kanjis, hiragana, katakana) sont traités essentiellement
- par deux blocs Unicode spécifiques pour les deux syllabaires
- par la collection générale des caractères chinois pour les kanjis (voir plus loin).
Le syllabaire hiragana est traité par le bloc 12352–12447 (0x3040 – 0x309F),
et le katakana par le bloc immédiatement suivant 12448–12543 (0x30A0 – 0x30FF),
étendu par un petit bloc supplémentaire destiné à noter d'autres langues comme l'aïnou.
L'ordonnance traditionnelle de ces syllabaires offre un parallèle non fortuit avec celle des écritures indiennes.
Le bloc intitulé kanbun se rapporte à la pratique japonaise de l'écriture en chinois.
Il contient 16 caractères à usage fort technique : explications dans Wikipédia (fr) et Wikipedia (de)
qui se complètent assez bien, et Wikipedia (en) pour plus de détails.
On notera que c'est le même exemple qui sert dans les trois langues ...
- par deux blocs Unicode spécifiques pour les deux syllabaires
-
Les caractères chinois et la question de la Han Unification
La partie principale des caractères chinois occupe le bloc CJK Unified Ideographs, de 0x4E00 à 0x9FBB,
soit 20 924 places ( Alan Wood renonce à les afficher !).
Il est assorti de deux extensions A et B, dont la première le précède dans le catalogue :
-
CJK Unified Ideographs Extension A est consacré au cantonais (qui fut la langue officielle de Hong Kong)
voyez Hong Kong Supplementary Character Set.
Il contient une série lacunaire de 20 caractères, d'abord de 3400 à 3409, puis répartis jusqu'à 4DB5.
-
CJK Unified Ideographs Extension B, au contraire, est logé dans le Plan 2
(donc avec des numéros de plus de 16 bits).
A fortiori, Alan Wood renonce à afficher ses 42 711 caractères... - Et ce n'est pas fini ! Wikipedia annonce deux nouvelles extensions D et C pour épuiser tous les répertoires connus.
(nous en sommes à la version 5 depuis le 14/07/2006)
l'horizon restait limité aux 65.536 places disponibles avec 16 bits.
L'heure était donc à la restriction plutôt qu'au foisonnement.
D'autre part, les langues qui font appel à l'écriture chinoise (CJKV : chinois, coréen, japonais, vietnamien)
entretiennent des rapports compliqués avec le chinois (voyez la notion de kanbun en japonais - ci-dessus -
et le chữ nho en vietnamien). Le japonais et le coréen ont inventé des syllabaires, le vietnamien a procédé
différemment (modifications, ajout de caractères, voyez chữ nôm). Mais dans tous les cas les caractères chinois
sont restés la référence culturelle de base. Avec, certes, des prononciations différentes, et peut-être des détails,
des styles de calligraphie différents.
Dans ce contexte, ce qu'on appelle l'unification Han consiste à prendre au pied de la lettre
l'affirmation de l'identité des caractères, et à constituer une seule collection au lieu de quatre :
avantage évident du point de vue des normalisateurs, et notamment d'Unicode !
À l'époque (fin des années 80) cet avantage a été jugé décisif [Histoire de cette normalisation, en pdf].
L'inconvénient est que les différences nationales sont renvoyées aux polices de caractères,
donc en fait proprement gommées.
Un kanji japonais est ainsi effectivement un caractère chinois comme un autre !
On peut noter que cette rigueur théorique ne s'applique pas aux caractères dits simplifiés
utilisés en Chine continentale (mais pas à Taïwan). Dans Unicode, la version traditionnelle
et la version simplifiée d'un même idéogramme sont deux caractères différents.
Explications détaillées dans Wikipedia : Han unification.
Traitement approfondi pour le japonais.
Exposé d'ensemble avec développement particulier sur le japonais dans Document numérique cité ci-dessus.
-
CJK Unified Ideographs Extension A est consacré au cantonais (qui fut la langue officielle de Hong Kong)
Représentation en machine : généralités
-
UTF-32, UTF-16, UTF-8
Une fois abandonnée l'équation un caractère = un octet, la question se pose du format de représentation.
Pour des raisons historiques, les différents formats en usage portent le nom générique de Unicode Transfer Format,
alias UTF.
- Si on veut un format de taille fixe (nombre fixe d'octets pour chaque caractère),
le seul choix compatible à la fois avec le nombre de caractères à représenter (1 114 112)
et avec la technologie informatique est celui de 4 octets, ou 32 bits, appelé UTF-32.
Il suffit d'écrire le numéro du caractère en tant que nombre entier sur 32 bits, donc (vu la taille de ce nombre)
avec un premier octet nul dans tous les cas, et un second octet également nul pour tous les caractères
du Basic Multilingual Plane.
Ce procédé a l'avantage de la simplicité conceptuelle, et l'inconvénient de prendre de la place
(4 fois plus qu'un codage sur 8 bits).
- Si on accepte un format de taille variable (nombre d'octets dépendant du caractère considéré),
on a le choix entre un module de base de deux octets et un module de base d'un seul octet.
- Si on choisit un module de deux octets, soit 16 bits : UTF-16
on utilise un seul module pour tous les caractères du BMP,
et deux modules (quatre octets) pour ceux des autres plans.
Plus compliqué, mais plus économique en place, surtout si on sort peu du BMP.
- Si on choisit un module d'un octet, soit 8 bits : UTF-8
on utilise un seul module pour les caractères ASCII (7 bits),
et deux, trois ou quatre modules (octets) pour les autres.
Nettement plus compliqué, mais encore plus économique en place,
et surtout compatible avec l'ASCII !
Tout fichier ne contenant que des caractères ASCII 7 bits est ipso facto un fichier UTF-8.
Avantage considérable en pratique...
- Si on choisit un module de deux octets, soit 16 bits : UTF-16
- Si on veut un format de taille fixe (nombre fixe d'octets pour chaque caractère),
-
Quel est le but poursuivi ? Travail local ou communication à distance ?
Il faut distinguer deux orientations dans la représentation des caractères Unicode en machine, selon le but poursuivi :
- travail local (édition, au sens anglais du terme,
ou plus généralement toute espèce de calcul sur le texte)
- communication : réalisation d'un fichier qui sera envoyé à travers le réseau à d'autres machines.
- le travail local ne connaît à peu près aucune entrave, vu la puissance de calcul des machines modernes ;
- la communication en revanche doit se préoccuper
- des différences de comportement entre machines (hétérogénéité des processeurs)
- des conventions en vigueur sur le réseau.
- L'hétérogénéité des processeurs se manifeste dans l'ordre de traitement des octets
(processeurs gros-boutiens et petit-boutiens) ce qui oblige à des contorsions pour indiquer
l'option choisie dans un fichier codé en UTF-16 ou en UTF-32 (à l'aide d'un BOM : Bit Order Mark).
Par exemple, le logiciel de traitement de corpus Unitex travaille sur des fichiers codés en UTF-16 petit-boutien.
- Les conventions en vigueur visent les jeux de caractères exigés ou attendus par les
différents protocoles de transmission (par exemple l'ASCII 7 bits pour le protocole SMTP).
En ce qui nous concerne, le point important est le choix d'UTF-8 comme jeu de caractères
par défaut dans le format XML.
- Il
faut enfin observer que les attentes des logiciels de traitement ne
sont pas toujours clairement exprimées.
C'est le cas notamment pour les compilateurs et interprètes des langages de programmation.
Par exemple, un programme Java contenant des lettres accentuées a des chances de ne pas s'exporter correctement
d'une machine à l'autre - ce qui se comprend aisément.
Le cas de JavaScript est très net : le code contenu dans les fichiers JavaScript (extension ".js") doit être écrit
en ASCII pur (7 bits). Tout autre caractère doit être donné par son n° Unicode, sous la forme "\uHHHH"
(voir plus loin).
Il y a donc en fait deux genre de textes bien différents :
- les textes documentaires destinés à des lecteurs humains, par le truchement de logiciels
comme les navigateurs Web,
les éditeurs de textes ou les gestionnaires de courrier - les textes-programmes destinés à des compilateurs et interprètes.
- les textes documentaires destinés à des lecteurs humains, par le truchement de logiciels
comme les navigateurs Web,
Nous laisserons de côté les préoccupations relatives au travail local, en nous bornant à constater que
les logiciels traitant des textes utilisent souvent UTF-16 ou UTF-32 pour représenter les caractères
en mémoire centrale (buffer). Pour en savoir plus sur ces codages, voyez Wikipedia en anglais
(UTF-16, UTF-32).
Nous nous concentrons ici sur les questions de communication, pour lesquelles UTF-8 est le codage
de choix, en raison de sa diffusion croissante (tout Wikipedia !) et de sa compatibilité avec l'ASCII "pur".
- travail local (édition, au sens anglais du terme,
UTF-8 : principe et mise en œuvre
-
Principe
- On part de l'idée de représenter les 128 premiers caractères (ASCII) sur un seul octet, comme par le passé.
Ces octets ont comme caractéristique d'avoir un premier bit nul.
- Tous les autres caractères seront représentés par au moins deux octets.
Il faut alors distinguer le premier octet du (ou des) octet(s) suivant(s).
Ils ne peuvent pas commencer par "0" car c'est le privilège des octets ASCII.
On décide que :
- les octets suivants commenceront par "10"
- le premier octet commencera par "110" ou par "1110" ou par "11110", etc,
le nombre de "1" initiaux donnant le nombre total d'octets dans la représentation du caractère
(en pratique, 2, 3 ou 4) . - Exemples : trois octets 11100000 10100100 10001011
deux octets 11001110 10110001
mais un seul octet 01111000 (ASCII : on reconnaît la lettre minuscule "x")
- les octets suivants commenceront par "10"
- Ainsi, chacun des octets suivants peut porter 6 bits utiles (les 2 premiers étant fixés)
tandis que le premier octet peut en porter 5, 4 ou 3, suivant le nombre de ses suivants.
Avec ce système,
- un code UTF-8 de deux octets porte 11 bits utiles (5+6),
(suivant le "squelette" 110xxxxx 10yyyyyy)
- un code UTF-8 de trois octets porte 16 bits utiles (4+6+6),
(suivant le "squelette" 1110xxxx 10yyyyyy 10zzzzzz)
- et un code UTF-8 de quatre octets porte 21 bits utiles (3+6+6+6),
(suivant le "squelette" 11110xxx 10yyyyyy 10zzzzzz 10tttttt)
- un code UTF-8 de deux octets porte 11 bits utiles (5+6),
- Pour déterminer le code UTF-8 d'un numéro Unicode donné, il suffit de :
- écrire ce numéro en binaire, et supprimer les zéros initiaux ;
en fonction du nombre de bits utiles, déterminer le nombre d'octets UTF-8 ;
- décomposer le binaire de droite à gauche en tranches de 6 bits,
plus une tranche de 5, 4 ou 3 (en complétant au besoin par des zéros à gauche) ; - et "remplir" le squelette décrit ci-dessus en 3.
- écrire ce numéro en binaire, et supprimer les zéros initiaux ;
- Exemples :
- DEVANAGARI LETTER VOCALIC R, n° 2315 = x090B
en binaire 00001001 00001011, 12 bits utiles, il faut donc 3 octets UTF-8
squelette 1110xxxx 10yyyyyy 10zzzzzz
décomposition 4+6+6 : 0000 + 1001 00 + 00 1011
résultat : 11100000 10100100 10001011, en hexa 0xE0A48B.
- GREEK SMALL LETTER ALPHA, n° 945 = x03B1
en binaire 00000011 10110001, 10 bits utiles, donc 2 octets UTF-8,
squelette 110xxxxx 10yyyyyy
décomposition 5+6 : 011 10 + 11 0001
résultat : 11001110 10110001, en hexa 0xCEB1.
- DEVANAGARI LETTER VOCALIC R, n° 2315 = x090B
- Propriétés du codage UTF-8 :
- Le dernier chiffre hexadécimal du numéro Unicode d'un caractère se retrouve identique
comme dernier chiffre de sa représentation en UTF-8.
- Plus le numéro Unicode est grand, plus le code UTF-8 correspondant, vu comme un nombre entier,
est grand.
En termes mathématiques, le codage UTF-8 est une application injective des entiers dans les entiers
qui est croissante par rapport à l'ordre naturel.
- Conséquences pratiques
- Les caractères de numéros inférieurs à 128 sont représentés en UTF-8 sur un octet (ASCII).
- Ceux dont les numéros sont compris entre 128 et 2047 (= x07FF = 0000 0111 1111 1111),
par deux octets :
c'est le cas de toutes les versions de l'alphabet latin énumérées ci-dessus
(donc de toutes nos "lettres accentuées"), du grec monotonique (mais pas polytonique),
du cyrillique, de l'arménien (mais pas du géorgien),
de l'hébreu et de l'arabe (mais pas de l'éthiopien).
- Tout le reste du BMP (entre 2048 et 65535) est codé sur trois octets.
Voyez par exemple le cas de l'écriture devanâgari.
Ces triplets d'octets sont aisément reconnaissables sur un dump en hexadécimal,
car le premier octet commence par "E" (en binaire 1110).
Exemple : le caractère géorgien Ⴋ (U+10AB = GEORGIAN CAPITAL LETTER MAN), en UTF-8 0xE182AB.
- Les caractères appartenant aux plans supérieurs sont codés sur quatre octets,
avec un octet initial commençant par "F" (en binaire 1111).
Exemple : le caractère gotique 𐌰 (U+10330 = GOTHIC LETTER AHSA), en UTF-8 0xF0908CB0.
- Les caractères de numéros inférieurs à 128 sont représentés en UTF-8 sur un octet (ASCII).
- Le dernier chiffre hexadécimal du numéro Unicode d'un caractère se retrouve identique
- On part de l'idée de représenter les 128 premiers caractères (ASCII) sur un seul octet, comme par le passé.
Notation et expérimentation :
- Répétons qu'il faut bien distinguer
- la désignation du caractère (nommer le caractère)
- par son n° (en décimal ou en hexa) suivnt une syntaxe qui dépend du contexte :
- en HTML/XML : &#lenumérodec; ou &#xlenumérohex;
sont des entités permettant de désigner un caractère Unicode dans un contexte "tout ASCII".
Ce procédé a l'avantage de ne rien supposer du côté du logiciel de traitement
(voir ci-après les question de mise en œuvre d'UTF-8).
Il est donc préféré des traditionnalistes attachés à iso-8859-1 !
Pour l'observer, demandez à voir le code-source de la page.
Exemples :
- le site très élaboré présentant la bible hébraïque cité précédemment.
- un excellent site espagnol consacré à la culture arabe, en particulier à la poésie
e.g. la page sur le poète préislamique عـنترة بن شداد
Bien évidemment, son emploi systématique conduit à occuper beaucoup de place en mémoire
(7 octets par caractère !). Mais des textes même substantiels ne pèsent rien à côté
des mégaoctets exigés par les images ou par la vidéo !
- le site très élaboré présentant la bible hébraïque cité précédemment.
- en Java : '\ulenumérohex' est une constante de type char
Attention ! le type primitif char est limité à la plage 0-6536 (2 octets),
sa valeur maximale est donc '\uFFFF'.
Réciproquement, tout entier de cette plage peut être affecté à une variable de type char,
avec conversion automatique : si on exécute
char x = 2315; char y = '\u090B';
les deux variables x et y contiennent le même caractère
(l'expression booléenne x==b vaut true).
- en JavaScript (qui ne connaît pas les constantes de type caractère) :
la forme \ulenumérohex peut (doit) être employée dans une chaîne,
et pour calculer on emploie la fonction chr appliquée au numéro
vu comme une valeur entière, fonction qui renvoie une chaîne monocaractère
donc chr(lenumérodec) ou chr(0xlenumérohex)
- en HTML/XML : &#lenumérodec; ou &#xlenumérohex;
- par son nom officiel (en Perl)
- Exemple : le caractère Unicode n° 304 = x0130 LATIN CAPITAL LETTER I WITH DOT ABOVE
peut être désigné en HTML/XML par İ ou par İ, en Java par '\u0130'
et en JavaScript par chr(304) ou par chr(0x130)
- par son n° (en décimal ou en hexa) suivnt une syntaxe qui dépend du contexte :
- sa réalisation matérielle
laquelle prend deux aspects (dissymétriques) :
- codage en octets (ici, UTF-8)
Exemple : LATIN CAPITAL LETTER I WITH DOT ABOVE ==> sur 2 octets C4B0
- affichage via une police (à condition qu'elle soit présente sur la machine !)
Exemple : LATIN CAPITAL LETTER I WITH DOT ABOVE ==> İ
- codage en octets (ici, UTF-8)
entre chevrons (comme ils sont produits par certains logiciels) :
Exemple : LATIN CAPITAL LETTER I WITH DOT ABOVE ==> en UTF-8 sur 2 octets <C4><B0>
- la désignation du caractère (nommer le caractère)
-
Exemple à bien comprendre : Voici le même texte
Ça, c'est mon frère René et ça c'est ma sœur Iñès.
d'abord en deux codages à 8 bits, Mac Roman et iso-8859-1 (Windows) :
On peut constater que, dans les deux cas, les caractères non-ASCII sont représentés
par un seul octet, mais qu'à chaque fois ce sont des octets différents !
- <82>a, c'est mon fr<8F>re Ren<8E> et <8D>a c'est ma s<CF>ur I<96><8F>s.
- <C7>a, c'est mon fr<E8>re Ren<E9> et <E7>a c'est ma s<9C>ur I<F1><E8>s.
Et le voici en UTF-8, montrant clairement les deux octets nécessaires pour tout caractère non-ASCII :
<C3><87>a, c'est mon fr<C3><A8>re Ren<C3><A9> et <C3><A7>a c'est ma s<C5><93>ur I<C3><B1><C3><A8>s.
- <82>a, c'est mon fr<8F>re Ren<8E> et <8D>a c'est ma s<CF>ur I<96><8F>s.
- Pour faciliter l'expérimentation, voici un outil qui vous permettra de confronter les différents aspects
d'un caractère Unicode :
- son numéro que vous pouvez donner en décimal ou en hexa, et voir en binaire
- sa représentation UTF-8, en hexa (notation à chevrons) et en binaire
- son nom officiel (en lecture seule).
ne sont prises en compte que lorsque vous cliquez une première fois en dehors de ce champ.
- Répétons qu'il faut bien distinguer
Mise en œuvre
Entrer & sortir :
les machines modernes avec écran et clavier nous laissent croire que lire et écrire ne font qu'un
c'est faux !
L'écriture (fabrication d'un fichier) et la lecture (interprétation) sont deux processus dissymétriques.
Cette dissymétrie est masquée par la puissance des machines et par la bonne adéquation des outils (clavier - écran - logiciels).
Mais la puissance est relative et l'adéquation dépend du but poursuivi !
- Côté entrée : deux étapes successives
- Écriture dans un outil d'édition par tout moyen à votre disposition
(ils sont nombreux : menu d'insertion, donnée explicite du nom du caractère, clavier, palette, etc).- Note technique : cette écriture fait entrer les caractères dans le
buffer de l'outil,
qui loge en mémoire centrale en le recodant.
Notez que l'utilisateur n'est en général pas informé de ce codage interne,
(l'éditeur JEdit faisant exception : il déclare ouvertement
que sa représentation interne est UTF-16).
- Note technique : cette écriture fait entrer les caractères dans le
buffer de l'outil,
- Sauvegarde dans un fichier sur disque en spécifiant le codage UTF-8.
Notez que les modalités de cette spécification varient beaucoup avec le logiciel employé.
Par exemple, sur Mac OS X :
- L'éditeur de textes TextEdit répond à la commande
Fichier>Enregistrer sous...
par une fenêtre de dialogue où la question du codage est posée clairement.
- L'éditeur HTML Netscape Composer en revanche distingue
Fichier>Enregistrer sous...
de Enregistrer en changeant de codage
et il adopte un comportement diversifié suivant le choix de l'utilisateur.
L'analyse de ce comportement n'est pas sans intérêt...
- La version 1 de Microsoft Word pour Mac OS X (déjà ancienne) répond à la commande Fichier>Enregistrer sous...
par une fenêtre de dialogue où la question du codage est posée comme cas particulier de modèle de document,
le choix de Texte unicode conduisant à une sauvegarde en format texte UTF-16.
- L'éditeur de textes JEdit distingue explicitement
- le buffer en mémoire centrale (où les caractères sont représentés en UTF-16)
- du fichier sur disque, dont le codage courant est affiché au bord inférieur de la fenêtre
et peut être modifié par une commande adéquate (voir la documentation)
- le buffer en mémoire centrale (où les caractères sont représentés en UTF-16)
Il convient donc de se renseigner soigneusement sur l'usage du logiciel employé,
de préférence avant d'avoir à sauvegarder son travail en urgence,
car un mauvais choix de codage peut conduire à la perte irrémédiable de l'information acquise...
- L'éditeur de textes TextEdit répond à la commande
Fichier>Enregistrer sous...
- Écriture dans un outil d'édition par tout moyen à votre disposition
- Côté sortie : avertir le logiciel de traitement qu'il doit "lire" en UTF-8
- pour un éditeur prenant un fichier sur le disque,
à l'ouverture du fichier (en général, codage par défaut donné dans les préférences de l'outil).
Là aussi les mœurs des logiciels sont diverses, et il convient de chercher où l'information pertinente doit être fournie.
Tous n'ont pas la limpidité de TextEdit...
- pour un logiciel recevant le fichier par le réseau,
par un message spécifique avec un type MIME comme Content-Type: text/plain ou text/xml
assorti de la mention "charset=UTF-8".
C'est d'ordinaire le serveur de fichiers qui en a la charge, il est bon de contrôler son action.
- Pour un courrier envoyé par SMTP, le logiciel émetteur devra envoyer un en-tête (header) :
"Content-Type: text/plain; charset=UTF-8"
- Pour un fichier HTML envoyé par un serveur Web comme Apache, c'est la déclaration du serveur
qui a priorité. Tout dépend alors de sa configuration, qui peut fort bien imposer iso-8859-1
(voir le cours 3). Si tel est le cas, il faut demander au responsable changer la directive en
AddDefaultCharset Off.
En supposant que le serveur soit muet sur ce point, l'auteur du fichier doit faire sa déclaration
en ajoutant comme premier élément de la partie <head> de son fichier un élément ainsi conçu:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
et en observant que tous les caractères précédents, à savoir <DOCTYPE....> <html xmlns:...><head>
sont de l'ASCII 7 bits, donc déchiffrables sans ambiguïté.
- Toujours en HTML, dans un formulaire (balise <form>) pour s'assurer que les chaînes tapées
par l'utilisateur sont transmises au serveur en UTF-8 (et non pas selon la fantaisie du navigateur),
il convient d'ajouter dans la balise l'attribut accept-charset="UTF-8".
- Enfin, la norme HTML prévoit qu'un lien hypertexte peut porter un attribut charset
destiné à informer le navigateur du jeu de caractères employé dans la page-cible
(http://fr.selfhtml.org/html/liens/lienstypes.htm#langue_caracteres)
ce qui est fort utile lorsque le lien désigne une page en texte simple (ni HTML, ni XML),
car en ce cas le navigateur applique son codage par défaut, qui est souvent Latin-1.
Hélas, les navigateurs n'en ont cure... et il faut méditer la note de SelfHTML :
"Il n'est pas établi si et comment un navigateur WWW affiche de telles mentions."
C'est bien dommage !
- En ce qui concerne les chaînes traitées, et notamment affichées, par JavaScript ou par Java,
il convient de noter deux points :
- Pour JavaScript comme pour Java, tous les caractères d'une chaîne sont en Unicode .
En particulier, la longueur d'une chaîne est le nombre de ses caractères et non pas
celui de ses octets. De même pour les fonctions d'accès charAt() et charCodeAt().
JavaScript traitera donc correctement les chaînes que lui transmet le navigateur.
Pour la communication avec ce dernier, voir ci-dessus.
- Le code JavaScript proprement dit (celui qui s'écrit dans les fichiers ".js" envoyés au
navigateur en même temps que le HTML), comme il a été dit plus haut, doit être rédigé
entièrement en ASCII, pour éviter les malentendus avec des navigateurs imprévisibles.
Des caractères non-ASCII peuvent apparaître aussi bien dans les identificateurs
que dans les constantes de chaînes, mais ils doivent ête donnés sous la forme
"\ulenumérohexa" comme en Java.
On écrira par exemple, en supposant que la variable chn contient une chaîne :
alert ('"'+ chn + '" ne repr\u00E9sente pas un nombre d\u00E9cimal !');
pour obtenir :
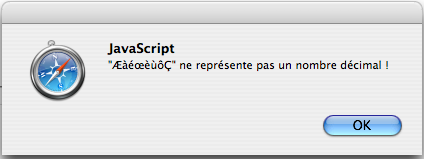
- Pour JavaScript comme pour Java, tous les caractères d'une chaîne sont en Unicode .
- Pour un courrier envoyé par SMTP, le logiciel émetteur devra envoyer un en-tête (header) :
- pour un éditeur prenant un fichier sur le disque,
- Côté entrée : deux étapes successives