Problème à traiter
- Depuis la réforme imposée par Atatürk en 1928, le turc de Turquie s'écrit avec un alphabet latin étendu
de 29 lettres (alphabet bicaméral : majuscules & minuscules), dont 7 caractères non-ASCII :
A, B, C, Ç, D, E, F, G, Ğ, H, I, İ, J, K, L, M, N, O, Ö, P, R, S, Ş, T, U, Ü, V, Y, Z [Wikipédia]
- le "c cédille" (le même qu'en français), qui note l'affriquée sourde 'tch'
minuscule ç Unicode n° 231 = x00EF LATIN SMALL LETTER C WITH CEDILLA
majuscule Ç Unicode n° 199 = x00C7 LATIN CAPITAL LETTER C WITH CEDILLA
En UTF-8 : <C3><A7> et <C3><87>
- le g "mou" (yumuşak G, variante phonologique du 'g' entre voyelles)
minuscule ğ Unicode n° 287 = x011F LATIN SMALL LETTER G WITH BREVE
majuscule Ğ Unicode n° 286 = x011E LATIN CAPITAL LETTER G WITH BREVE
En UTF-8 : <C4><9F> et <C4><9E>
- le "i sans point" minuscule : ı (voyelle d'arrière)
Unicode n° 305 = x0131 LATIN SMALL LETTER DOTLESS I
En UTF-8 : <C4><B1>
- le "i majuscule avec point" İ (pour le distinguer du i sans point majuscule)
Unicode n° 304 = x0130 LATIN CAPITAL LETTER I WITH DOT ABOVE
En UTF-8 : <C4><B0>
- le "o tréma" (voyelle d'avant), important pour l'harmonie vocalique
minuscule ö Unicode n° 246 = x00F6 LATIN SMALL LETTER O WITH DIAERESIS
majuscule Ö Unicode n° 214 = x00D6 LATIN CAPITAL LETTER O WITH DIAERESIS
En UTF-8 : <C3><B6> et <C3><96>
- le s cédille (note la chuintante sourde, fr. "ch")
minuscule ş Unicode n° 351 = x015F LATIN SMALL LETTER S WITH CEDILLA
majuscule Ş Unicode n° 350 = x015E LATIN CAPITAL LETTER S WITH CEDILLA
En UTF-8 : <C5><9F> et <C5><9E>
- le "u tréma" (voyelle d'avant), idem pour l'harmonie vocalique
minuscule ü Unicode n° 252 = x00FC LATIN SMALL LETTER U WITH DIAERESIS
majuscule Ü Unicode n° 220 = x00DC LATIN CAPITAL LETTER U WITH DIAERESIS
En UTF-8 : <C3><BC> et <C3><9C>
- On trouve assez souvent dans les textes, notamment en poésie, le "a accent circonflexe"
qui est sorti de l'usage officiel (ce qui est un grave inconvénient pour l'étranger,
car il a une prononciation spéciale : il mouille la consonne qui le précède)
minuscule â Unicode n° 226 = x00E2 LATIN SMALL LETTER A WITH CIRCUMFLEX
majuscule  Unicode n° 194 = x00C2 LATIN CAPITAL LETTER A WITH CIRCUMFLEX
En UTF-8 : <C3><BC> et <C3><9C>
- le "c cédille" (le même qu'en français), qui note l'affriquée sourde 'tch'
- J'ai trouvé il y a plusieurs années une police de caractères dite international (bitmap, pour Macintosh)
permettant d'obtenir ces caractères sous Word par le procédé suivant :
- Le "i" sans point minuscule : taper ^ puis espace : garı
- Le "i" majuscule avec point : taper opt-shift-x après le "I" : İzmir
-
Le "g mou" : taper opt-u après le "g" : oğlan
- pour la majuscule, taper opt-$ après le "G" : OĞLAN
- pour la majuscule, taper opt-$ après le "G" : OĞLAN
- Le "c" et le "s" cédille : taper opt-< après la lettre : çicek, Çicek, paşa, PAŞA
- Le tréma sur le "o" et sur le "u": en minuscule, opt-shift-t après la lettre : Ben yürürüm yana yana
- en majuscule, opt-shift-r après la lettre : Ödemiş, Turgut Özal
- en majuscule, opt-shift-r après la lettre : Ödemiş, Turgut Özal
- L'accent circonflexe sur le a : minuscule à la place du § : hikâyet
majuscule opt-shift-g : Âram
- Le "i" sans point minuscule : taper ^ puis espace : garı
- J'ai donc dans mes archives une collection de documents réalisés avec cette technique,
contenant des textes turcs annotés en français.
Les lettres turques y sont "codées" comme expliqué ci-dessus, avec la police international
et le logiciel de visualisation (en l'occurrence Word) interprète ce codage avec cette police
de manière à restituer les glyphes attendus.
-
Le but est de transformer ces fichiers en pages Web bilingues, uniformément codées en UTF-8.
Exemple : une anecdote de Nasreddin Hodja
Dans un premier temps, on ne cherchera pas à traduire la mise en forme (italiques, caractères gras, etc)
mais seulement le codage des caractères.
Exemple : le fichier Izmir.doc montré ci-dessous dans sa fenêtre Word d'origine :
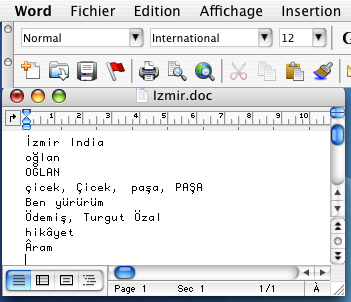
sauvegardé par Word en "texte seulement" devient Izmir.txt, codé en MacRoman :
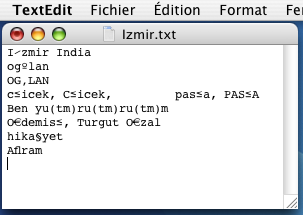
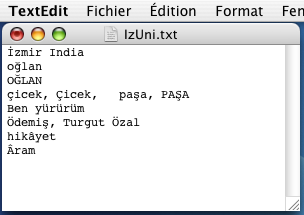
Solution
- Observation (faite avec l'irremplaçable outil hexdump) :
Dans le fichier Word sauvegardé en texte pur, les lettres turques spéciales apparaissent sous deux formes :
- Le "i sans point", qui est simplement l'interprétation que fait la police international
du caractère '^', ASCII 094 - 0x5E.
Ce caractère n'ayant aucune raison d'apparaître dans les textes qui nous intéressent,
il suffira de le traduire par Unicode n°305 à chaque occurrence. - Dans tous les autres cas, comme des lettres ASCII suivies d'un octet "diacritique" non ambigu,
appartenant à l'intervalle [128, 255], à savoir :
- Le "i" majuscule avec point : 'I' suivi de DA
-
Le "g mou" minuscule : 'g' + BC
-
Le "g mou" majuscule : 'G' + E2
- Le "c" et le "s" cédille ( maj. & min.) : la lettre suivie de B2
- Voyelles minuscules avec tréma : la lettre suivie de "(tm)"
curieux... est-ce un artefact de l'environnement Mac ?
- Voyelles majuscules avec tréma : la lettre suivie de DB
- a circonflexe minuscule : 'a'+ A4
- a circonflexe majuscule : 'A' + DF
- Le "i" majuscule avec point : 'I' suivi de DA
- Le "i sans point", qui est simplement l'interprétation que fait la police international
- Principe : (en C)
lire le fichier octet par octet et
- laisser intacts les caractères ASCII
- décoder les constructions turques ci-dessus en les traduisant en Unicode
- laisser intacts les caractères ASCII
-
La difficulté vient des "non-constructions" !
Lorsqu'on trouve un caractère qui peut être suivi d'un octet diacritique, il faut lire cet octet.
Si c'est bien le diacritique attendu (il y en a un seul dans chaque cas), on envoie en sortie
les deux octets UTF-8 idoines, et tout va bien.
Sinon ? On renvoie en sortie les deux caractères, mais... on a perdu une information !
Par exemple, dans Izmir.txt, quand on traite 'paşa', c'est-à-dire 'pas≤a',
la recherche de l'accent circonflexe après le 'a' nous fait "consommer" le 's'.
Envoyer en sortie les deux caractères 'as' ne suffit pas, car le 's' ainsi consommé
aurait dû être l'objet d'une investigation sur la présence d'un diacritique le suivant !
Que faire ? Les choses se compliquent !
Heureusement pour nous, il existe en C (dans stdio.h) une fonction ungetc qui permet
de replacer un caractère lu dans le flot d'entrée. Ouf !
- Réalisation (fichier tradTurc.c)
Voici le début de l'énumération des 14 constructions.
On écrit les valeurs d'octets en hexadécimal, forme sous laquelle on les trouve dans les sources
(documentation, hexdump).
while ((val=fgetc(fentr)) !=EOF) {
switch( val ){
case '\r':{ /* saut de ligne Mac */
fputc( '\n', fsort); /* id. Unix */
break;
}
case '^' :{ /* i sans point */
fputc(0xc4, fsort);
fputc(0xb1, fsort);
break;
}
case 'I' :{ /* avec point ? */
val1 = valoct(fgetc(fentr));
if( val1 == 0xda ){ /* oui */
fputc(0xc4, fsort);
fputc(0xb0, fsort);
}else{
ungetc(val1, fentr);
fputc('I', fsort);
}
break;
}
case 'g' :{ /* yumushak ? */
val1 = valoct(fgetc(fentr));
if( val1 == 0xbc ){ /* oui */
fputc(0xc4, fsort);
fputc(0x9f, fsort);
}else{
ungetc(val1, fentr);
fputc('g', fsort);
}
break;
}
... etc ...
default :
fputc(val, fsort);
}/* switch */
}/* while */
ce n'est qu'une routine fastidieuse...
Voici un exemple complet : à partir du fichier Word que voici (fichier MoiNH.doc),
relatif à un poème célèbre de Nazım Hikmet
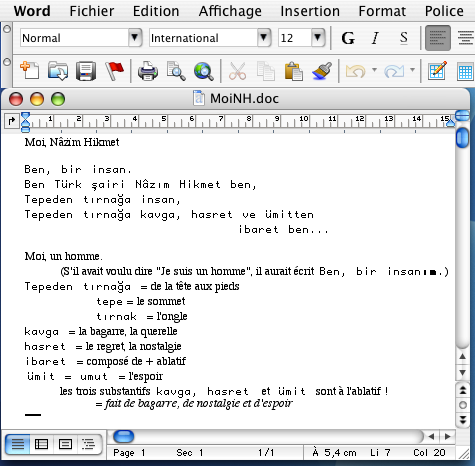
en le sauvegardant en "texte seulement" (fichier MoiNH.txt) et en lui appliquant notre programme,
on obtient le texte UTF-8 suivant (fichier MoiNHU.txt) :
Dans l'affaire, on a perdu la différentiation opérée par les deux polices, les caractères gras, les italiques,
bref toute la mise en forme, mais on récupéré intégralement le texte...
on obtient le texte UTF-8 suivant (fichier MoiNHU.txt) :
Moi, Nâzïm Hikmet
Ben, bir insan.
Ben Türk şairi Nâzım Hikmet ben,
Tepeden tırnağa insan,
Tepeden tırnağa kavga, hasret ve ümitten
ibaret ben...
Moi, un homme.
(S'il avait voulu dire "Je suis un homme", il aurait écrit Ben, bir insanım.)
Tepeden tırnağa = de la tête aux pieds
tepe = le sommet
tırnak = l'ongle
kavga = la bagarre, la querelle
hasret = le regret, la nostalgie
ibaret = composé de + ablatif
ümit = umut = l'espoir
les trois substantifs kavga, hasret et ümit sont à l'ablatif !
= fait de bagarre, de nostalgie et d'espoir
Dans l'affaire, on a perdu la différentiation opérée par les deux polices, les caractères gras, les italiques,
bref toute la mise en forme, mais on récupéré intégralement le texte...