
Project Description
Large-scale computation without synchronisation
Large-scale on-line services including social networks and multiplayer games handle huge quantities of frequently changing shared data. Maintaining its consistency is relatively simple in a centralised cloud, but no longer possible due to increased scalability requirements. Instead, data must replicated across several distributed data centres, requiring new principled approaches to consistency that will be explored by the SyncFree project.Marc Shapiro - Encapsulating replication, high concurrency and consistency with CRDTs - Curry On 2015
Marc Shapiro & Nuno Preguiça - CRDTs in Practice - Code Mesh 2015
SyncFree is a European research project running October 2013 to December 2016. It is funded by the European Union, grant agreement n°609551.
Motivation
The internet is in the middle of an amazing growth of interactive services involving millions of concurrent users partially thanks to scalable algorithms that provide weak or relaxed data sharing such as MapReduce or Content Delivery Networks (CDNs). However, many essential applications require strong sharing, i.e. maintaining the consistency of shared mutable data. Examples include virtual wallets, advertising platforms, collaborative social networks, information networks (e.g., healthcare), massive multi-player online games, and online mobile games. These applications have extreme requirements in number of users, amount of data, and geographical span. Maintaining strong consistency at this scale is becoming a major technological barrier for many online services due to issues including network delays, operational costs, and hardware failures.
Approach
Maintaining data consistency is relatively simple in tightly coupled client/server systems through the use of data centres and centralised clouds. But the time where a single giant data centre was sufficient is already ancient history. Especially in Europe, the future points to a multiplication of loosely coupled, widely distributed localized data centres of all sizes. Current solutions for ensuring data consistency in these systems require highly specialized, expert technology and investment, in particular because failures and disconnection, time-outs and retries are readily present in the internet.
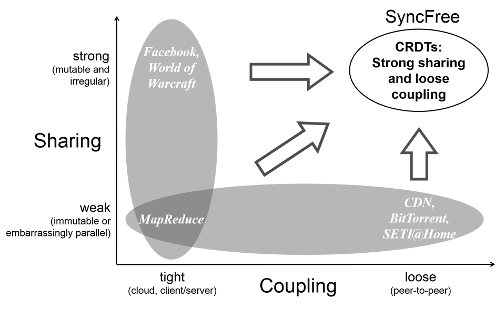
SyncFree proposes to solve these problems by using a recent, principled approach to enabling strong sharing called Conflict-Free Replicated Data Types (CRDTs). CRDTs avoid the complexities of ad-hoc approaches, while maintaining the scalability advantage. The insight is that, by following some simple mathematical principles (for example commutativity), distributed updates can occur without synchronization, while still ensuring a level of data consistency that enables the development of powerful applications. Furthermore, CRDTs ease development by encapsulating the replication and concurrency properties of common shared objects, such as sets, maps, sequences, or graphs.
Preliminary, small-scale experiments show that CRDTs have many advantages, such as locality of data, low latency of updates, and full-time availability, and that they require less computation and network resources. Maintaining consistency for real-world applications with millions of concurrent updates is our future challenge. First, the SyncFree project will document the requirements of such applications, both in natural and in mathematical language, thus investigating their theoretical and practical scalability limits. A set of core CRDT algorithms will then be designed for these applications, studying trade-offs between scalability, consistency, and security, while examining the computational, network, and storage costs. The project will then explore how to provide additional guarantees, such as transactional updates and bounded storage (needed by certain applications) without impacting the advantages of CRDTs.
Impact
The SyncFree project will advance both the theory and practice of large-scale application architectures, and especially of CRDTs and related mechanisms. As the SyncFree industrial partners already have large user bases and feel the need for increased scalability in their applications, the project will include an extreme-scale crowd-sourced experiment, pushing the scalability needs of real world applications. An open-source library of CRDTs, to be used in future scalable distributed applications will be made available, leaving a lasting and beneficial impact far beyond the end of the project.


